







爬虫学习使用指南
Auth: 王海飞
Data:2018-06-25
Email:[email protected]
github:https://github.com/coco369/knowledge>
2. 获取搜狐体育的新闻信息
爬取搜狐体育中的新闻列表信息,并且获取每一个新闻中的详情介绍。使用mysql数据库将数据持久化。
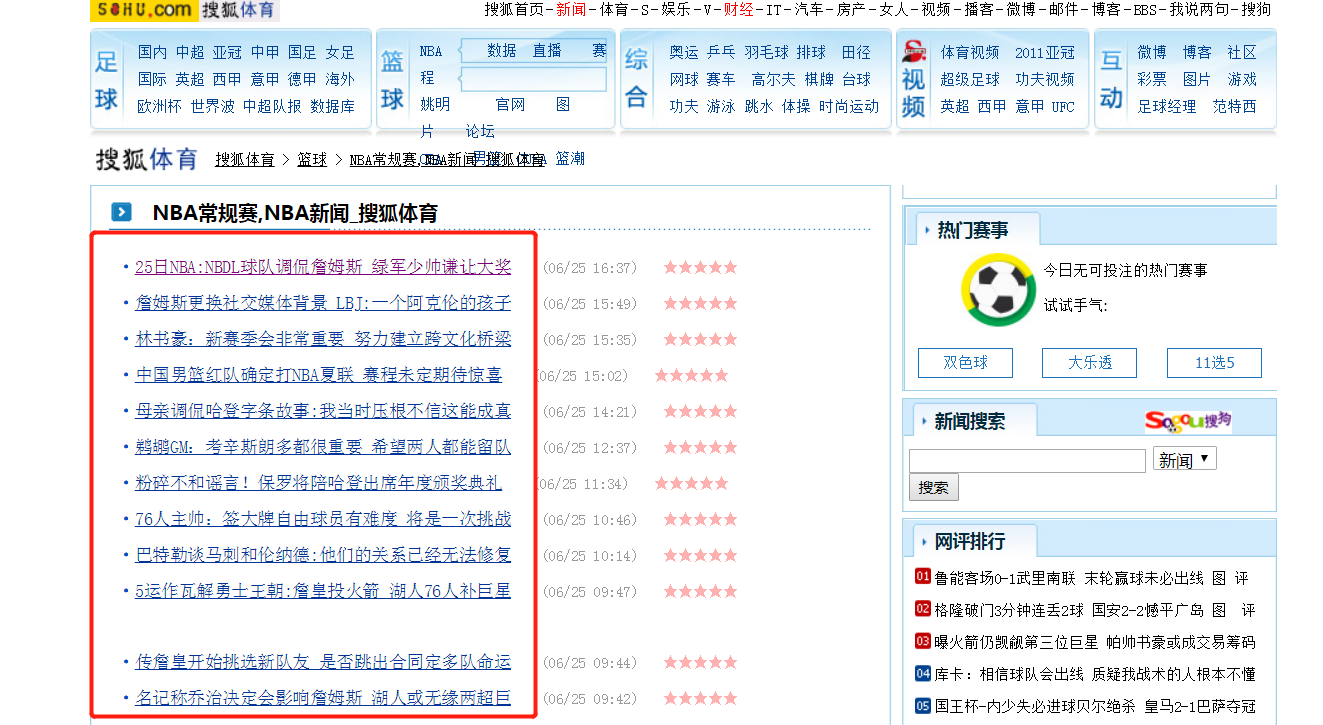
案例代码:
# coding=utf-8
import re
import urllib.request
import pymysql
def decode_html(page_bytes, charsets=('utf-8', 'gbk')):
# 解码页面内容
page_html = None
for charset in charsets:
try:
# 判断源码编码如果正常解析的话,跳出循环
page_html = page_bytes.decode(charset)
break;
except UnicodeDecodeError:
print('网页解码错误')
return page_html
def get_matched_parts(page_html, pattern_st
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5304
5304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









