







最近要有一个任务,要爬取https://xueqiu.com/#/cn 网页上的文章,作为后续自然语言处理的源数据。
爬取目标:下图中红色方框部分的文章内容。(需要点击每篇文章的链接才能获得文章内容)
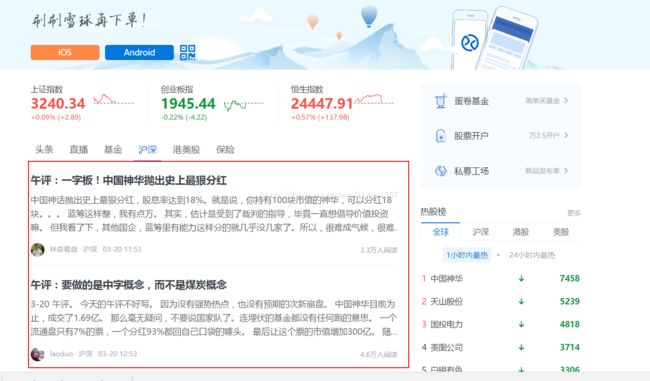
注:该文章仅介绍爬虫爬取新闻这一部分,爬虫语言为Python。
乍一看,爬虫的实现思路很简单:
(1)从原始页面https://xueqiu.com/#/cn上爬取各篇文章的URL
(2)通过第一步所获得的各篇文章的URL,抓取文章内容。
但是发现简单使用urllib2.urlopen()并不能获得红框部分的数据,原因是该部分数据是通过JS动态加载的。
最终发现可以采用Selenium框架来抓取动态数据。Selenium原本是Web测试工具,在Python爬虫中,可以使用它来模拟真实浏览器对URL进行访问,Selenium支持的浏览器包括Firefox、Chrome、Opera、Edge、IE 等。在此我使用的是Firefox浏览器。
Python爬虫脚本如下,可以参考注释来理解代码:
# coding=utf-8
import time
import Queue
import pymongo
import urllib2
import threading
from bs4 import BeautifulSoup
from BeautifulSoup import *
from selenium import webdriver
from selenium.webdriver.common.by import By
# 连接本地MongoDB数据库
client = pymongo.MongoClient()
# 数据库名为shsz_news
db = client.shsz_news
# collection名为news
collection = db.news
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 699
699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









