







来自公众号: 路人甲Java
学习索引,主要是写出更快的sql,当我们写sql的时候,需要明确的知道sql为什么会走索引?为什么有些sql不走索引?sql会走那些索引,为什么会这么走?我们需要了解其原理,了解内部具体过程,这样使用起来才能更顺手,才可以写出更高效的sql。本篇我们就是搞懂这些问题。
读本篇文章之前,需要先了解一些知识:
什么是索引?
mysql索引原理详解
mysql索引管理详解
上面3篇文章没有读过的最好去读一下,不然后面的内容会难以理解。
先来回顾一些知识
本篇文章我们以innodb存储引擎为例来做说明。
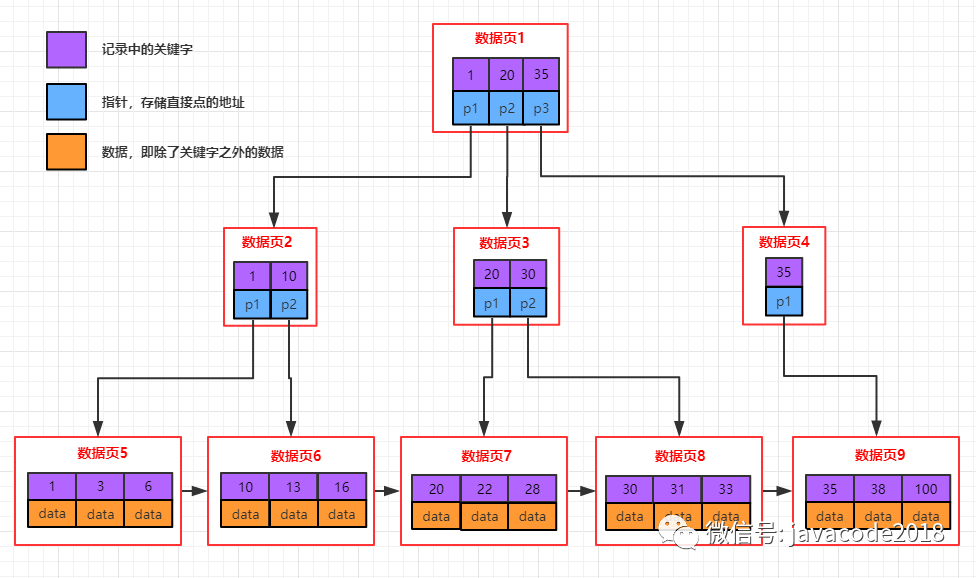
mysql采用b+树的方式存储索引信息。
b+树结构如下:
说一下b+树的几个特点:
叶子节点(最下面的一层)存储关键字(索引字段的值)信息及对应的data,叶子节点存储了所有记录的关键字信息
其他非叶子节点只存储关键字的信息及子节点的指针
每个叶子节点相当于mysql中的一页,同层级的叶子节点以双向链表的形式相连
每个节点(页)中存储了多条记录,记录之间用单链表的形式连接组成了一条有序的链表,顺序是按照索引字段排序的
b+树中检索数据时:每次检索都是从根节点开始,一直需要搜索到叶子节点
InnoDB 的数据是按数据页为单位来读写的。也就是说,当需要读取一条记录的时候,并不是将这个记录本身从磁盘读取出来,而是以页为单位,将整个也加载到内存中,一个页中可能有很多记录,然后在内存中对页进行检索。在innodb中,每个页的大小默认是16kb。
Mysql中索引分为
聚集索引(主键索引)
每个表一定会有一个聚集索引,整个表的数据存储以b+树的方式存在文件中,b+树叶子节点中的key为主键值,data为完整记录的信息;非叶子节点存储主键的值。
通过聚集索引检索数据只需要按照b+树的搜索过程,即可以检索到对应的记录。
非聚集索引
每个表可以有多个非聚集索引,b+树结构,叶子节点的key为索引字段字段的值,data为主键的值;非叶子节点只存储索引字段的值。
通过非聚集索引检索记录的时候,需要2次操作,先在非聚集索引中检索出主键,然后再到聚集索引中检索出主键对应的记录,该过程比聚集索引多了一次操作。
索引怎么走,为什么有些查询不走索引?为什么使用函数了数据就不走索引了?
这些问题可以先放一下,我们先看一下b+树检索数据的过程,这个属于原理的部分,理解了b+树各种数据检索过程,上面的问题就都可以理解了。
通常说的这个查询走索引了是什么意思?
当我们对某个字段的值进行某种检索的时候,如果这个检索过程中,我们能够快速定位到目标数据所在的页,有效的降低页的io操作,而不需要去扫描所有的数据页的时候,我们认为这种情况能够有效的利用索引,也称这个检索可以走索引,如果这个过程中不能够确定数据在那些页中,我们认为这种情况下索引对这个查询是无效的,此查询不走索引。
b+树中数据检索过程
唯一记录检索
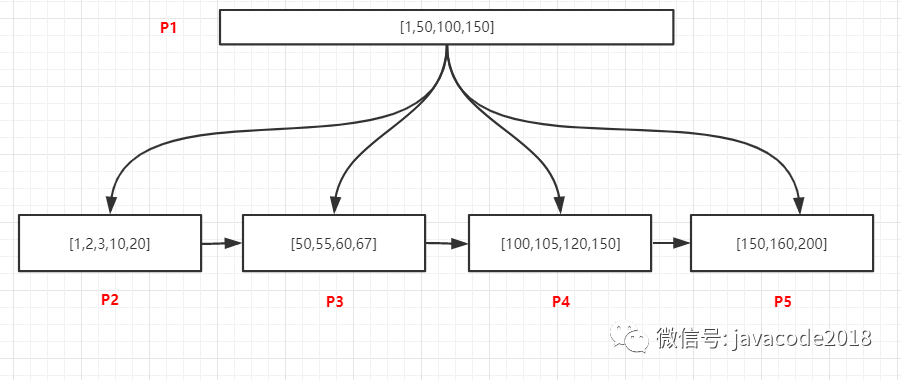
如上图,所有的数据都是唯一的,查询105的记录,过程如下:
将P1页加载到内存
在内存中采用二分法查找,可以确定105位于[100,150)中间,所以我们需要去加载100关联P4页
将P4加载到内存中,采用二分法找到105的记录后退出
查询某个值的所有记录
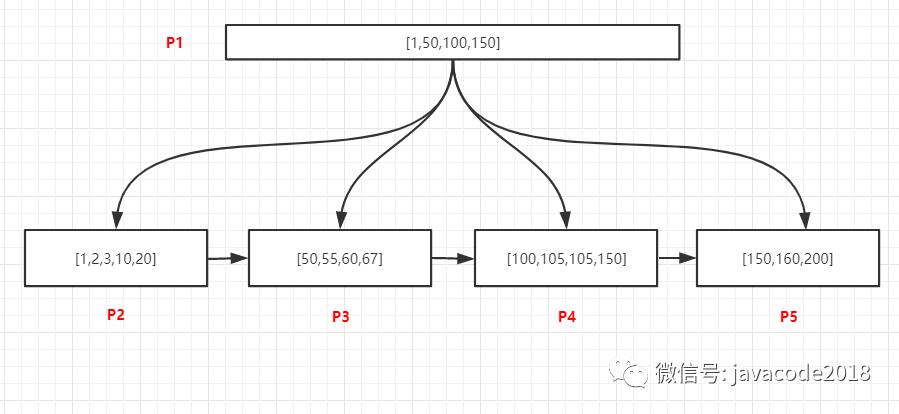
如上图,查询105的所有记录,过程如下:
将P1页加载到内存
在内存中采用二分法查找,可以确定105位于[100,150)中间,100关联P4页
将P4加载到内存中,采用二分法找到最有一个小于105的记录,即100,然后通过链表从100开始向后访问,找到所有的105记录,直到遇到第一个大于100的值为止
范围查找
数据如上图,查询[55,150]所有记录,由于页和页之间是双向链表升序结构,页内部的数据是单项升序链表结构,所以只用找到范围的起始值所在的位置,然后通过依靠链表访问两个位置之间所有的数据即可,过程如下:
将P1页加载到内存
内存中采用二分法找到55位于50关联的P3页中,150位于P5页中
将P3加载到内存中,采用二分法找到第一个55的记录,然后通过链表结构继续向后访问P3中的60、67,当P3访问完毕之后,通过P3的nextpage指针访问下一页P4中所有记录,继续遍历P4中的所有记录,直到访问到P5中所有的150为止。
模糊匹配
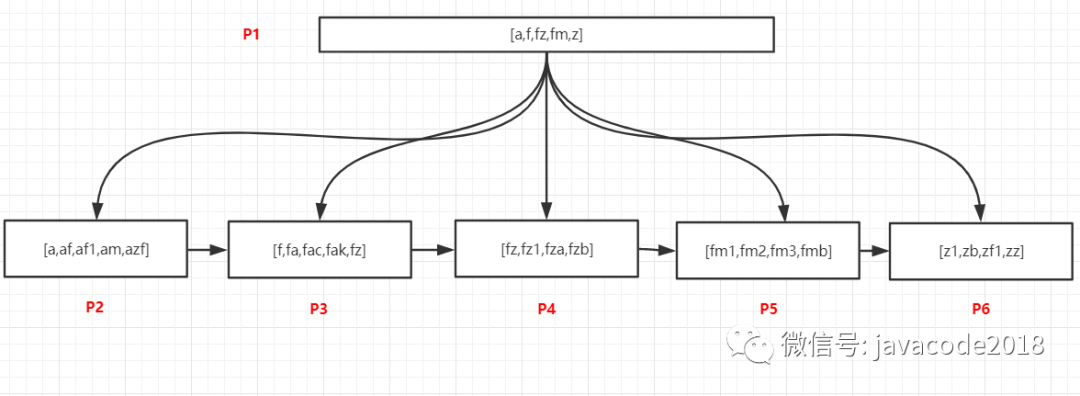
数据如上图。
查询以`f`开头的所有记录
过程如下:
将P1数据加载到内存中
在P1页的记录中采用二分法找到最后一个小于等于f的值,这个值是f,以及第一个大于f的,这个值是z,f指向叶节点P3,z指向叶节点P6,此时可以断定以f开头的记录可能存在于[P3,P6)这个范围的页内,即P3、P4、P5这三个页中
加载P3这个页,在内部以二分法找到第一条f开头的记录,然后以链表方式继续向后访问P4、P5中的记录,即可以找到所有已f开头的数据
查询包含`f`的记录
包含的查询在sql中的写法是%f%,通过索引我们还可以快速定位所在的页么?
可以看一下上面的数据,f在每个页中都存在,我们通过P1页中的记录是无法判断包含f的记录在那些页的,只能通过io的方式加载所有叶子节点,并且遍历所有记录进行过滤,才可以找到包含f的记录。
所以如果使用了%值%这种方式,索引对查询是无效的。
最左匹配原则
当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+树是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
来一些示例我们体验一下。
下图中是3个字段(a,b,c)的联合索引,索引中数据的顺序是以a asc,b asc,c asc这种排序方式存储在节点中的,索引先以a字段升序,如果a相同的时候,以b字段升序&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









