





这里提出了一种新的注意力范式,Agent注意力,以在计算效率和表征能力之间取得良好的平衡。全新注意力范式,Softmax和线性注意力的融合,显著提高性能
文章地址:https://arxiv.org/abs/2312.08874
项目地址:https://github.com/LeapLabTHU/Agent-Attention
现状: 注意力模块是transformer的关键部件。虽然全局关注机制具有较高的表达能力,但其过高的计算成本限制了其在各种场景中的适用性。
解决:
本文中提出了一种新的注意力范式,Agent注意力,以在计算效率和表征能力之间取得良好的平衡。具体来说,Agent Attention,表示为四元组(Q, A, K, V),在传统的Attention模块中引入了一组额外的Agent token A。代理 token首先充当查询token Q的代理,从K和V中聚合信息,然后将信息广播回Q。考虑到代理token的数量可以设计得比查询token的数量小得多,代理注意力比广泛采用的Softmax注意效率高得多,同时保留了全局上下文建模能力。作者证明了所提出的代理注意力等同于线性注意的广义形式。因此,代理注意力可以将强大的Softmax注意力与高效的线性注意力无缝结合。
结果: 作者用大量的实验证明了agent 注意力在各种VIT和各种视觉任务中的有效性,包括图像分类、目标检测、语义分割和图像生成。此外,agent注意力在高分辨率场景中表现出了显著的性能,这是由于其线性注意力的性质。例如,当应用于稳定扩散时,agent注意力加速了生成,并且在没有任何额外训练的情况下大大提高了图像生成质量
1 相关工作
1)线性注意力与限制感受野的想法相反,线性注意力通过降低计算复杂性直接解决了计算挑战。抛弃了Softmax函数,代之以应用于Q和K的映射函数φ,从而将计算复杂度降低到O(N)。然而,这种近似会导致性能大幅下降。为了解决这个问题,Efficient Attention将Softmax函数应用于Q和k。SOFT和Nystr¨omformer采用矩阵分解来进一步近似Softmax操作。Castling-ViT使用Softmax注意力作为辅助训练工具,在推理过程中充分利用线性注意力。FLatten Transformer提出了聚焦函数,并采用深度卷积来保持特征多样性。虽然这些方法是有效的,但它们仍然与线性注意力的有限表达能力问题作斗争。在本文中,提出了一种新的注意力范式,而不是增强Softmax或线性注意力,将这两种注意力类型整合在一起,在各种任务中获得卓越的表现。
2 方法回顾
1)自注意力的一般形式

2)Softmax注意力和线性注意力

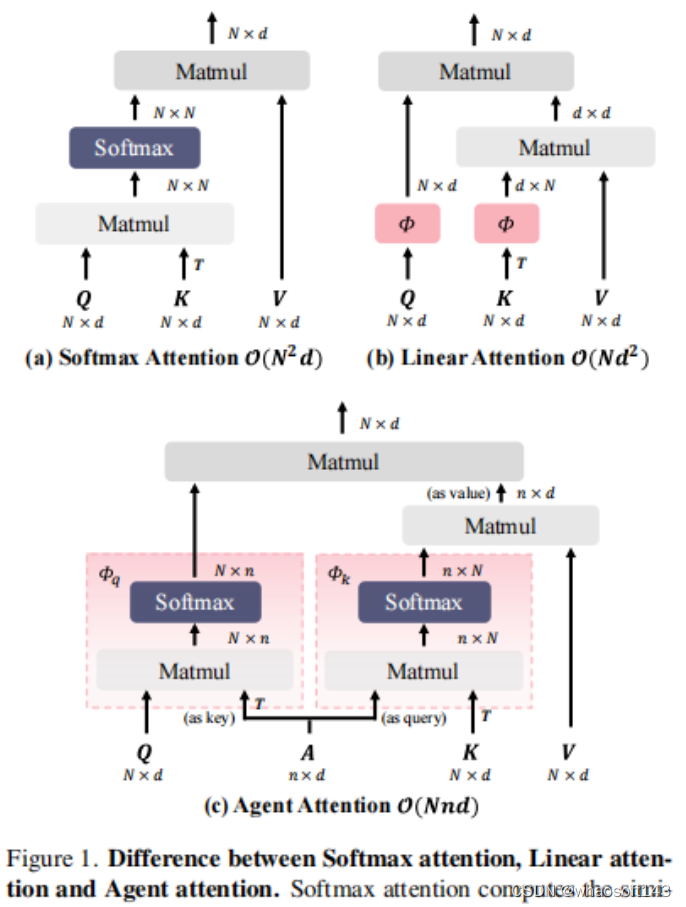
Softmax注意、线性注意和Agent注意的区别

3 方法
Softmax和线性关注要么存在计算复杂度过高,要么存在模型表达能力不足的问题。以往的研究通常将这两种注意范式视为不同的方法,并试图降低Softmax注意的计算成本或提高线性注意的性能。Agent注意力,它实际上形成了Softmax和线性注意力的优雅集成,同时具有线性复杂性和高表达性的优点
1)Agent Attention
将Softmax和线性关注缩写为:

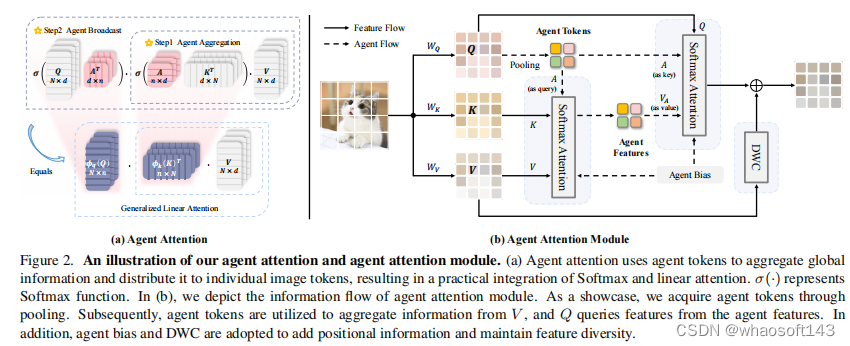
如Eq.(3)和Fig. 2(a)所示,agent attention由两个Softmax attention操作组成,即agent aggregation和agent broadcast。具体来说,最初将代理令牌A视为查询,并在A、K和V之间执行注意力计算,以从所有值中聚合代理特征VA。随后,利用A作为键,VA作为值,利用查询矩阵Q进行第二次关注计算,将agent特征的全局信息广播到每个查询令牌上,得到最终输出o。这样既避免了Q和K的成对相似度计算,又保留了每个查询键对通过智能体令牌进行的信息交换。
新定义的代理令牌A本质上充当Q的代理,聚合来自K和V的全局信息,并随后将其广播回Q。实际上,将代理令牌的数量n设置为一个小的超参数,在保持全局上下文建模能力的同时,相对于输入特征n的数量,实现了O(Nnd)的线性计算复杂度
如Eq.(4)和图2(a)所示,作者实际上将强大的Softmax注意和高效的线性注意结合起来,通过采用两种Softmax注意操作建立了广义的线性注意范式,其等效映射函数定义为
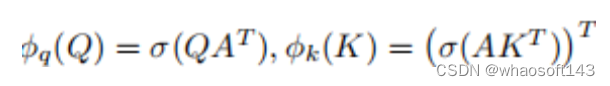
在实践中,可以通过不同的方法获得代理令牌,例如简单地设置为一组可学习的参数,或者通过池化从输入特征中提取。值得注意的是,更高级的技术,如变形点或令牌合并,也可以用来获得代理令牌。作者采用简单的池化策略来获取代理令牌,该策略已经取得了惊人的效果。
2)Agent注意力模块
agent注意继承了Softmax和线性注意的优点。在实际应用中,进一步进行了两方面的改进,以最大限度地发挥代理注意力的潜力。代理的偏置。为了更好地利用位置信息,作者提出了一个精心设计的Agent Bias来吸引Agent的注意力。具体来说,受RPE的启发,作者在注意计算中引入了agent bias,即:
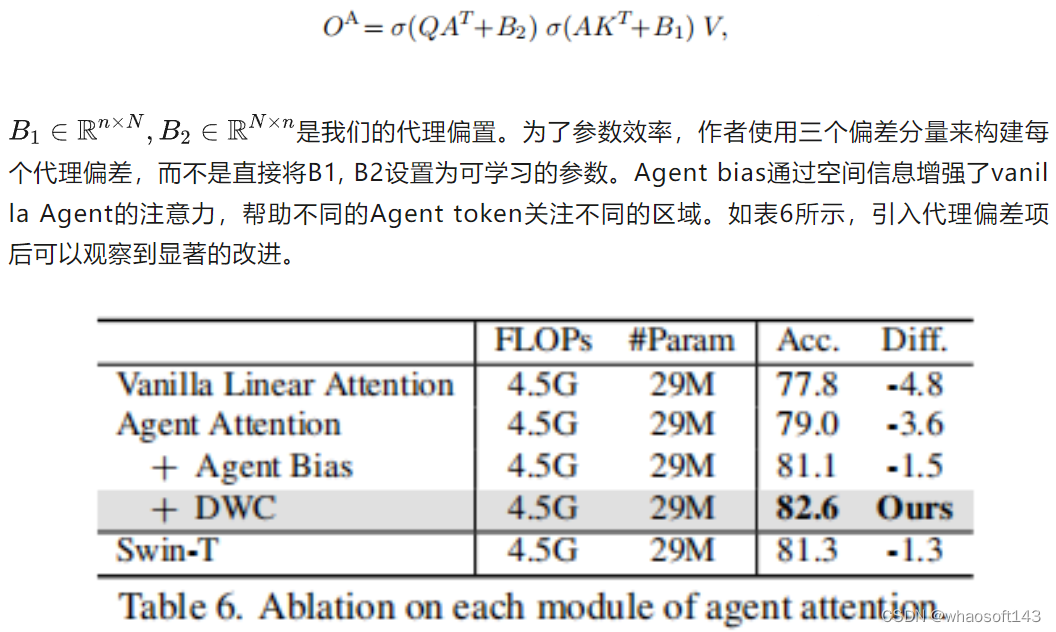
多样性恢复模块 尽管agent注意具有计算复杂度低和模型表达能力强的优点,但作为广义线性注意,它也存在特征多样性不足的问题。作为补救措施,作者采用深度卷积(DWC)模块来保持特征多样性。
代理注意和代理注意模块
Agent注意模块 在这些设计的基础上,作者提出了一种新的注意力模块——Agent注意力模块。如图2(b)所示,模块由三部分组成,分别是纯agent attention, agent bias和DWC模块。模块可以表述为:
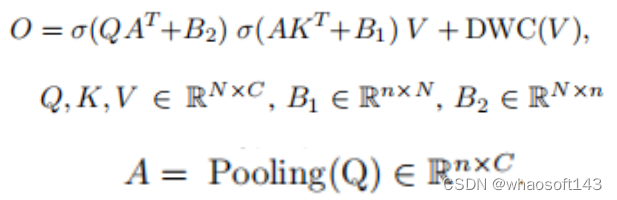
结合Softmax和线性注意力的优点,agent逐一模块具有以下优点:
(1)高效的计算和高表达能力。以往的研究通常将Softmax注意和线性注意视为两种不同的注意范式,旨在解决它们各自的局限性。作为这两种注意力形式的无缝融合,agentt注意力自然继承了两者的优点,同时具有较低的计算复杂度和较高的模型表达能力。
(2)接受野大。Agent注意模块可以在保持相同计算量的情况下采用较大的接受域。现代视觉Transformer模型通常采用稀疏注意]或窗口注意来减轻Softmax注意的计算负担。得益于线性复杂性,模型可以在保持相同计算的同时享受到大的,甚至是全局接受域的优势。
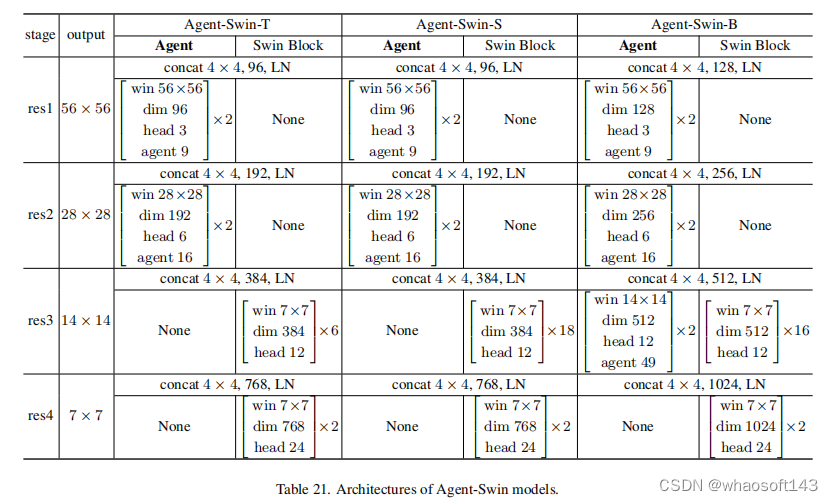
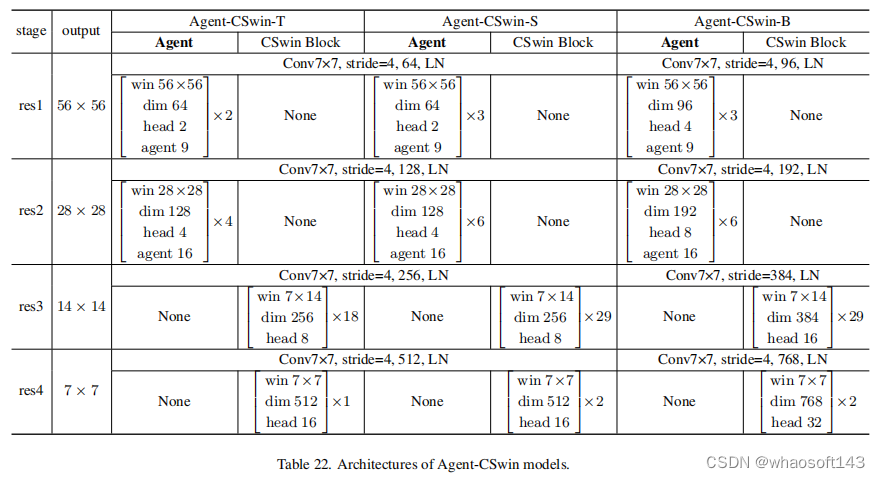
3)Implementation代理注意力模块可以作为一个插件模块,并且可以很容易地采用在各种现代VIT架构上。作为展示,作者将Agent经验性地应用于四种先进且具有代表性的变压器模型,包括DeiT、PVT、Swin和CSwin。同时还将agent注意力应用于Stable Diffusion,以加速图像生成。
下面是部分模型经过Agent 模块插入的详细信息。
04 实验结果
图像分类
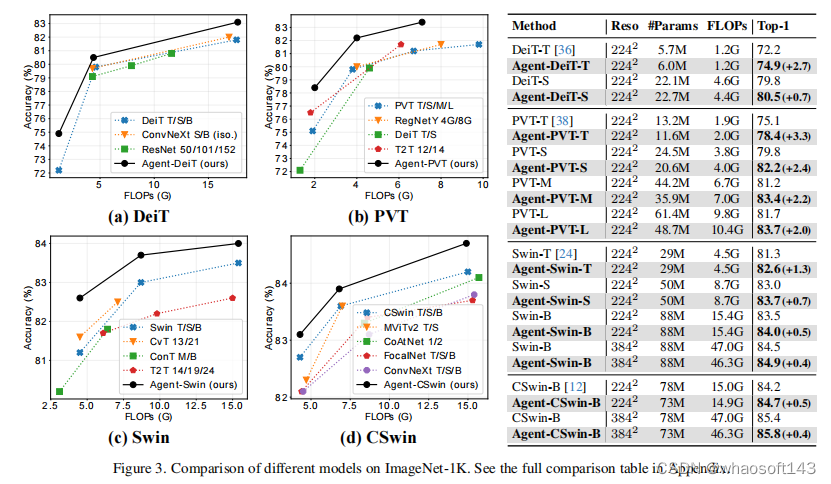
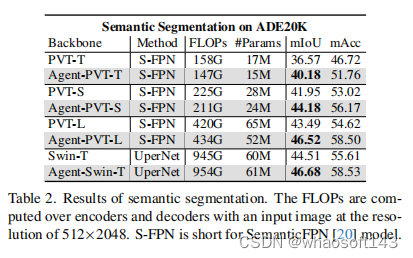
目标检测
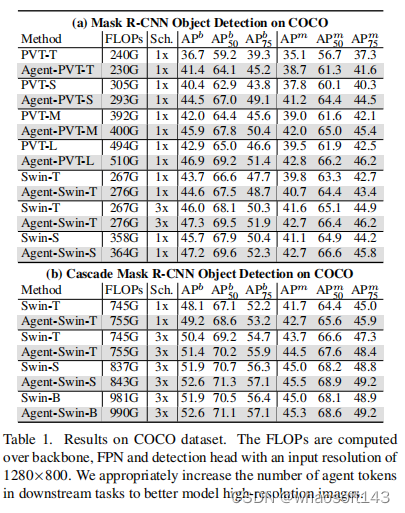
精度 - 速度对比
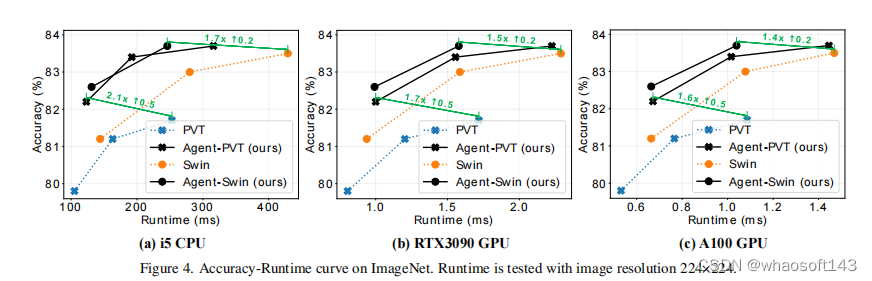
图像分割
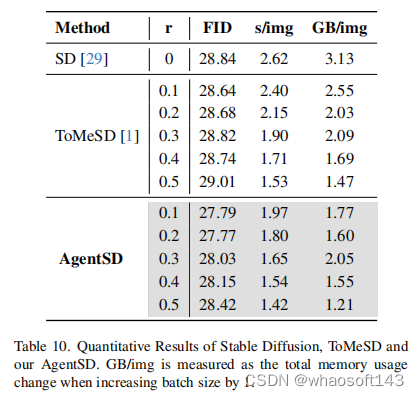
Stable Diffusion加速















 4989
4989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









