






from http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
set
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
要创建一个set,需要提供一个list作为输入集合:
>>> s = set([1, 2, 3])
>>> s
{1, 2, 3}
注意,传入的参数[1, 2, 3]是一个list,而显示的{1, 2, 3}只是告诉你这个set内部有1,2,3这3个元素,显示的顺序也不表示set是有序的。。
重复元素在set中自动被过滤:
>>> s = set([1, 1, 2, 2, 3, 3])
>>> s
{1, 2, 3}
通过add(key)方法可以添加元素到set中,可以重复添加,但不会有效果:
>>> s.add(4)
>>> s
{1, 2, 3, 4}
>>> s.add(4)
>>> s
{1, 2, 3, 4}
通过remove(key)方法可以删除元素:
>>> s.remove(4)
>>> s
{1, 2, 3}
set可以看成数学意义上的无序和无重复元素的集合,因此,两个set可以做数学意义上的交集、并集等操作:
>>> s1 = set([1, 2, 3])
>>> s2 = set([2, 3, 4])
>>> s1 & s2
{2, 3}
>>> s1 | s2
{1, 2, 3, 4}
set和dict的唯一区别仅在于没有存储对应的value,但是,set的原理和dict一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”。试试把list放入set,看看是否会报错。
再议不可变对象
上面我们讲了,str是不变对象,而list是可变对象。
对于可变对象,比如list,对list进行操作,list内部的内容是会变化的,比如:
>>> a = ['c', 'b', 'a']
>>> a.sort()
>>> a
['a', 'b', 'c']
而对于不可变对象,比如str,对str进行操作呢:
>>> a = 'abc'
>>> a.replace('a', 'A')
'Abc'
>>> a
'abc'
虽然字符串有个replace()方法,也确实变出了'Abc',但变量a最后仍是'abc',应该怎么理解呢?
我们先把代码改成下面这样:
>>> a = 'abc'
>>> b = a.replace('a', 'A')
>>> b
'Abc'
>>> a
'abc'
要始终牢记的是,a是变量,而'abc'才是字符串对象!有些时候,我们经常说,对象a的内容是'abc',但其实是指,a本身是一个变量,它指向的对象的内容才是'abc':

当我们调用a.replace('a', 'A')时,实际上调用方法replace是作用在字符串对象'abc'上的,而这个方法虽然名字叫replace,但却没有改变字符串'abc'的内容。相反,replace方法创建了一个新字符串'Abc'并返回,如果我们用变量b指向该新字符串,就容易理解了,变量a仍指向原有的字符串'abc',但变量b却指向新字符串'Abc'了:
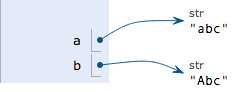
所以,对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,这样,就保证了不可变对象本身永远是不可变的。
小结
使用key-value存储结构的dict在Python中非常有用,选择不可变对象作为key很重要,最常用的key是字符串。
tuple虽然是不变对象,但试试把(1, 2, 3)和(1, [2, 3])放入dict或set中,并解释结果。
切片:
L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']
Python支持L[-1]取倒数第一个元素,那么它同样支持倒数切片
>>> L[-2:]
['Bob', 'Jack']
>>> L[-2:-1]
['Bob']
创建一个0-99的数列:
>>> L = list(range(100)) #range(100)返回一个list
>>> L
[0, 1, 2, 3, ..., 99]
可以通过切片轻松取出某一段数列。比如前10个数:
>>> L[:10]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
后10个数:
>>> L[-10:]
[90, 91, 92, 93, 94, 95, 96, 97, 98, 99]
前11-20个数:
>>> L[10:20]
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
前10个数,每两个取一个:
>>> L[:10:2]
[0, 2, 4, 6, 8]
所有数,每5个取一个:
>>> L[::5]
[0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95]
甚至什么都不写,只写[:]就可以原样复制一个list:
>>> L[:]
[0, 1, 2, 3, ..., 99]
tuple也是一种list,唯一区别是tuple不可变。因此,tuple也可以用切片操作,只是操作的结果仍是tuple:
>>> (0, 1, 2, 3, 4, 5)[:3]
(0, 1, 2)
字符串'xxx'也可以看成是一种list,每个元素就是一个字符。因此,字符串也可以用切片操作,只是操作结果仍是字符串:
>>> 'ABCDEFG'[:3]
'ABC'
>>> 'ABCDEFG'[::2]
'ACEG'
如何判断一个对象是可迭代对象呢?方法是通过collections模块的Iterable类型判断:
>>> from collections import Iterable
>>> isinstance('abc', Iterable) # str是否可迭代
True
>>> isinstance([1,2,3], Iterable) # list是否可迭代
True
>>> isinstance(123, Iterable) # 整数是否可迭代
False
最后一个小问题,如果要对list实现类似Java那样的下标循环怎么办?Python内置的enumerate函数可以把一个list变成索引-元素对,这样就可以在for循环中同时迭代索引和元素本身:
>>> for i, value in enumerate(['A', 'B', 'C']):
... print(i, value)
...
0 A
1 B
2 C
上面的for循环里,同时引用了两个变量,在Python里是很常见的,比如下面的代码:
>>> for x, y in [(1, 1), (2, 4), (3, 9)]:
... print(x, y)
...
1 1
2 4
3 9
列表生成式:
列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式。
举个例子,要生成list [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]可以用list(range(1, 11)):
>>> list(range(1, 11))
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
但如果要生成[1x1, 2x2, 3x3, ..., 10x10]怎么做?方法一是循环:
>>> L = []
>>> for x in range(1, 11):
... L.append(x * x)
...
>>> L
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
但是循环太繁琐,而列表生成式则可以用一行语句代替循环生成上面的list:
>>> [x * x for x in range(1, 11)]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
写列表生成式时,把要生成的元素x * x放到前面,后面跟for循环,就可以把list创建出来,十分有用,多写几次,很快就可以熟悉这种语法。
for循环后面还可以加上if判断,这样我们就可以筛选出仅偶数的平方:
>>> [x * x for x in range(1, 11) if x % 2 == 0]
[4, 16, 36, 64, 100]
还可以使用两层循环,可以生成全排列:
>>> [m + n for m in 'ABC' for n in 'XYZ']
['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
三层和三层以上的循环就很少用到了。
运用列表生成式,可以写出非常简洁的代码。例如,列出当前目录下的所有文件和目录名,可以通过一行代码实现:
>>> import os # 导入os模块,模块的概念后面讲到
>>> [d for d in os.listdir('.')] # os.listdir可以列出文件和目录
['.emacs.d', '.ssh', '.Trash', 'Adlm', 'Applications', 'Desktop', 'Documents', 'Downloads', 'Library', 'Movies', 'Music', 'Pictures', 'Public', 'VirtualBox VMs', 'Workspace', 'XCode']
for循环其实可以同时使用两个甚至多个变量,比如dict的items()可以同时迭代key和value:
>>> d = {'x': 'A', 'y': 'B', 'z': 'C' }
>>> for k, v in d.items():
... print(k, '=', v)
...
y = B
x = A
z = C
因此,列表生成式也可以使用两个变量来生成list:
>>> d = {'x': 'A', 'y': 'B', 'z': 'C' }
>>> [k + '=' + v for k, v in d.items()]
['y=B', 'x=A', 'z=C']
最后把一个list中所有的字符串变成小写:
>>> L = ['Hello', 'World', 'IBM', 'Apple']
>>> [s.lower() for s in L]
['hello', 'world', 'ibm', 'apple']
生成器















 578
578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









