









1. 决策树介绍
决策树【Decision Tree,DT】是一类较为常见的「机器学习」方法,DT既可以作为分类算法,也可以作为回归算法。
举个分类的例子:
在相亲的时候,找对象的顺序应该是:
- Q:性别要求?
- A:不是女的不要。
- Q:年龄要求?
- A:大于我5岁的不要。
- Q:专业要求?
- A:非计算机专业的不要?
- …
为了更好的表示上面的这些问题,我们将其画成一张树状图:

上面的这棵树就是我们找对象的决策过程,圆角矩形代表了判断条件,椭圆代表了决策结果。通过性别、年龄和专业这几个属性,最终,得出最后的决策。因此,这棵树被称之为决策树。
通过绘制决策树,发现一颗决策树上3种节点:
- 根节点:包含样本的全集
- 内部(中间)节点:对应特征属性
- 叶节点:代表决策的结果
在一颗决策树中,包含了一个根节点,多个内部节点,若干个叶子节点。
先说叶子节点,在决策树中,叶子节点对应了决策结果,决策结果可以有多种类型(要,不要,也可以是Yes,No,1,2)。
内部节点和根节点对应的都是对应特征属性,只不过先后顺序不同。
总的来说,决策树体现的是一种“分而治之”的思想。
2. 结点的选择
首先,我们要明白根节点和中间节点是不同的,一个统领全局的开始包含所有的样本。一个负责局部的决策,并且随着决策树的延伸,不断进行决策,所包含的样本逐渐属于同一个类别,即节点的“纯度”越来越高。
那么,我们如何寻找合适的根节点(也就是特征属性)呢?
靠感觉?靠猜?那肯定是不行的,我们需要一个具体的数值来决定,很幸运,香农帮我们解决了这个问题。
“信息熵”(information entropy):可以度量样本集合中的“纯度”。在信息世界,熵越高,表示蕴含越多的信息;熵越低,表示信息越少。而根节点需要包含所有的样本,则根节点的熵最大。
3. 信息熵(Information Entropy)
设样本集合为
D
D
D,第k类样本【根据各类样本类别标签占比来计算信息熵】所占比例为pk (1,2,3,…,n),则集合
D
D
D的信息熵为:
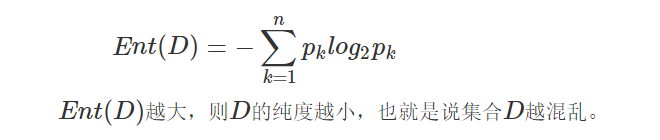
现在,我们已经知道一个集合
D
D
D中的信息熵是多少,那么我们如何进行划分呢?
首先,我们需要明确一个划分的标准(也就是目标),我们当然希望划分之后,集合的熵越来越小,也就是划分后的集合越来越纯,这里我们引入信息增益这个概念。
4. 信息增益(Information Gain)
下面是西瓜书中对信息增益的定义:

一般来说,信息增益越大,则代表划分后的集合越“纯”,也就是说使用a属性来划分的效果最好,那么我们就可以使用a属性来进行划分。ID3算法就是使用信息增益来作为标准划分属性的。
-------------------------------------------分割线-----------------------------------------
我们以实际的例子进行展示:

在上图中,属性的集合是 {色泽,根蒂,敲声,纹理,脐部,触感}(目前不考虑编号这个属性),分类的集合是 {是,否},一共有17个样本。
- 首先,让我们来计算集合
D
D
D的熵值:
好瓜(是)占比:p1 = 8 17 \frac{8}{17} 178
坏瓜(否)占比:p2 = 9 17 \frac{9}{17} 179
所以集合 D D D的熵为:
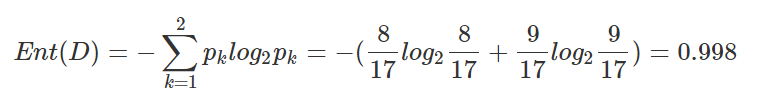
以色泽作为划分标准,可以得到3个子集:

我们可以获得D1,D2,D3的信息熵:

因此色泽的信息增益为:

同理可以得到根蒂、纹理、触感的信息增益:

通过计算可以得到,纹理的信息增益最大,因此他被选为划分的属性如下图:

- 然后,以纹理是“清晰”为例,该集合D1={1,2,3,4,5,6,8,10,15},可用的属性集合为{ 色泽,根蒂,敲声,脐部, 触感}。因此,基于D1又可以计算出各个属性的信息增益:
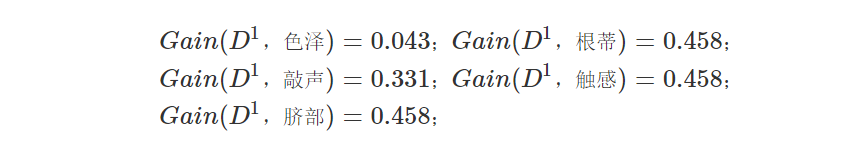
因此我们可以在“根蒂”,“触感”,“脐部”中任意选择其中一个作为划分属性。最终得到以下的决策树:

通过上面的这些步骤,我们就得到了一颗关于西瓜的好坏的决策树。ID3决策树就是用信息增益作为划分标准。
5. 增益率(Gain Ratio)
在这里有一个问题,Gain(D,属性)越大,就一定能够作为划分标准吗?假如它是一个无用的属性呢?比如上图中编号这个属性,如果在上面我们选择编号作为根节点,那么第一次划分就能够得到17个集合,每一个集合只有1个样本,Gain(D,编号)必定能够达到最大值。
但是我们知道,编号这个属性在这里是毫无作用的。如果将这个问题进行泛化,如果一个属性在分类中起到的作用给很小(也就是它对分类的影响很小),那么我们应该怎么考虑呢?
这里我们可以使用增益率来作为划分的标准,定义如下:

IV(a) 称之为属性a的固有值(intrinsic value),属性a的可能取值越多(划分的Dv的集合越多),IV(a)就会越大。若像编号一样进行划分(每一个划分的集合中只有一个样本),随着编号的增多,IV(a)的取值如下图:

其中著名的C4.5决策树就是使用增益率来划分属性。
6. 基尼指数(Gini Index)
前面我们使用信息熵来表示集合的纯度,这里我们使用基尼值来表示:
设样本集合为D,第
k
k
k类样本所占比例为pk(k=1,2,3,……n)

Gini(D) 反映了从数据集中随机抽取两个样本,其类别标记不一致的概率。因此, Gini(D)越大,则数据集越复杂,纯度越低。
同样,属性a的基尼指数定义为:
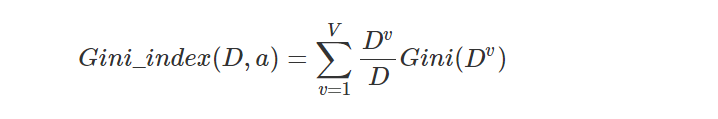
因此,在我们选择合适的属性进行划分的时候,选择划分后基尼指数较小的属性作为划分标准即可。
CART决策树使用基尼指数作为划分标准。

















 2161
2161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











