








本文为预训练语言模型专题的第18篇。
快速传送门
1-4:[萌芽时代]、[风起云涌]、[文本分类通用技巧] 、 [GPT家族]
5-8:[BERT来临]、[浅析BERT代码]、[ERNIE合集]、[MT-DNN(KD)]
9-12:[Transformer]、[Transformer-XL]、[UniLM]、[Mass-Bart]
13-16:[跨语种模型]、[XLNet],[RoBERTa]、[SpanBERT]
17:[跨模态语言模型]
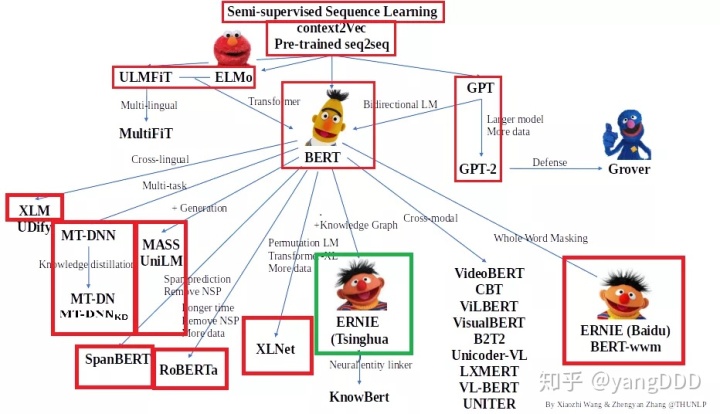
感谢清华大学自然语言处理实验室对预训练语言模型架构的梳理,我们将沿此脉络前行,探索预训练语言模型的前沿技术,红框中为已介绍的文章,绿框中为本期介绍的模型,欢迎大家留言讨论交流。
ERNIE: Enhanced Language Representation with Informative Entities(2019)
在之前的一期推送中,我们给大家介绍过百度的ERNIE。其实清华大学NLP实验室,比百度更早一点,也发表了名为ERNIE的模型,即Enhanced Language Representation with Informative Entities。
他们认为现存的预训练语言模型很少会考虑与知识图谱(Knowledge Graph: KG)相结合,但其实知识图谱可以提供非常丰富的结构化知识和常识以供更好的语言理解。他们觉得这其实是很有意义的,可以通过外部的知识来强化语言模型的表示能力。在这篇文章中,他们使用大规模语料的语言模型预训练与知识图谱相结合,更好地利用语义,句法,知识等各方面的信息,推出了Enhanced language representation model(ERNIE),在许多知识驱动的任务上获得了巨大提升,而且更适用于广泛通用的NLP任务。
作者提出,要将知识嵌入到自然语言模型表达中去,有两个关键的挑战:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









