







一、集成学习算法简介
1、什么是集成学习
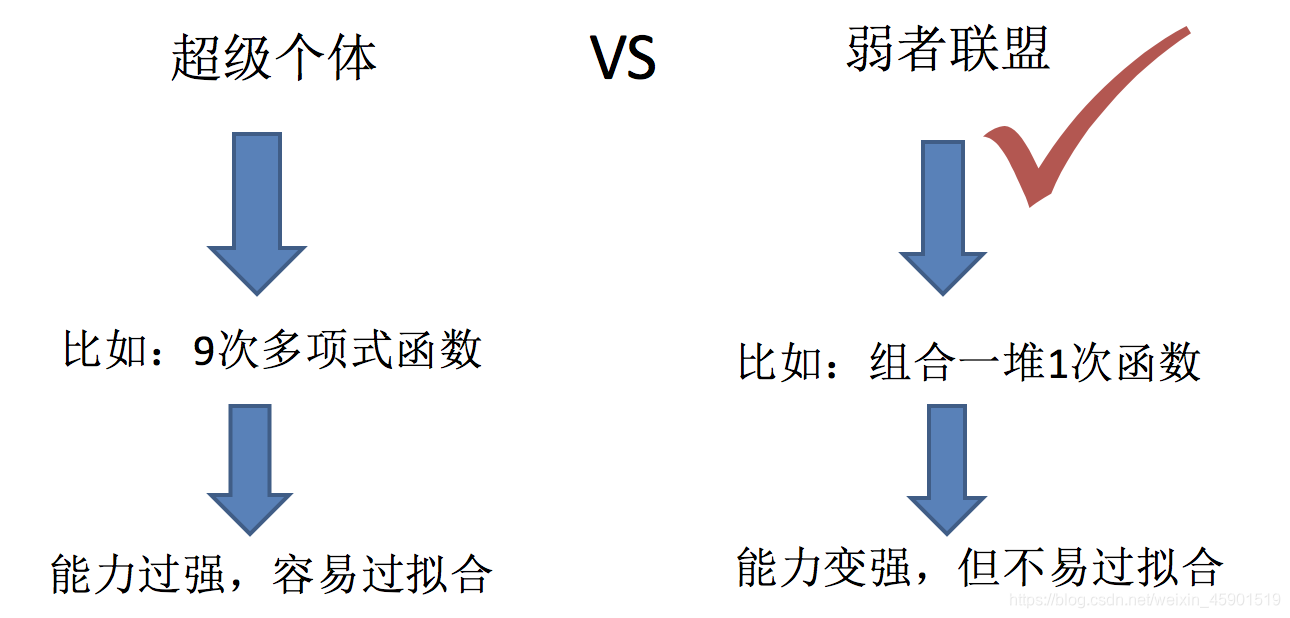
集成学习通过建立几个模型来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
2、机器学习的两个核心任务
- 任务一:如何优化训练数据 —> 主要用于解决欠拟合问题
- 任务二:如何提升泛化性能 —> 主要用于解决过拟合问题
3、集成学习中boosting和Bagging
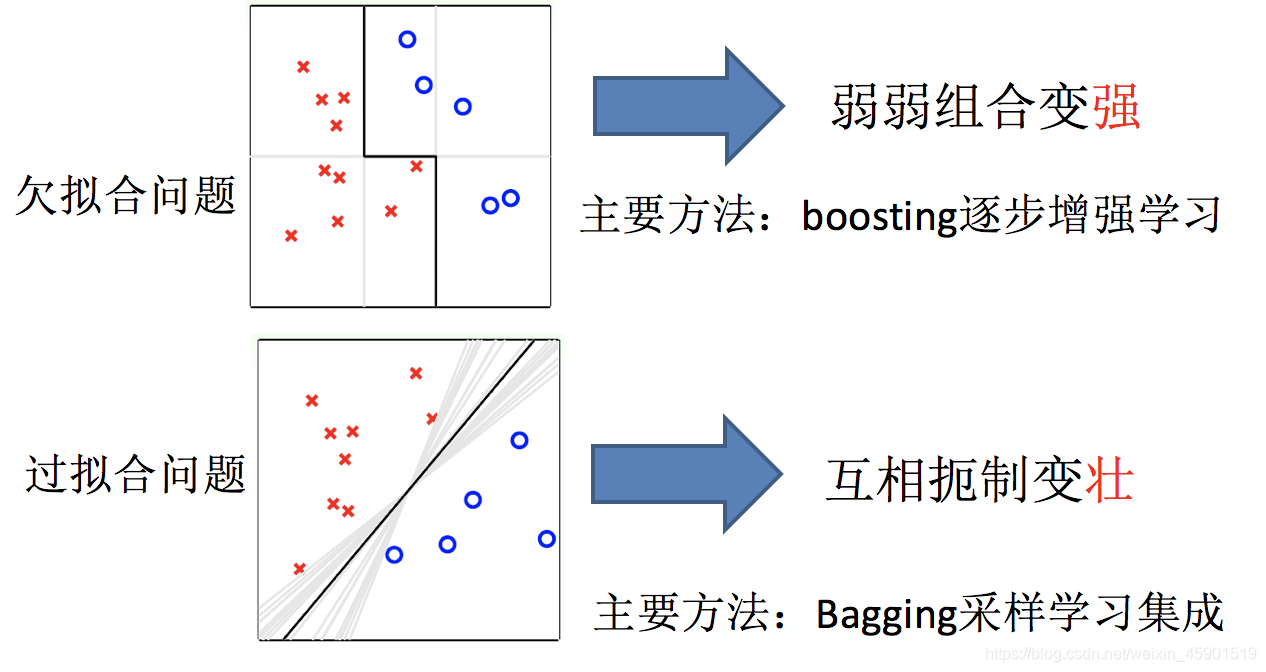
只要单分类器的表现不太差,集成学习的结果总是要好于单分类器的
4、小结
- 什么是集成学习
- 通过建立几个模型来解决单一预测问题
- 机器学习两个核心任务
- 1.解决欠拟合问题
弱弱组合变强
boosting - 2.解决过拟合问题
互相遏制变壮
Bagging
- 1.解决欠拟合问题
二、Bagging和随机森林
1、Bagging集成原理
目标:把下面的圈和方块进行分类
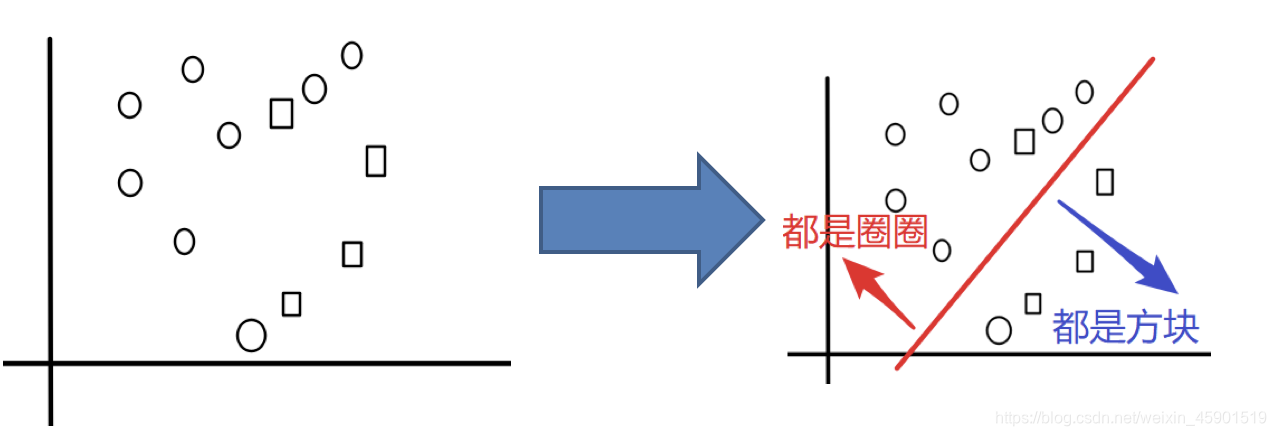
实现过程:
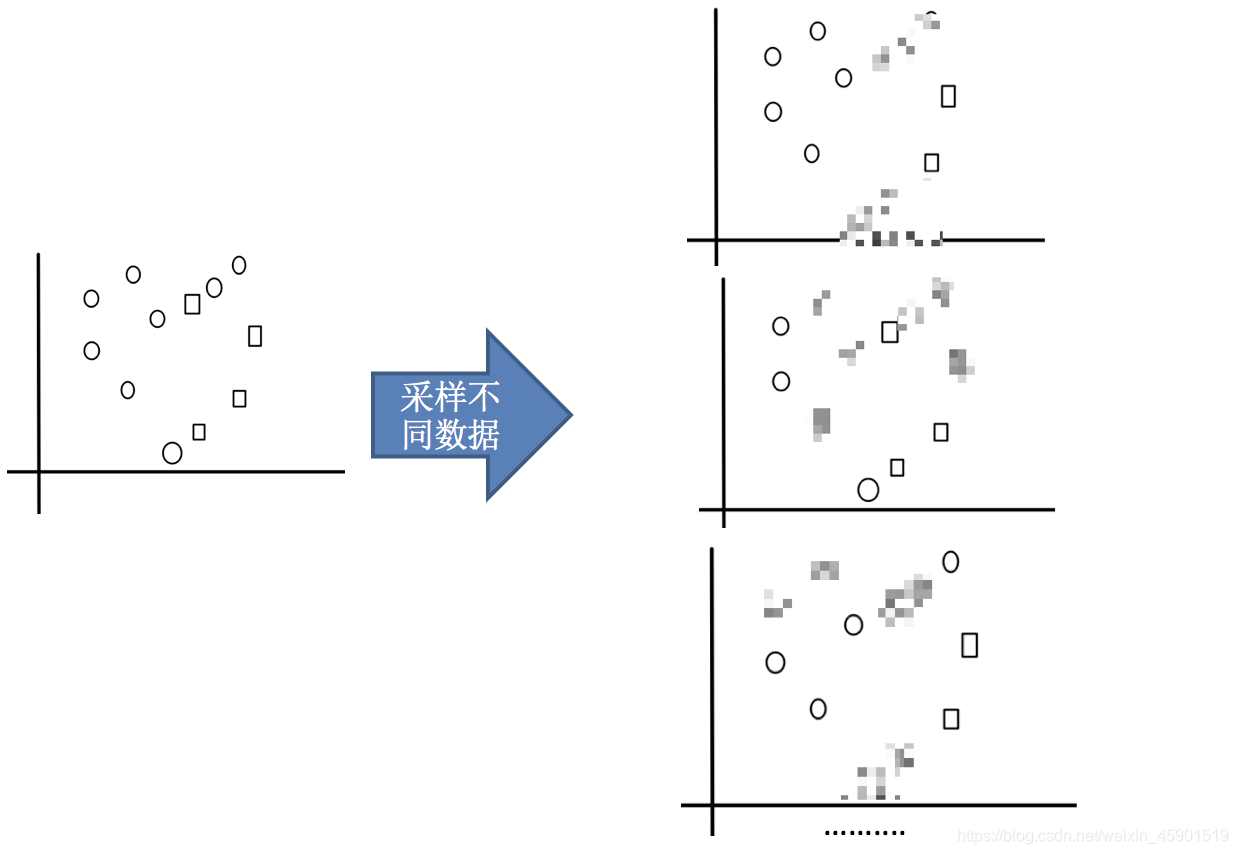
- 1.采样不同数据集
- 2.训练分类器
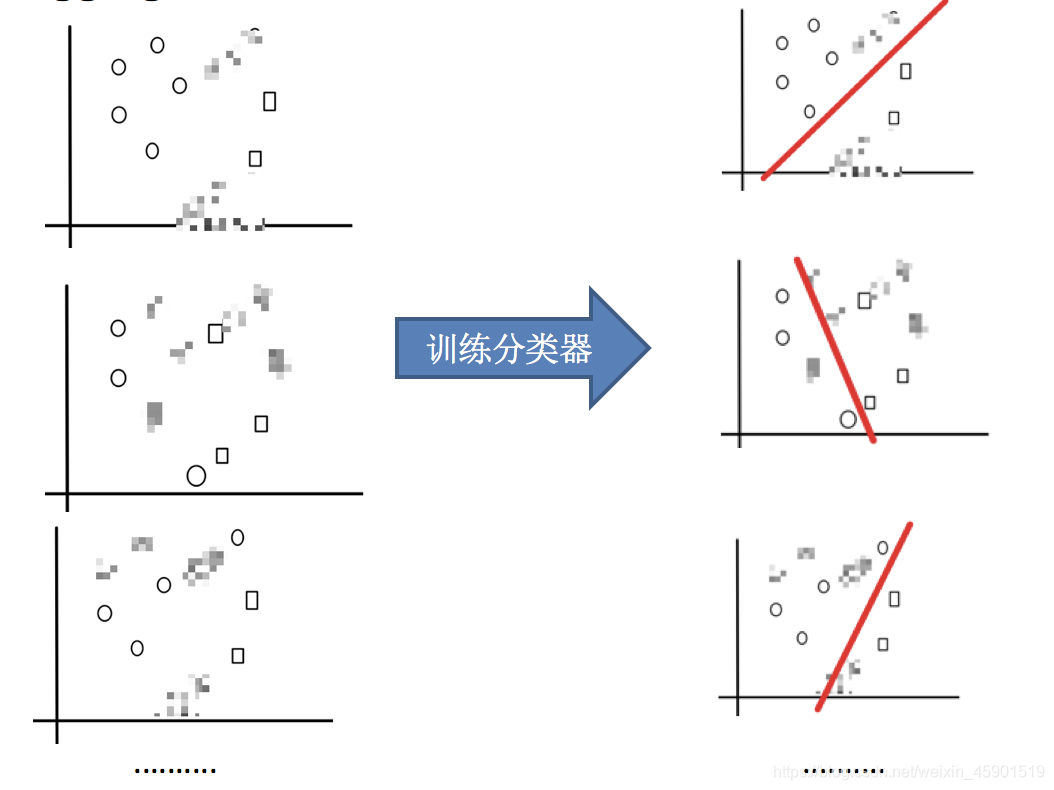
- 3.平权投票,获取最终结果
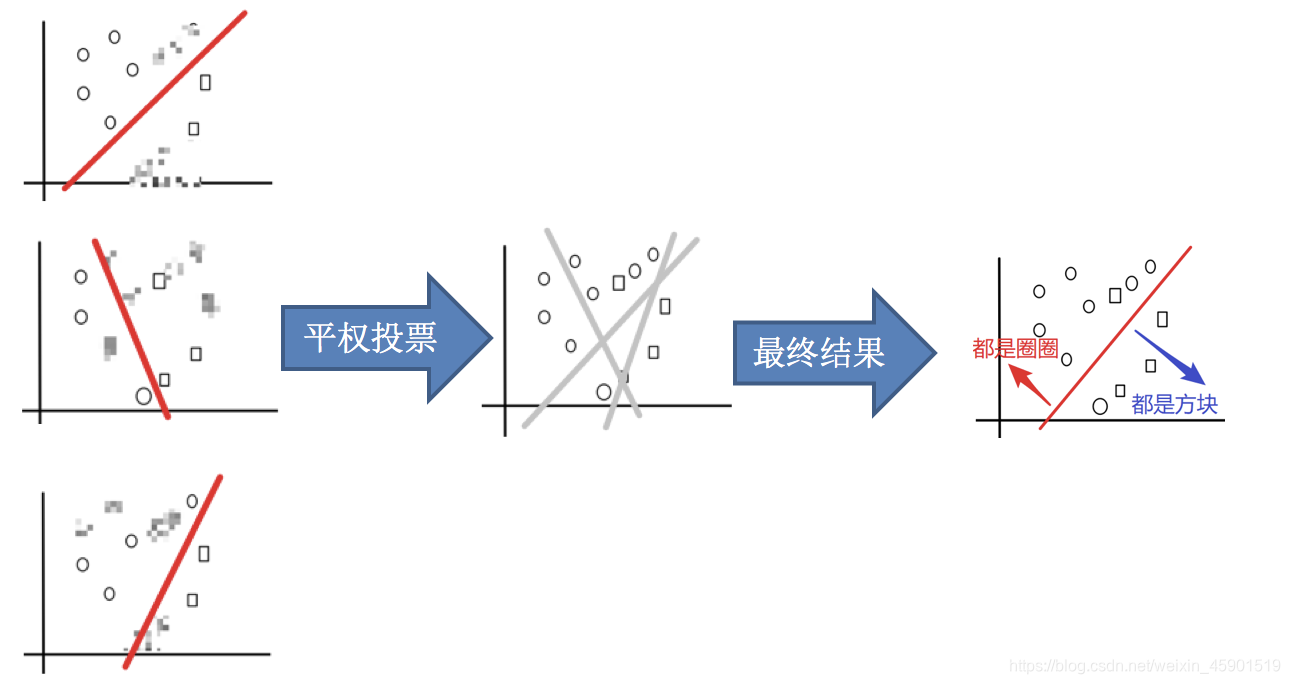
主要实现过程:
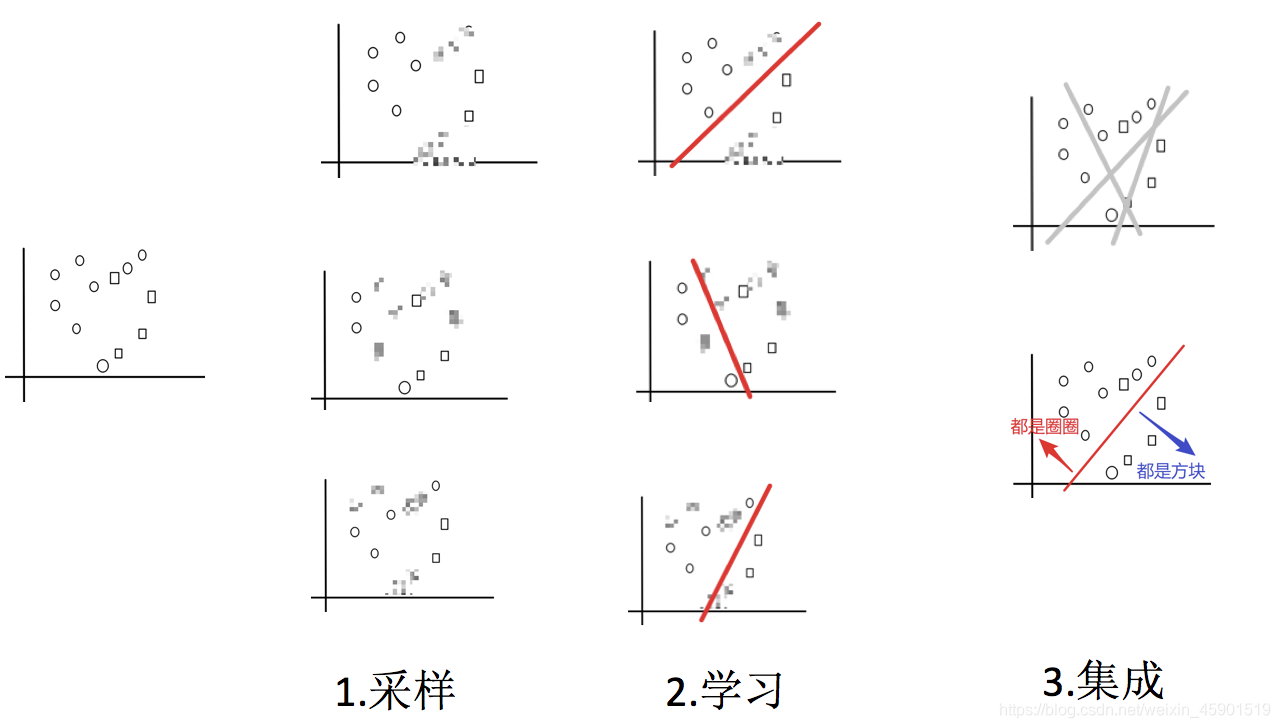
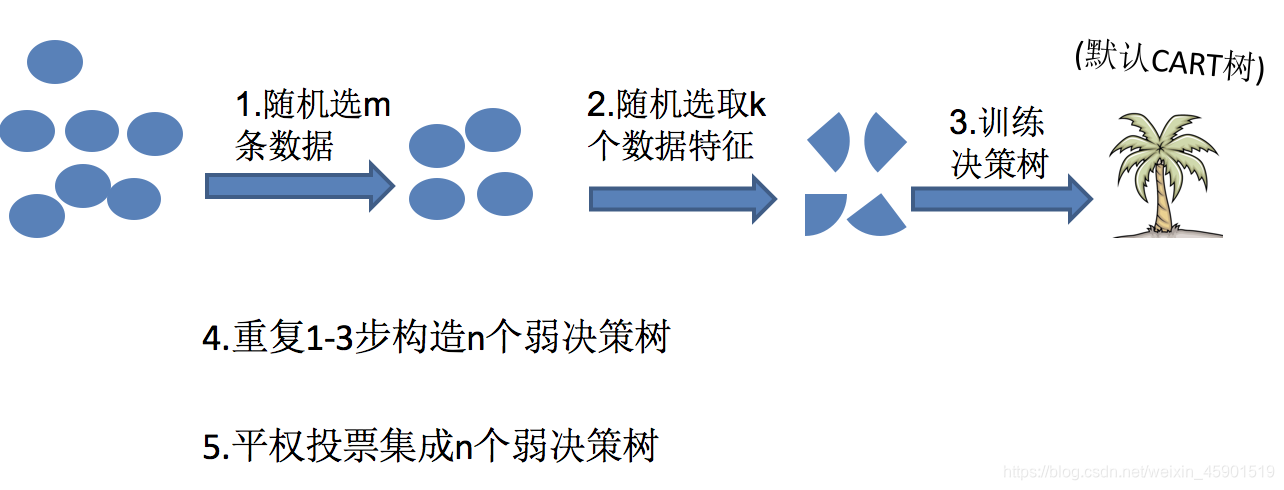
2、随机森林构造过程
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
随机森林 = Bagging + 决策树
例如, 如果你训练了5个树, 其中有4个树的结果是True, 1个树的结果是False, 那么最终投票结果就是True
随机森林构造过程中的关键步骤(M表示特征数目):
1)一次随机选出一个样本,有放回的抽样,重复N次(有可能出现重复的样本)
2) 随机去选出m个特征, m <<M,建立决策树
思考:
- 1.为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的 - 2.为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
3、随机森林api介绍
sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’,
max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
参数:
n_estimators:integer,optional(default = 10)森林里的树木数量120,200,300,500,800,1200Criterion:string,可选(default =“gini”)分割特征的测量方法max_depth:integer或None,可选(默认=无)树的最大深度 5,8,15,25,30max_features="auto”,每个决策树的最大特征数量- If “auto”, then max_features=sqrt(n_features).
- If “sqrt”, then max_features=sqrt(n_features)(same as “auto”).
- If “log2”, then max_features=log2(n_features).
- If None, then max_features=n_features.
bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样min_samples_split:节点划分最少样本数min_samples_leaf:叶子节点的最小样本数
超参数为:n_estimator, max_depth, min_samples_split,min_samples_leaf
4、随机森林预测案例
4.1、案例背景
泰坦尼克号沉没是历史上最臭名昭着的沉船之一。1912年4月15日,在她的处女航中,泰坦尼克号在与冰山相撞后沉没,在2224名乘客和机组人员中造成1502人死亡。这场耸人听闻的悲剧震惊了国际社会,并为船舶制定了更好的安全规定。 造成海难失事的原因之一是乘客和机组人员没有足够的救生艇。尽管幸存下沉有一些运气因素,但有些人比其他人更容易生存,例如妇女,儿童和上流社会。 在这个案例中,我们要求您完成对哪些人可能存活的分析。特别是,我们要求您运用机器学习工具来预测哪些乘客幸免于悲剧。
案例:https://www.kaggle.com/c/titanic/overview
我们提取到的数据集中的特征包括票的类别,是否存活,乘坐班次,年龄,登陆home.dest,房间,船和性别等。
数据:https://www.kaggle.com/c/titanic/data.去这里把训练集和测试集下载下来(我只用到了训练集,也就是把这个训练集划分成了train和test)。

经过观察数据得到:
-
1 乘坐班是指乘客班(1,2,3),是社会经济阶层的代表。
-
2 其中age数据存在缺失。
4.2、步骤分析
- 1.获取数据
- 2.数据基本处理
- 2.1 确定特征值,目标值
- 2.2 缺失值处理
- 2.3 数据集划分
- 3.特征工程(字典特征抽取)
- 4.机器学习(决策树)
- 5.模型评估
4.3、代码实现
- 导入需要的模块
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.feature_extraction import DictVectorizer
from sklearn.ensemble import RandomForestClassifier
- 1.获取数据
# 1、获取数据
titan = pd.read_csv("data/train.csv") # 数据我从官网下载下来了
-
2.数据基本处理
-
2.1 确定特征值,目标值
x = titan[["pclass", "age", "sex"]]
y = titan["survived"]
- 2.2 缺失值处理
# 缺失值需要处理,将特征当中有类别的这些特征进行字典特征抽取
x['age'].fillna(x['age' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 8354
8354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









