







梯度下降方法(三种不同地梯度下降方法简介)
标签:#优化##机器学习##梯度下降##深度学习#
时间:2018/10/17 14:20:47
作者:小木
梯度下降是一种迭代优化的方法,它的目标是求解一个函数的最小值。我们以一个简单的例子来说明。
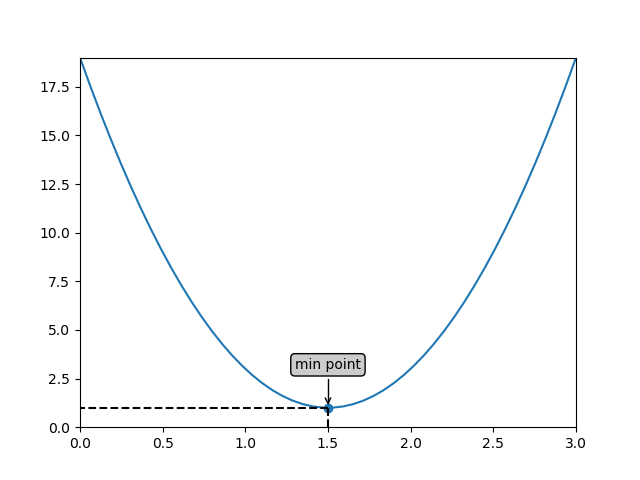
例如,如上图所示,这是一个二次函数的图像:
```math
y = 8(x-1.5)^2 + 1
```
其最低点是$(1.5,1)$。我们希望找到这个最低点。其实,对于这个简单的二次函数,我们只要求y对x的导数,并令其结果为0即可求出最低点。为了说明梯度下降的原理,我们不采用这种方式。
[TOC]
#### 一、梯度下降(Gradient Descent)的原理
梯度下降的原理就是初始随机选择一个函数上的点,然后沿着某个方向运行选择下一个函数上的点,使得下一个点的函数值比上一个点的函数值小,这样不停迭代直到找到最小值位置。那么,这里有可能有三个问题需要注意
- 首先,为什么不使用刚才说的求导方式找最小值?这是因为并不是所有的函数都容易求导,例如对于多元函数来说,就很难,但是梯度下降的原理则依然有效。
- 其次,什么样的函数可以使用梯度下降求解?需要这个函数是凸函数,这样我们才能找到全局最小值,否则就无法确保找到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









