






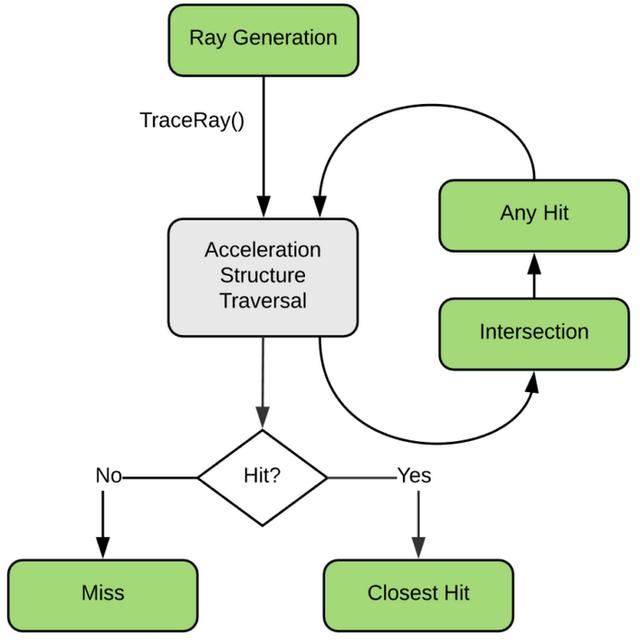
 本文介绍了NVIDIA RTX显卡如何通过Tensor Core和RT Core加速3D创作软件,如Blender,提供实时光线追踪和AI技术。RTX GPU在3D建模渲染中显著提升效率,特别是在Blender 2.83版本中,支持OptiX技术,使得渲染和降噪速度大幅提升,与CUDA相比有明显优势。测试表明,不同级别的RTX 20系列显卡在Blender渲染速度上优于CUDA和CPU,RTX 2080 Ti表现最佳。
本文介绍了NVIDIA RTX显卡如何通过Tensor Core和RT Core加速3D创作软件,如Blender,提供实时光线追踪和AI技术。RTX GPU在3D建模渲染中显著提升效率,特别是在Blender 2.83版本中,支持OptiX技术,使得渲染和降噪速度大幅提升,与CUDA相比有明显优势。测试表明,不同级别的RTX 20系列显卡在Blender渲染速度上优于CUDA和CPU,RTX 2080 Ti表现最佳。
NVIDIA的RTX图灵架构GPU里面加入了Tensor Core与RT Core两个新的单元,在游戏里面前者带来了DLSS深度学习超级采样,而后者则带来了绚丽的实时光线追踪,其实这些单元不单止在游戏里面有用, 软件开发商也可透过NIVIDA提供的SDK为自己的软件添加AI深度学习以及光线追踪渲染加速功能,比如各种3D设计软件也可以利用RTX显卡来进行运算,渲染速度比以前光用CPU来算快得多。

NVIDIA表示他们一直与全球领先的软件制造商合作,到目前已经有超过40款顶尖的3D创作应用,支持RTX的实时光线追踪和AI技术,当中包括了Adobe、Autodesk、Blackmagic Design等在内行业知名开发商的创作软件。

GPU加速在过去的创作软件中其实早有应用,但在NVIDIA的这些合作软件里面,不仅仅是用GPU去做通用计算的CUDA加速,还利用图灵架构GPU特有的实时光线追踪(RT Core),以及AI运算能力(Tensor Core)来实现一些过去没有或者难以做到的新功能,比如Adobe Premiere Pro的Auto Reframe加速,Lightroom利用AI加快照片的增强处理,还有DaVinci Studio的自动面部识别等。
3D建模设计和渲染工作也是RTX显卡要进行加速的重要部分,因为创作者往往在这类工作流的渲染部分上耗费大量时间,传统利用CPU来渲染的速度很慢,所以NVIDIA与创作软件开发商合作,引入GPU来做渲染工作, 知名的3D全局光照渲染器Arnold,基于RTX技术开发了GPU渲染器,目前已经应用到3D建模和CG设计行业的两大软件,Autodesk的3ds Max和Maya最新版当中,相比传统的CPU渲染,使用RTX GPU能带来更快速的建模渲染能力,特别是带有大量光照效果的场景,这可以大大帮助提高这类3D设计工作的效率。

图片来自NVIDIA官网
而且不局限于大型商用软件,如今越来受欢迎的免费开源3D动画建模软件Blender,在其最新版本中也加入了对NVIDIA OptiX技术支持,而不同于此前Blender支持的CUDA技术,OptiX可以更好地发挥出RTX 20系列GPU的渲染性能,特别是对于涉及到光照效果时,会利用到Turing架构的RT Core,来获得快而准确的光线追踪处理速度,另外在对3D模型进行降噪时,还用到TensorCore核心来实现AI运算处理,可以用于提高渲染模型的质量。
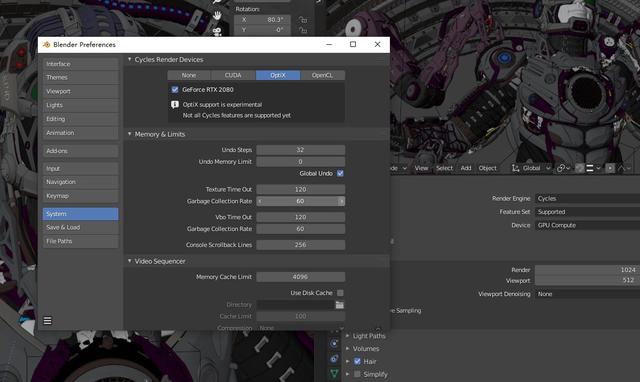
对于使用Blender的3D建模师、动画制作者们,只需要下载最新版Blender 2.83或更新版本安装后,软件一般就会默认完成设置,但也可以手动在软件的编辑-偏好设置-系统,选择OptiX,另外需要注意的,渲染引擎要选择Cycles,因为这个才是支持NVIDA OptiX技术,但整个设置还是非常简单的。
实际在Blender 2.83软件里面,打开一个形似钢铁侠的3D模型场景Blenderman,在切换到Viewpoint Shading视图,利用了RTX 显卡的GPU Compute渲染引擎,可以比较快地把模型的人脸皮肤、装甲材质,以及光照、反光效果给渲染出来,即使在场景的三维空间拖动模型,让观看视角改变,GPU渲染的响应也非常快速,只需等一阵子就完成初步渲染,几乎能做到实时的预览,而换到CPU模式下,引擎的渲染速度就变得非常缓慢,需要耗费数分钟的时间才能看到大致的模型外貌。
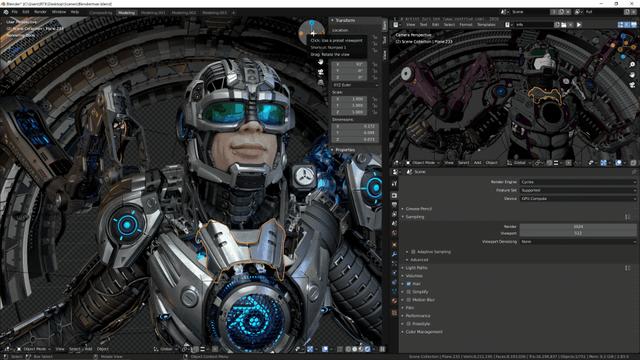
只是通过GPU渲染出来的模型,其表面会有很明显的噪点,所以需要打开Viewport Denoising来对模型进行降噪,在RTX 20系列GPU的支持下,Blender提供了OptiX AI加速的降噪选项,这个用机器学习训练过的降噪技术,处理的过程也非常快速,几乎是可以跟随GPU Compute的渲染过程同时完成。
再就是改变模型的环境光照效果,得益于RTX GPU标志性的光线追踪技术,对光照处理有得天独厚的强大处理能力,在切换了场景光照的颜色、强度,或者角度时,GPU的渲染速度都不会减慢,依然保持了在更改完数值后,GPU就会把模型快速输出预览效果,完整渲染好也没有额外增加耗时,表现非常高效和迅速。
测试平台与说明
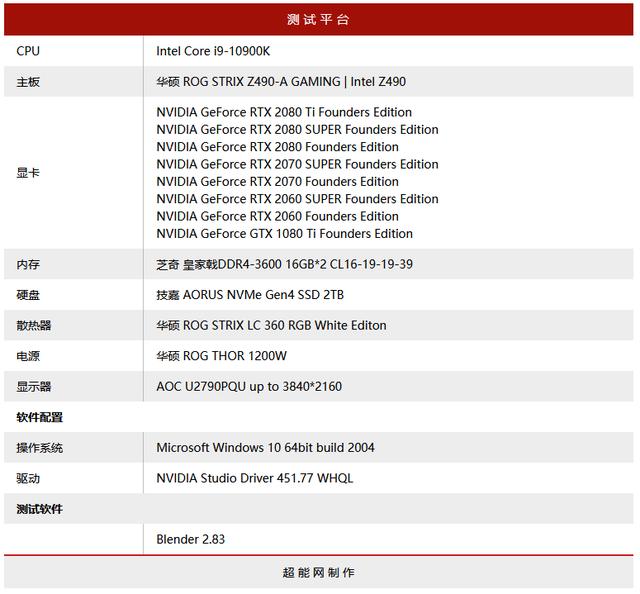
本次测试我们使用了全部NVIDIA RTX 20系列的Founders Edition显卡,看看不同级别的显卡在Blender软件渲染速度有多大不同,在加一张与GTX 1080 Ti Founders Edition,要看看两代核心之间的效能差距有多大,同时还会对比纯CPU渲染的速度,驱动为NVIDIA最新版Studio驱动451.77。

测试平台处理器选用Intel最新的Core i9-10900K,因为还想看看Intel的核显会有啥影响,主板是华硕ROG STRIX Z490-A GAMING,内存是芝奇皇家戟DDR4-3600 CL16 16GB*2套装。
测试使用Blender 2.83版本,测试用项目有两个,一个就是上面所说的Blenderman项目,而另一个则是Blender官方提供的benchmark软件。
Blenderman项目测试
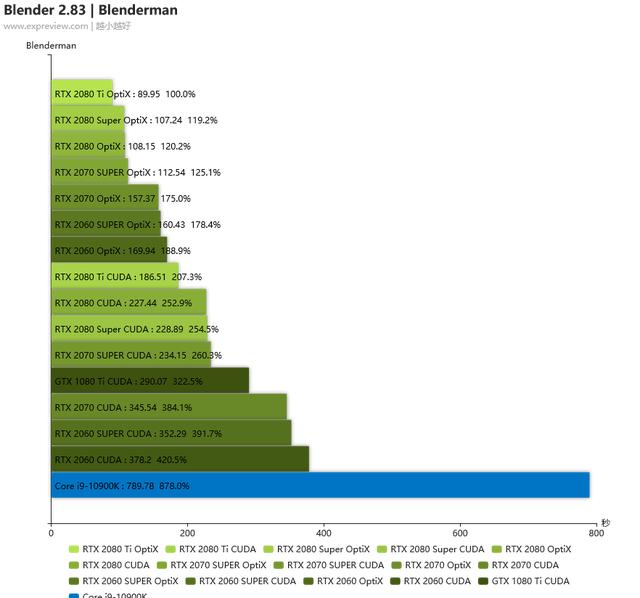
可以看到用RTX 20系列显卡OptiX渲染的话效能是要比用CUDA高很多的,基本上用CUDA渲染的耗时是用OptiX的两倍,RTX 2060使用OptiX渲染的时间比上一代旗舰GTX 1080 Ti用CUDA的渲染时间少了将近一般,当然了,不论用哪个API,显卡的渲染速度都比CPU快得多,即使是Intel最新的10核处理器Core i9-10900K,所用时间依然是RTX 2060用CUDA时的两倍多。
Blender Benchmark

这个Benchmark是Blender本身有基于实际建模项目而来的Open Data benchmark,基本能还原硬件在建模的渲染和降噪的速度表现,这个Benchmark目前最新版本也内置了Blender 2.83,也支持OptiX技术。测试包括六个测试场景,由于数据量太大,所以没有放出RTX显卡用CUDA API的成绩,这几款RTX 20显卡的渲染时间基本上就和他们的性能称反比,RTX 2080 Ti的耗时最短,RTX 2060的耗时最长,但依然要比GTX 1080 Ti用CUDA快得多,纯CPU渲染就更慢了,可见能使用RTX 20显卡的OptiX来渲染的话大幅缩短渲染时间,为创作者和工作室节约时间,进而提升生产力。
RTX 20显卡+OptiX可大幅缩短渲染时间

从测试成绩来看,在支持到OptiX技术后,RTX 20系列显卡的渲染速度提升非常突出,其实在CUDA技术的时候,他们的渲染速度都比CPU有了数倍的提升,而在利用到RTX 20系列GPU更强的硬件特性后,居然还能再有2-3倍的提速,不可谓不夸张了,这样的加速表现,对于经常需要进行建模渲染工作的创作者是很有意义的,他们现在可以更快地查看或交付作品。
越高级的RTX显卡渲染效率越高,如果注重效率的话,RTX 2080 Ti是性能最好的选择,另外Blender是可以支持多卡渲染的,所以如果觉得一张卡满足不了你的话甚至可以使用双卡实现更快渲染速度。但如果是那些刚入门的建模工作者,或者只是想买来学习用的,RTX 2060开启OptiX后也可以带来不错的加速效率,比GTX 16/10系列只能用CUDA的快上不少,而且即使是GTX 16/10的渲染速度也比纯CPU渲染要快,毕竟渲染这类追求并行处理能力的工作,显卡要比CPU强太多了。

















 9096
9096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









