






袋装(Bagging)
基本思想
对原训练数据集采用随机有放回抽样的方法选择子数据集从而构造组合分类器。
给定含有n个样本的数据集合D, 袋装在构造指定的T个基础模型(以基分类器为例)的基本过程:
- 对D进行采样,得到若干个大小相同子数据集Di(i=1,2, …, T),Di中可能包含重复样本(因为对每个Di采用的是有放回抽样得到的);
- 分别在每个样本集合Di上训练一个模型;
- T个基分类器分别预测,用投票法输出最终预测结果。
算法流程
注:这里描述的数据集和子数据集不是数学上满足唯一性的集合(集合中的元素唯一)

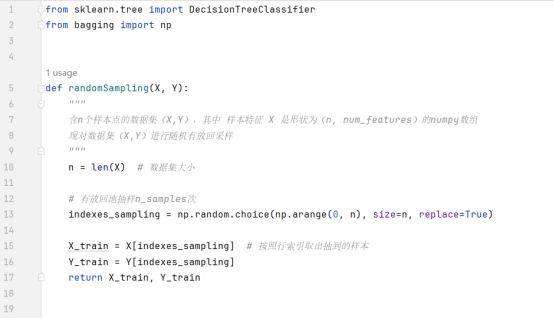
上述流程的核心步骤之一:对D有放回抽样创建自助样本集Di
更一般的方法:考虑指定的每个子数据集的大小占原数据集大小的比例ratio_samples, 以及每个样本的特征数量占原特征数量的比例ratio_features. 设原数据集D的大小为n, 每个样本的特征数量为m(即D的形状为(n, m)),则抽样得到的数据集Di的大小为n * ratio_samples, 每个样本的特征数量为m*ratio_features.
基础分类实验
bagging.py
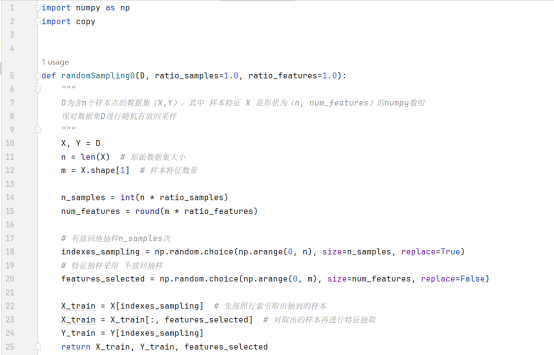
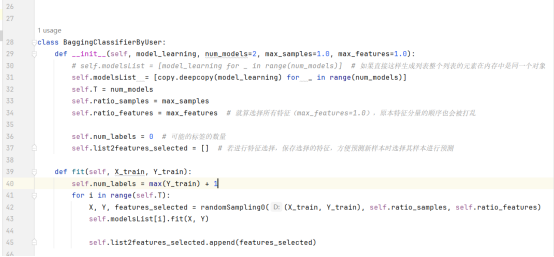
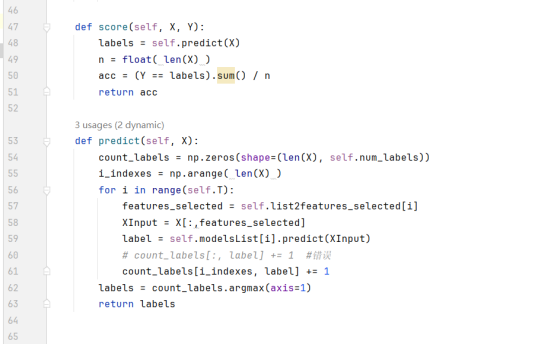
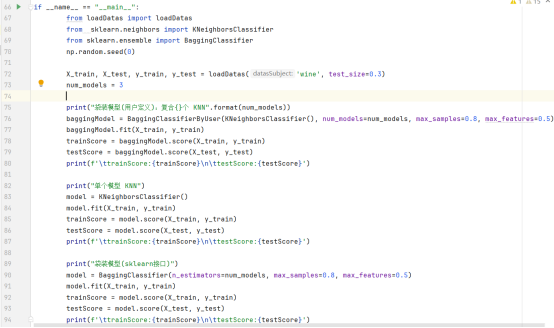
Bagging方法中,训练样本划分规则:随机80%的数据样本和50%的属性

运行结果—以复合、单个KNN为例
随机森林
基本思想
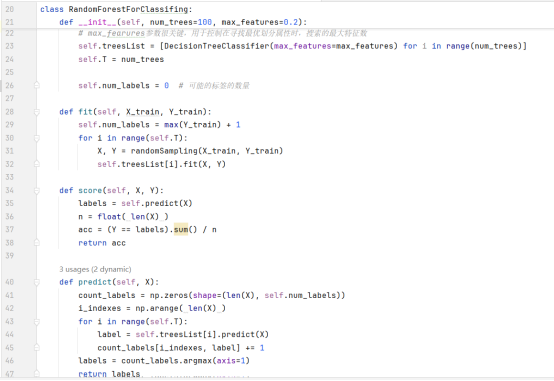
可以看作袋装(Bagging)模型的一个特例,或者说原理类似,随机森林的基本单元是决策树。随机森林利用多个决策树进行训练、分类(或回归)并预测,分类时,每棵树都投票并且返回票最多的类。
一般来说,袋装(Bagging)的做法是在不同的样本集合上使用所有的属性训练若干个基础模型;而随机森林则是在Bagging采样得到的样本集合的基础上,随机从中挑选出k个属性再组成新的数据集,之后再训练对应的决策树;总之,随机森林在引入样本扰动的基础上再引入属性的扰动,“森林”中的每棵树的差异会尽可能的大,这样集成的随机森林模型不易过拟合,泛化能力好。
基础分类实验
randomForest.py

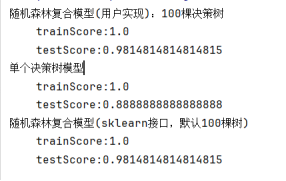
运行结果
提升(Boosting)
基本思想
Boosting可以看作是Bagging的一个改进,它在训练的每个基础学习器的过程中,会对样本集合中的样本权重或概率分布进行不断的调整,着重考虑被学习器错误分类的样本。
具体的,在Boosting方法中:
- 首先给每个训练样本赋予一个初始权重;
- 在迭代学习T个基分类器的过程中,学习得到分类器Mi后,更新训练样本的权重,使其后的分类器更关注Mi误分类的训练样本;
- 最终提升的复合分类器M*组合每个基分类器的投票,其中每个分类器投票的权重是其准确率的函数。
AdaBoost(Adaptive Boosting,自适应增强)算法是一种基于Boosting策略的集成学习算法,它通过组合多个弱分类器来构建一个强分类器。
给定含有n个具有类标号的数据集合D={( X1,Y1),( X2,Y2), …, (Xn,Yn)}。起始时,AdaBoost给每个训练元组赋予相等的权重1/n,迭代T轮产生组合分类器:在第i轮,从D中进行有放回抽样形成大小为n为训练集Di(每个元组被选中的概率由其权重决定)。从Di得到分类器Mi,然后使用Di作为检验集计算Mi的误差。训练元组的权重根据它们的分类情况调整(分类错误则权重增加,权重反映了它们对分类的困难程度),然后进入下一轮迭代。
AdaBoost算法流程

AdaBoost是常用到的提升算法,其描述如下:
拓展了解——提升树
基础模型为决策树的Boosting算法称为提升树(通常以CART决策树为主)。
典型的提升树算法:残差提升树、梯度提升树(GBDT)、XGBoost.
1. 残差提升树
残差提升树(Residual Boosting Trees)是一种通过迭代拟合残差来逐步提升模型预测精度的算法,残差
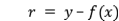
,其中y为训练样本(x, y)的真实目标值,f(x)为模型预测值。
基本思想是在每一轮迭代中,用当前的弱学习器去拟合前一轮学习后的残差,然后将拟合得到的模型加到前一轮的模型上,形成新的模型。这个过程重复进行,直到满足停止条件(如残差小于某个阈值或达到预设的迭代次数)。残差提升树的核心在于通过不断修正残差来逼近真实目标值。
2. 梯度提升树(GBDT)
梯度提升树(Gradient Boosting Decision Tree, GBDT)与残差提升树类似,也是通过迭代地拟合残差来改进模型,但不同的是,GBDT使用了梯度下降的思想来优化损失函数。
在GBDT中,每一轮迭代时,都会计算当前模型的损失函数关于预测值的梯度(或称为伪残差),然后利用这个梯度信息去训练一个新的决策树模型,并将这个新模型加到前一轮的模型上。这样,通过多轮迭代,GBDT能够逐步减小损失函数的值,从而得到更好的预测模型。GBDT支持多种损失函数,如平方损失、绝对损失、Huber损失等,以适应不同的应用场景。
3. XGBoost
XGBoost(eXtreme Gradient Boosting)是GBDT算法的一种高效实现,它在GBDT的基础上进行了多项优化和改进。XGBoost使用了二阶泰勒展开来近似损失函数,以在优化过程中的计算更加精确和高效。同时,XGBoost还引入了正则化项来控制模型的复杂度,避免过拟合。此外,XGBoost还采用了稀疏感知算法和列抽样等技术来加速训练和提高模型的泛化能力。
XGBoost支持多种类型的数据输入和输出,包括分类、回归、排序等任务。它还在工业界和学术界得到了广泛的应用和认可,被认为是目前最强大的集成学习算法之一。
注:关注微信公众号——分享之心,后台回复“机器学习基础实验”获取完整代码和相关文档资料的地址(不断更新)。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









