







?2021年寒假Stata研讨班:高级计量经济学及Stata应用研讨班
?2021空间计量研讨班:空间计量及Geoda、Stata、ArcGis、Matlab应用
一.命令介绍
偏差校正倾向得分匹配方法对应命令为:nnmatch
语法格式为:
nnmatch depvar treatvar varlist_nnmatch [if exp] [in range] [pw] [, tc(ate |att |atc) m(#) metric(maha |matname) exact(varlist_ex) biasadj(bias |varlist_adj) robust(#_v) population level(#) keep(filename) replace]
详细解释为:
depvar :结果变量
treatvar:处理变量
varlist_nnmatch :匹配变量
tc(ate|att|atc) specifies which treatment effect is to be estimated:
ate: the average treatment effect,
att: the average treatment effect for the treated, or
atc: the average treatment effect for the controls.
metric(maha |matname) :metric(maha)表示使用马氏距离,即权重矩阵为样本协方差矩阵的逆矩阵
m(#) :进行#近邻匹配,默认#=1。
robust(#_v):表示进行异方差稳健的标准误
Example:
nnmatch y t x1 x2
nnmatch y t x1, m(3)
nnmatch y t x1 x2, tc(att)
nnmatch y t x1 x2, tc(atc) met(maha) bias(bias) robust(4)
nnmatch y t x1 x2, met(matname) bias(x1 x3) keep(artdata) replace
nnmatch y t x1 x2 [w=w], met(matname) bias(x1 x3) exact(x4) pop
二.偏差校正匹配估计量操作应用
本文仍然使用倾向得分匹配所对应的案例数据,所对应的变量数据结构为:
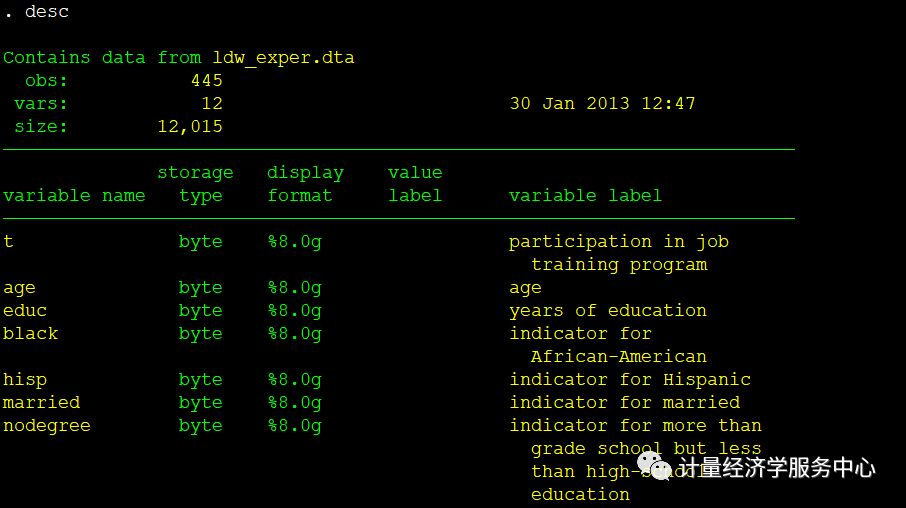
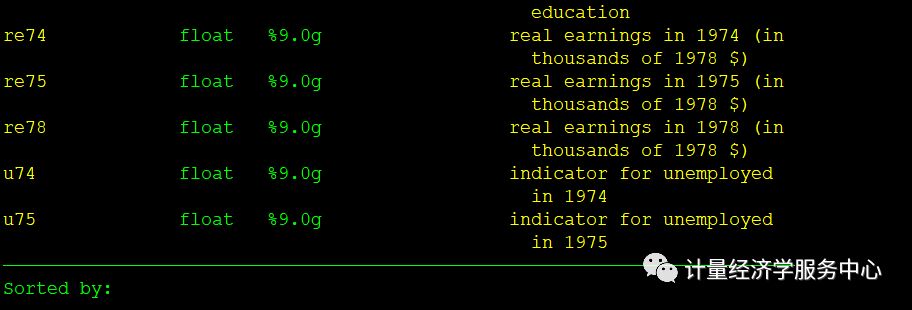
首先使用一对一的匹配,不做偏差校正,但是进行稳健标准误估计:
nnmatch re78 t age edu black his married re74 re75 u74 u75, tc(atc) m(1) robust(1)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2165
2165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









