






本文从多模态大模型这一全新的视角来思考SFDA问题,首次探索了现成的视觉--语言多模态模型(ViL, 具有丰富异构知识)的辅助迁移潜力。
论文题目:《Source-Free Domain Adaptation with Frozen Multimodal Foundation Model》
arxiv地址:https://arxiv.org/abs/2311.16510v3
开源代码:https://github.com/tntek/source-free-domain-adaptation(我们写了一个Soure-free Domain Adaptation的通用框架,非常欢迎大家添加自己的方法!)
Abstract
无源域适应 (SFDA)是无监督领域自适应问题(UDA)的一个新分支,本质是将一个在源领域预训练好的模型迁移到另一个没有标签信息的目标领域,在迁移过程中,源领域是不可见的。针对该问题,目前的主流方法是构建伪标签或者挖掘辅助信息,来监督迁移过程,以实现领域自适应。但是,在无监督约束下,这种策略会不可避免地引入语义错误,从而限制迁移性能。在本文中,我们从多模态大模型这一全新的视角来思考SFDA问题,首次探索了现成的视觉--语言多模态模型(ViL, 具有丰富异构知识)的辅助迁移潜力。在运用ViL模型解决下游任务的过程中,我们发现以零样本方式直接将基础大模型应用于目标域并不令人满意,因为它所蕴含的知识是通用的,而不是都适用于特定任务。
以此为逻辑基点, 我们提出了一种迁移多模态基础模型所蕴含通用知识的SFDA方法(简称DIFO)。具体来说,DIFO对应的的迁移过程由两个交替步骤构成:(1)通过提示学习最大化与目标模型的互信息来定制化多模态基础模型,然后,(2)将这个定制好的多模态知识提炼到目标模型。为了更细粒度、更可靠进行知识迁移, 我们还引入了两个有效的正则化设计,即最可能类别约束,以及预测一致性约束。我们在四个开源的挑战性数据集上测试了DIFO的性能。实验结果表明DIFO明显优于现有方法。
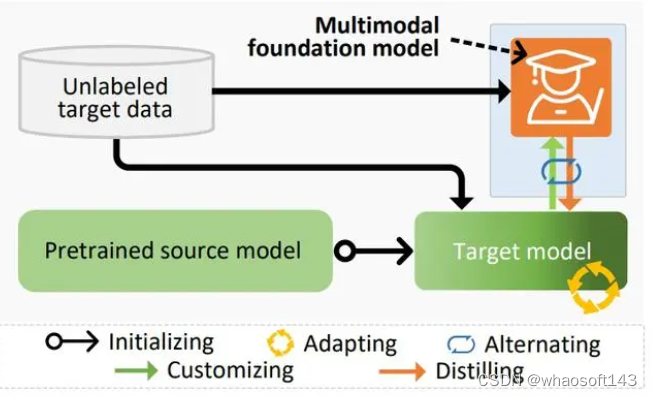
Contributions
- 首次利用通用但异构的知识源(例如现成的ViL模型)来解决SFDA问题,超越了源域模型与无标注目标数据所表达的有限知识边界;
- 提出了新颖的DIFO方法,从通用ViL模型中有效地提取有用的特定任务知识;
- DIFO在经典的closed-set setting,以及更具挑战性partial-set 和open-set settings下取得 SOTA性能。
Methodology
1.Problem statement

2.Overview
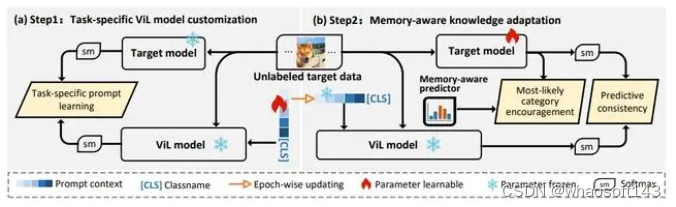
DIFO框架在两个不同的步骤之间交替来定制和提炼现成的ViL模型的知识
第一步,我们使用prompt learning实现ViL模型面向特定任务的定制化,从而减轻了 ViL 模型中的引导误差。为实现该目的,我们采用基于互信息的协调方法加以实现。相比于传统的KL散度、MMD等量度,这种方法最大的特点是提高了目标域模型和 ViL 模型之间上下文的交互丰富性,而不是盲目地信任的任何一个模型。第二步, 为了实现通用知识可靠的迁移,我们引入了最可能类别约束和预测一致性约束,这些约束使得目标域模型能够在logit空间中识别出最可能的类别标签,等价地引入类别显然分布,同时保持目标模型和ViL 模型的预测一致性,来实现小尺度的精细分类。在这里,最可能类别标签是由记忆感知预测器给出,该预测器以累积的方式动态存储并更新来自目标模型和 ViL 模型的知识。
3.Task-Specific ViL Model Customization(特定任务的 ViL 模型定制)
我们采用prompt learning 的框架进行ViL模型定制化,在此过程中,ViL模型的所有参数全部冻结,唯一可学习的部分是为特定任务分配的 text prompt。为了优化这些 prompt,我们需要有效的监督,然而,在SFDA问题设定中,由于缺乏有监督训练的参考模型,这意味着没有明确的良好监督信号可供使用。为了解决这个问题,受群体学习的思想启发,我们将ViL模型和目标域模型的输出看作两堆具有智慧的群体,用它们之间的互动与交流,作为弱监督信号,来实现无偏学习。具体来讲,我们通过最大化他们的预测的互信息来实现模型定制,其具有如下形式:

4. Memory-Aware Knowledge Adaptation(记忆感知知识适应)
虽然将ViL模型向目标模型进行了定制,但由于之前没有可靠目标模型,ViL 模型也可能无法完全适应。这种限制阻碍了第二阶段有效的知识迁移。为了解决这个问题,我们提出一个专用的记忆感知预测器来提供额外的学习指导即最有可能的类别鼓励,并结合传统的预测一致性约束,从未实现了一种可靠的、从粗粒度到细粒度的分类。
4.1 Memory-aware predictor(记忆感知预测器)
(1)记忆感知预测器

(2)类别注意力校准
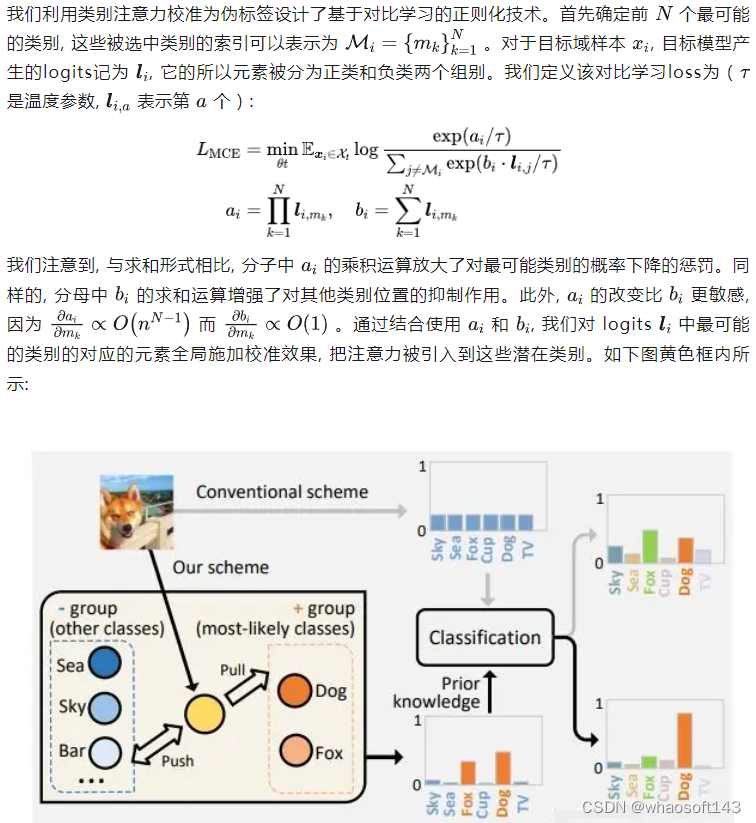
5. Predictive Consistency(预测的一致性)
预测一致性损失为:

Model training(模型训练)


Experiments
在我们的实验中,我们报告了Office31, Office-Home, VisDA和DomainNet126 数据集上的结 果。为了保证公平性,我们遵循与其他主流方法相同的数据集处理方法和训练方式。我们将 DIFO与18种现有的方法分为三组进行比较。
- 第一组包含 Source,CLIP 和 Source+CLIP,其中 Source+CLIP 直接平均源模型和 CLIP 的结 果。
- 第二组包含3种和CLIP结合的最先进的UDA方法。
- 第三组包含13种先进的SFDA方法
此外,为了进行全面比较,我们在中实现 DIFO两个变体:(1) DIFO-C-RN(弱版本)和(2)DIFOC-B32(强版本)。关键区别在于 CLIP 图像编码器的backbone。对于 DIFOC-RN,在 VisDA 数据集上采用 ResNet101 以及 ResNet50 用于其他三个数据集。DIFO-C-B32 采用 ViTB/32 。
1.Comparison Results
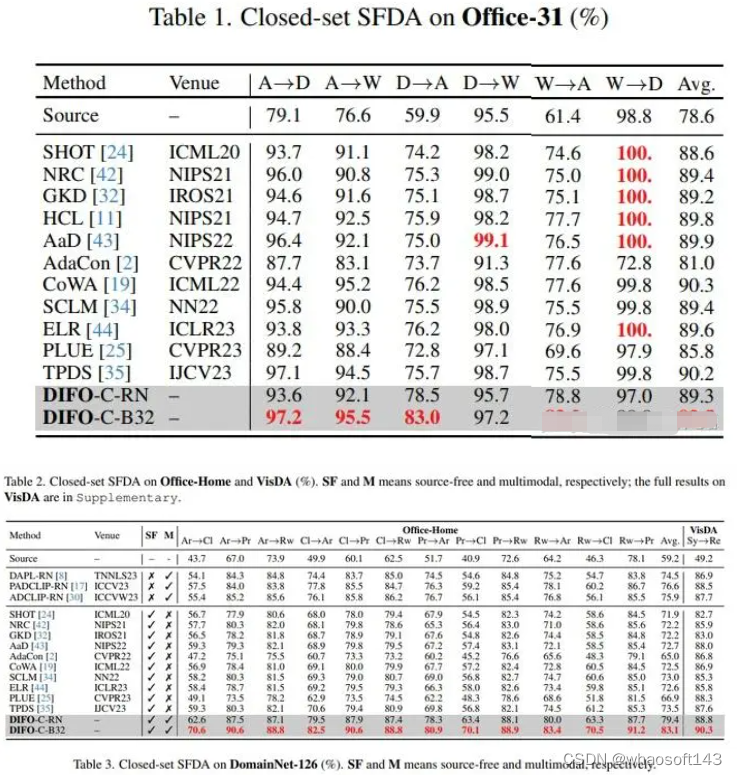
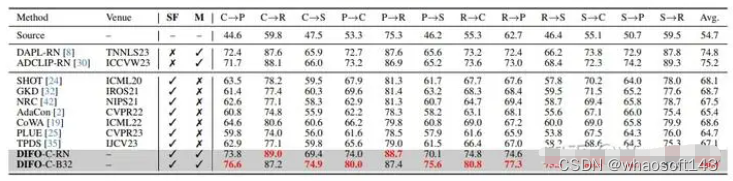
DIFO-C-B32 在 Office-31 上的 6 项任务中的 4 项中获得了最佳结果,同时在其他三个数据集的 所有任务上超越了之前的方法。DIFO-C-RN,除了 Office-31 之外,它获得了第二好的结果,在 Office-Home、VisDA 和 DomainNet-126 上的平均准确率比之前最好的结构高。
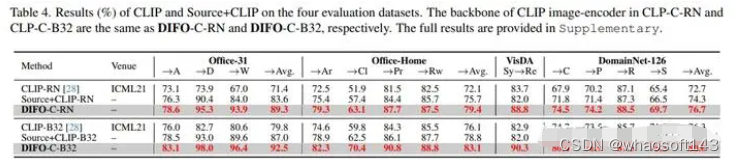
DIFO-C-B32 在所有任务上均优于 CLIP-B32。同样的,DIFO-C-RN也优于 CLIP-RN。这表明,原始CLIP模型的领域通用性不能完全适用于目标领域,需要针对特定任务进行定制化。DIFO-C-B32 在所有任务上也均优于Source+CLIP-B32,这说明简单的加权方法无法实现理想的任务特定融合,需要精心设计的蒸馏方法。
2. Comparison on Partial-set and Open-set SFDA settings
这些是传统 Closed-set SFDA 的变体,与 SHOT相同
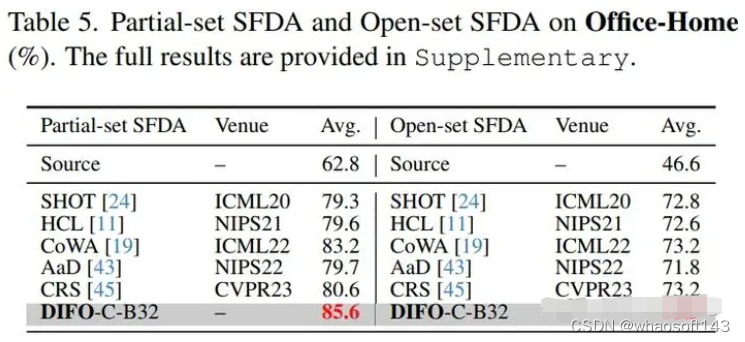
我们的方法也超过了目前最优。
3.Feature distribution visualization
使用t-SNE和3D密度图在Office-Home的Ar→Cl 任务上可视化了特征分布
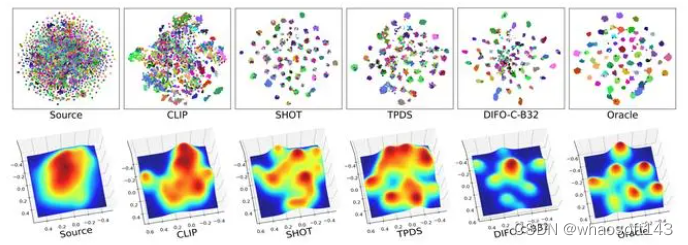
可以看出DIFO的分布是最接近Oracle的分布。
4.Ablation Study
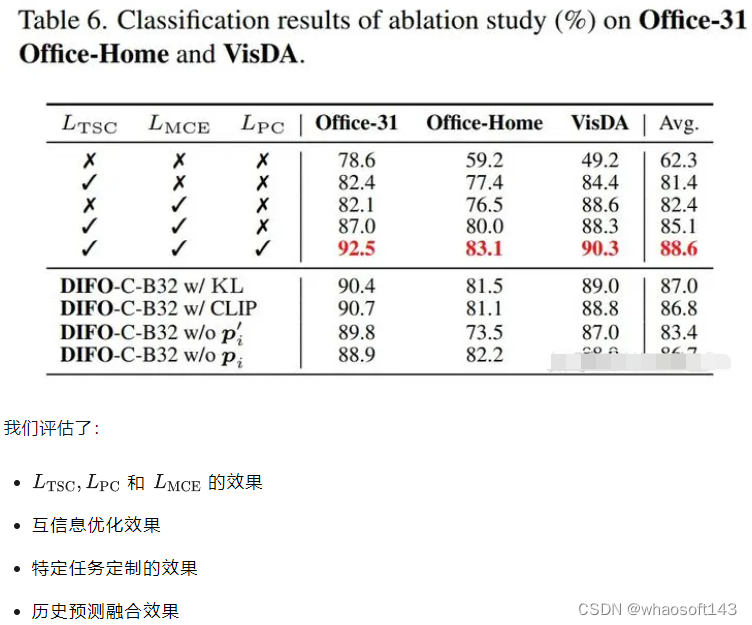
4.Task-Specific Knowledge Adaptation Analysis
我们使用特征空间移位分析 ,利用MMD(maximum mean discrepancy)测量来验证所提出的 方法。在这个实验中,我们首先在所有具有真实标签的 Office-Home 数据上训练一个域不变的 Oracle 模型,表示理想的特定任务空间。我们对Office-Home中Ar→Cl这个迁移任务进行分析。
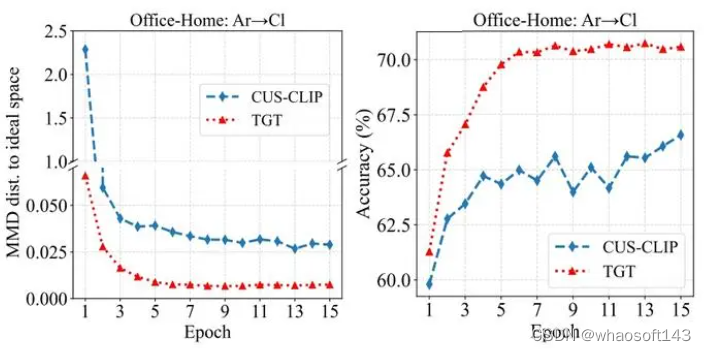
图中红色代表目标域模型(TGT),蓝色代表定制的CLIP模型(CUS-CLIP)。左图代表这两个模 型空间到理想空间的MMD距离。右图代表训练过程中两个模型准确率变换。在前四个epoch,观 察左图,这两模型空间距离理想域的MMD距离急剧下降,这一变化也符合准确率的变化,图右侧 所示。这些结果表明,DIFO使得知识向理想的特定任务空间中收敛。
最后大佬的项目哦















 2463
2463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









