







01. 倾向得分匹配方法
1.数据来源
来源:网络资源,其实也比较容易找,比如人大经济论坛。但为了避免相关的版权争议,我重新写了一个do文件,处理的方法和变量也有改变。
举例:接受培训对于工资的影响
分析思路:(1)验证选择性的存在;(2)倾向值打分;(3)匹配估计量
两种方法:pscore;psmatch2
所选用数据:国家支持工作示范项目(National Supported Work,NSW)
2.原理
需要估计的内容:处理效应,Treatment Effect
评估某项目或政策实施后的效应,如政策推出的各种项目,此类研究被称之为项目效应评估,也被称之为处理效应,项目参与者的全体构成控制组或对照组,而未参加项目者则构成控制组或对照组。即y1i-y0i。
选择性偏误:
由于个体通常会根据其参加项目的预期收益E(y1i-y0i)而自我选择是否参加项目,导致对平均处理效应的估计带来困难。
两大假定:
可忽略性:给定xi,则(y0i,y1i)独立于Di
均值可忽略性:在给定xi的情况下, y0i和y1i都均值独立于Di
匹配估计量的基本思路:
找到属于控制组的某个体j使得其与属于处理组的个体i的可测变量取值尽可能相似,即xi ≈xj。
基于可忽略性假设,则个体i与个体j进入处理组的概率相近,具有可比性,故可将yj作为y0i的估计量。
目标:
在一般的实证研究中,由于存在很多其他变量混淆自变量和因变量之间的关系,研究者很难直接探索二者之间的净效果( net effects)。这些混淆变量的影响通常被称为选择性误差( selectionbias) , 而通过倾向值匹配的方式来控制和消除选择性误差
3.实操
变量:
变量 |
定义 |
treat |
接受培训(处理组)表示1,没有接受培训(控制组)表示0 |
age |
年龄 |
educ |
受教育年数 |
black |
虚拟变量,black=1 |
hsip |
虚拟变量,hsip=1 |
marr |
婚姻状况虚拟变量,已婚,marr=1 |
re74 |
1974年实际工资 |
re75 |
1975年实际工资 |
re78 |
1978年实际工资 |
u74 |
当在1974年失业,u74=1 |
agesq |
age*age |
educsq |
educ*educ |
re74sq |
re74*re74 |
re75sq |
re75*re75 |
u74blcak |
u74*blcak |
(1)检验选择性的存在
**--基本命令--**
cd: work_file_path...
use nswpsid.dta,clear
browse
rename _all,lower
*我手头的数据变量名全部为大写,便于观察,我统一修改为小写
reg re78 treat age educ black hisp marr re74 re75 agesq educsq nodegree re74sq re75sq u74black u74hisp
reg re78 treat下图中,treat效果并不显著。大量的自变量的存在也导致了一定的共线性问题,也就是说,其他变量稀释了treat变量解释的方差。
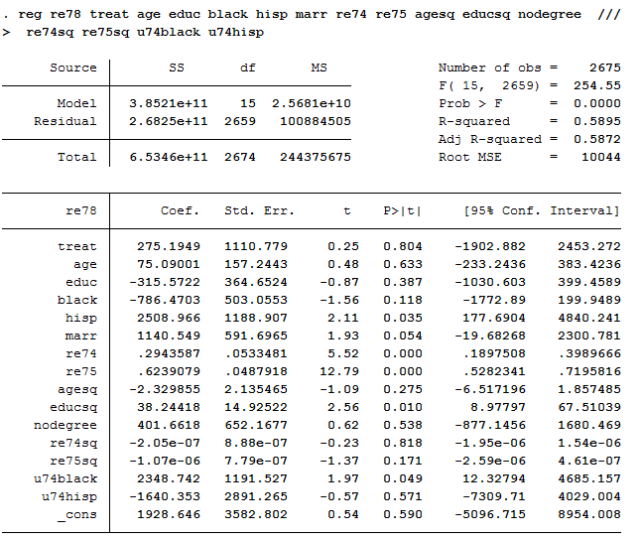
下图显示,treat显著,说明是存在选择性问题的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4562
4562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









