







 SFDA是一个针对语义分割的无源域自适应框架,解决了在源数据集私有情况下进行模型适应的问题。该框架通过生成器估计源域,使用知识转移将源模型的知识迁移到目标模型,并利用目标域数据进行自我监督学习,以实现模型的自适应。文章提出的IPSM模块增强了模型在自适应阶段的性能。
SFDA是一个针对语义分割的无源域自适应框架,解决了在源数据集私有情况下进行模型适应的问题。该框架通过生成器估计源域,使用知识转移将源模型的知识迁移到目标模型,并利用目标域数据进行自我监督学习,以实现模型的自适应。文章提出的IPSM模块增强了模型在自适应阶段的性能。
一、《SFDA》提出的问题和解决方法
《SFDA》提出的问题:现有的UDA方法在这方面不可避免地需要完全访问源数据集来减少源和目标域之间的差距在模型适应,这是不切实际的现实场景中源数据集是私有的,因此不能发布与训练有素的源模型,缺少源数据集。
《SFDA》的解决方法:提出了一个用于语义分割的无源域自适应框架,即SFDA,其中只有一个训练良好的源模型和一个未标记的目标域数据集可用于自适应。SFDA不仅能够在模型自适应过程中通过知识转移从源模型中恢复和保存源域知识,而且还可以从目标领域提取有价值的信息,用于自我监督学习。
二、SFDA框架
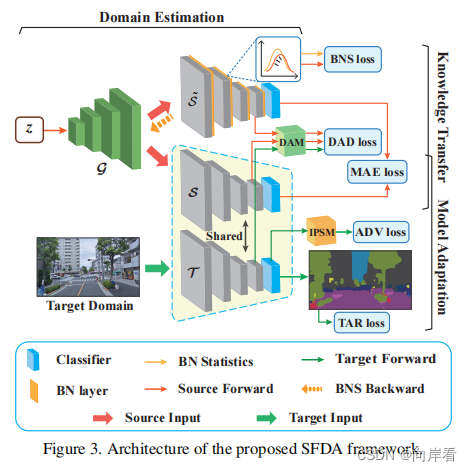
框架主要有三个阶段:源域估计阶段、知识转移和模型适应。
源域估计阶段:在无法访问源域数据的情况下,首先使用生成器和固定权重的源域模型对源域进行了估计,使生成器能够生成符合源域分布的样本。
知识转移阶段:利用生成器来估计源域(工作域)并合成与分布中的真实源数据相似的假样本,用于将域知识从训练有素的源模型转移到目标模型
模型适应阶段:通过知识转移从源模型中恢复和保存源域知识,而且还能够从目标域中提取有价值的信息,用于自我监督学习。提出了一个基于熵的域内补丁级自我监督模块(IPSM),以利用正确分割的补丁作为模型自适应阶段的自我监督。


















 119
119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











