








首先举一个决策树的例子:
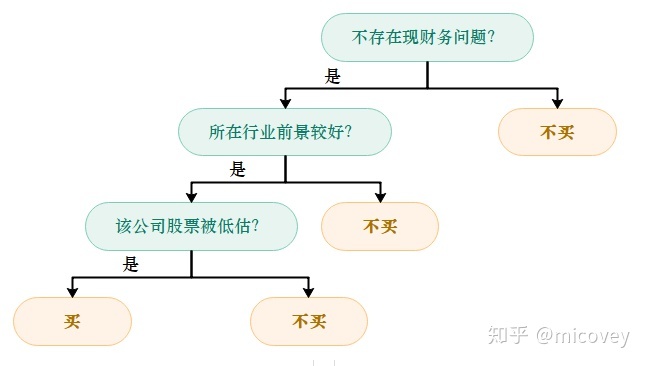
这是一个抽象的决策树。
- 决策树与回归模型的比较:
- 线性回归:连续性数据(例如预测明天的收益率)
- 决策树:主要分类问题(例如预测明天股价是否上升),也可以是连续性
2. 决策树的构建
2.1 构建原则
- 随着决策树深度(决策树的高度)的增加,节点的熵值(不确定性)迅速降低。
- 构建的决策树的深度不要过深(数不能太高):防止过拟合问题
2.2 选择结点
2.2.1 信息熵
2.2.1.1信息熵的含义
例如由上图,为什么是先选择是否出现财务问题,而不是先选择是否行业前景较好呢?这里用到的是信息熵。熵是对平均不确定性的度量。熵越大,数据的不确定性越高,熵越低,不确定性最低。其中pi是指,每个信息所占的比例。
2.1.1.2 信息熵的计算
例1:是否出现财务问题这个信息中,出现财务问题的公司数量为100家,没有出现财务问题的公司数量为300家,那么p1=0.25,p2=0.75. H=-0.25log2(0.25)-0.75log2(0.75)=0.81
例2:是否出现财务问题这个信息中,出现财务问题的公司数量为200家,没有出现财务问题的公司数量为200家,那么p1=0.5,p2=0.5. H=-0.5log2(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2977
2977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









