









概要
这个博客主要实现了雪球网股票评论的爬取,爬取的内容为沪深300股票的评论。
一、爬虫的原理
这部分就不多提了,一些基础的博客我也整理过爬虫从零开始。python爬虫第N课系列学完前十课就对这篇博客的代码完全清楚明白了,因为用到的技术都是最基本的,没有用到什么scrapy框架或者是多线程爬虫
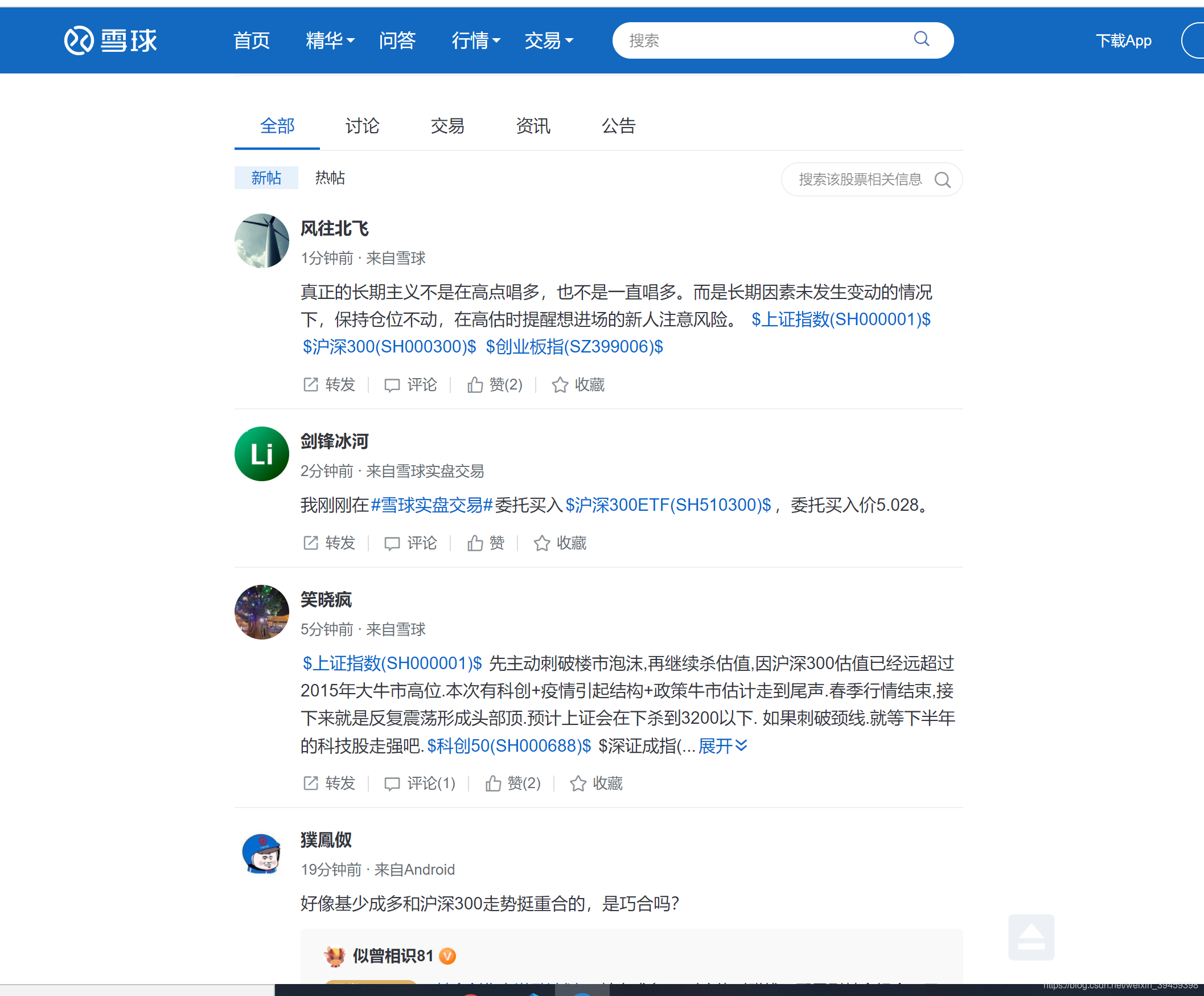
二、分析雪球网的网站
网站结构如上图所示,我原本的思路是希望正常的通过Xpath解析得到需要的部分,但是我们试着看看网站的评论,你会发现它是一个动态刷新的过程,并不是网页一打开就有了。而且要是经常点击下一页评论,你会尴尬地发现刷新不出来。
不过不用慌,要是看过这篇博客Python爬虫第四课:Network、XHR、json的同学基本上就知道怎么解决这个问题了(一定一定要看!里面技术问题和细节非常清楚)
-
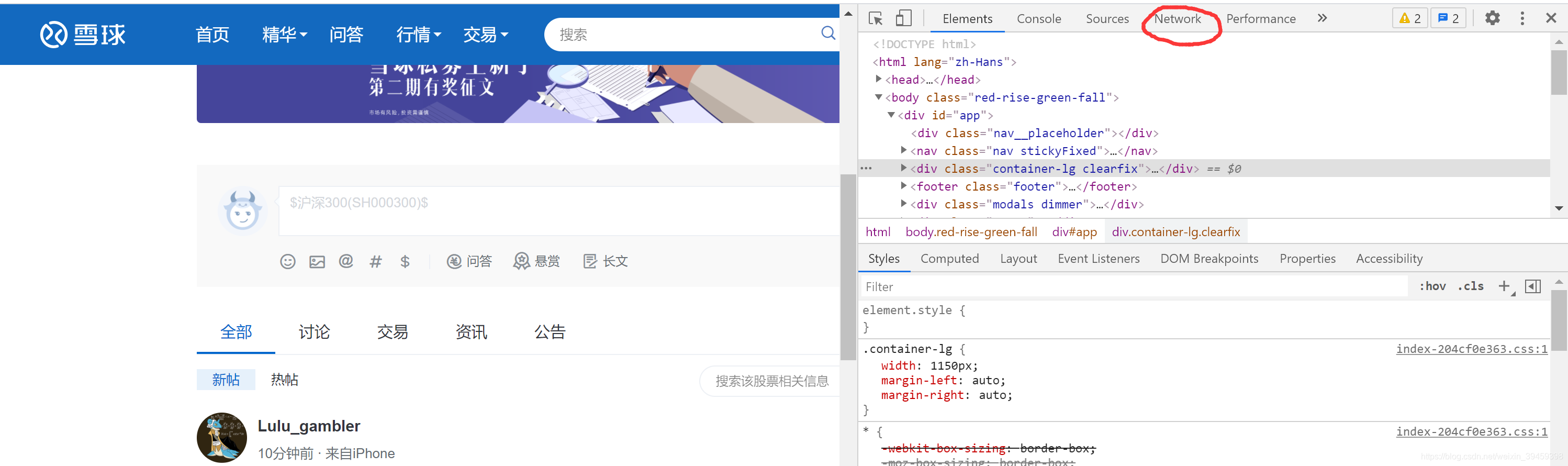
我们打开在网页空白处,点击右键-检查,第一个是Elements,往右看就能找到Network
-
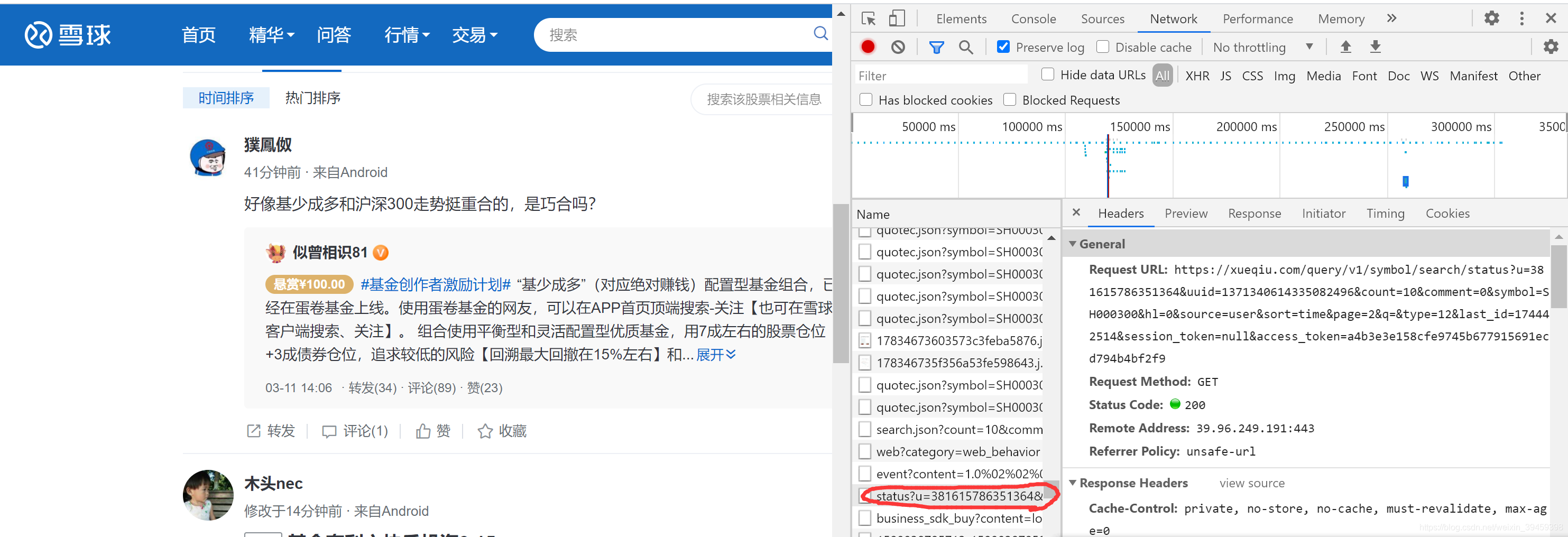
我们随便点击讨论或者是下一页的评论,会发现多出很多链接,同时我们对每一条链接都分析看看,会发现一个(红圈)的链接,右键 Open in new tab
-
会出现两种情况:
一种是{"code":501,"message":"超出请求限制","success":false}
第二种就是一大堆json数据
分别代表着一个数据访问失败,另一个访问成功
同时我们对访问成功的数据进行分析,会发现数据就是所要的评论数据
来段代码康康
import requests
import time
from fake_useragent import UserAgent
import re
import pandas as pd
ua = UserAgent()
headers = {'user-agent':ua.random}
data_list=[]
#对数据提取重要部分,评论文本,评论时间
def get_comment(data):
#data = json.load()
pinglun_len = len(data["list"])
i = 0
print(pinglun_len)
#data_list.clear()
while i < pinglun_len:
temp_data = data["list"][i]
# url = base_url+temp_data["target"]
pre = re.compile('>(.*?)<')
text = ''.join(pre.findall(temp_data['text']))
# text = temp_data['text']
timeBefore = temp_data['timeBefore']
data_list.append([text, timeBefore])
#print(text , timeBefore)
i += 1
url = 'https://xueqiu.com/query/v1/symbol/search/status?u=381615786351364&uuid=1371340614335082496&count=10&comment=0&symbol=SH000300&hl=0&source=user&sort=time&page=2&q=&type=12&last_id=174442514&session_token=null&access_token=a4b3e3e158cfe9745b677915691ecd794b4bf2f9'
flag = 0
#访问的次数
#因为可能存在多次访问都不能得到数据
times = 0
while flag == 0:
response = requests.get(url, headers=headers)
temp = response.json()
if 'code' in temp:#访问失败
time.sleep(0.5)
else:#访问成功,不用再访问,跳出循环
flag = 1
times += 1
# print(times)
get_comment(temp)
data_csv = pd.DataFrame(data_list)
data_csv.to_csv("./data_test.csv", encoding="utf_8_sig", index=False)
okk看看输出的结果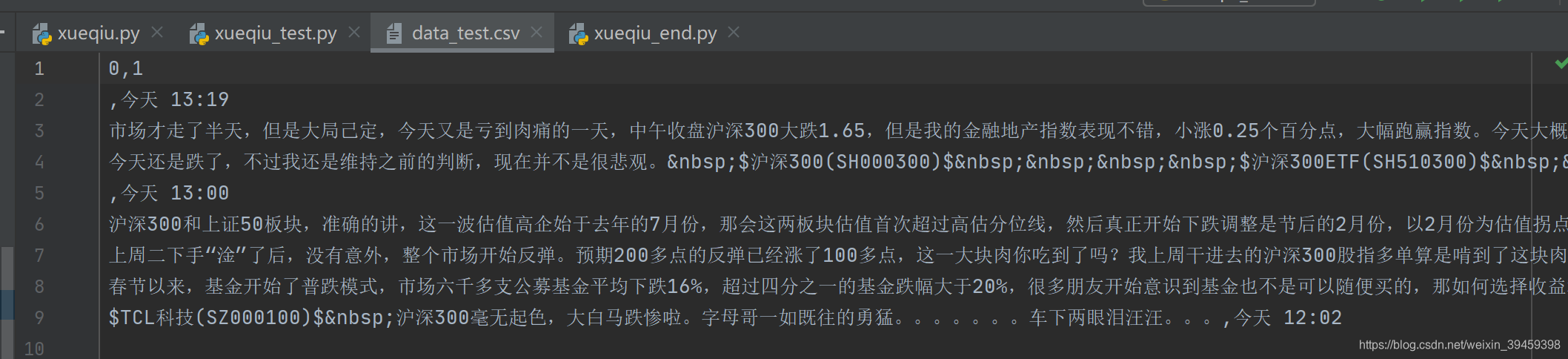
基本上我们已经实现了单页评论的爬取,那我们怎么实现多页呢?
三、多页评论爬取
大家有没有发现我们的链接其实是一条带参数请求数据(不懂赶紧看那篇博客 *六、拿到周杰伦所有歌曲清单 *)
url = 'https://xueqiu.com/query/v1/symbol/search/status?u=381615786351364&uuid=1371340614335082496&count=10&comment=0&symbol=SH000300&hl=0&source=user&sort=time&page=2&q=&type=12&last_id=174442514&session_token=null&access_token=a4b3e3e158cfe9745b677915691ecd794b4bf2f9'
#我们把url的链接 & 每个都分开,会得到下面下面这样
'https://xueqiu.com/query/v1/symbol/search/status?
u=381615786351364&
uuid=1371340614335082496&
count=10&
comment=0&
symbol=SH000300&
hl=0&
source=user&
sort=time&
page=2&
q=&
type=12&
last_id=174442514&
session_token=null&
access_token=a4b3e3e158cfe9745b677915691ecd794b4bf2f9'
如果这样看的话,会很明显发现这是一条由不同参数组成的链接
因为我们这个是要实现多页爬虫,你会发现一个很重要的参数就是page!也就是说我们只要修改下page 的参数就能实现自动访问新的页面数据了!
此处我们看到URL显得又臭又长,一方面是不方便观看,另一方面是不方便修改。要怎么才能优雅又美观的实现呢?
requests模块里的requests.get()提供了一个参数叫params,可以让我们用字典的形式,把参数传进去。
https://blog.csdn.net/fightingoyo/article/details/104563419 还是这个博客
import requests
import time
from fake_useragent import UserAgent
import re
import pandas as pd
ua = UserAgent()
headers = {'user-agent':ua.random}
data_list=[]
def get_comment(data):
#data = json.load()
pinglun_len = len(data["list"])
i = 0
print(pinglun_len)
#data_list.clear()
while i < pinglun_len:
temp_data = data["list"][i]
# url = base_url+temp_data["target"]
pre = re.compile('>(.*?)<')
text = ''.join(pre.findall(temp_data['text']))
# text = temp_data['text']
timeBefore = temp_data['timeBefore']
data_list.append([text, timeBefore])
#print(text , timeBefore)
i += 1
#这里修改了!
url='https://xueqiu.com/query/v1/symbol/search/status'
#这里取决于你要爬多少页,目前我只要爬9,最大可以调到100
for i in range(1,10):
params={
"u": 381615786351364,
"uuid": 1371340614335082496,
"count": 10,
"comment": 0,
"symbol": "SH000300",
"hl": 0,
"source": "user",
"sort": "time",
"page": i,#是这里做循环
"q":"" ,
"type": 12,
"last_id":174442514,
"session_token":"null",
"access_token": "a4b3e3e158cfe9745b677915691ecd794b4bf2f9"
}
flag = 0
#访问的次数
times = 0
while flag == 0:
response = requests.get(url, params=params ,headers=headers)
temp = response.json()
if 'code' in temp:
time.sleep(0.5)
else:
flag = 1
times += 1
print(times)
get_comment(temp)
data_csv = pd.DataFrame(data_list)
data_csv.to_csv("./data_test_plus.csv", encoding="utf_8_sig", index=False)
代码更改的地方不多,其实就是加了循环和params实现了多页爬虫
五、多只股票爬虫
上部分要是弄得非常清楚的话,这部分已经做完了,因为这部分的关键是我怎么实现多股票爬虫。
在沪深300ETF中每一只股票是有自己的一个编号的,其实就是在参数那一块会发现"symbol": "SH000300",我们只用自己修改这部分即可实现多只股票爬虫。两层循环即可实现:第一层:股票symbol 第二层是页数page
代码如下,但是还需要一个沪深300成分股.xlsx,这可以在我的github上下载
import requests
import time
import fake_useragent
from fake_useragent import UserAgent
import json
import re
import pandas as pd
ua = UserAgent()
headers = {'user-agent':ua.random}
data_list=[]
file = pd.read_excel("./沪深300成分股.xlsx")
def get_comment(data):
#data = json.load()
pinglun_len = len(data["list"])
i = 0
print(pinglun_len)
#data_list.clear()
while i < pinglun_len:
temp_data = data["list"][i]
# url = base_url+temp_data["target"]
pre = re.compile('>(.*?)<')
text = ''.join(pre.findall(temp_data['text']))
# text = temp_data['text']
timeBefore = temp_data['timeBefore']
data_list.append([text, timeBefore])
#print(text , timeBefore)
i += 1
url='https://xueqiu.com/query/v1/symbol/search/status'
for gupiao_index in range(0,300):
print(format(file["股票代码"][gupiao_index],"06"),"START")
data_list.clear()
for i in range(1,101):
params={
"u": 271614261599941,
"uuid": 1364939774078627840,
"count": 20,
"comment": 0,
#"symbol": "SH601607",
"symbol": "SH"+format(file["股票代码"][gupiao_index],"06"),
"hl": 0,
"source": "all",
"sort": "time",
"page": i,
"q":"" ,
"type": 11,
"session_token":"null",
"access_token": "62effc1d6e7ddef281d52c4ea32f6800ce2c7473"
}
#是否正常得到数据
flag = 0
#访问的次数
times = 0
while flag == 0:
response = requests.get(url, params,headers=headers)
temp = response.json()
if 'code' in temp:
time.sleep(0.5)
else:
flag = 1
times += 1
#print(times)
get_comment(temp)
print("Page {} OK!".format(i))
data_csv = pd.DataFrame(data_list)
data_csv.to_csv("./data_沪深300/{}_data_{}.csv".format(gupiao_index,params["symbol"]),encoding="utf_8_sig",index=False)
print(format(file["股票代码"][gupiao_index], "06"), "END")
最后
因为本博客没有使用多线程和分布式爬虫,所以爬虫速度会比较慢。
但是!我们可以多个程序设置不同页面一起跑 嘿嘿(主要是太懒了当时项目急着要数据,智能赶紧先实现 这可能就是dirty but work )
最后的最后,就简单介绍下我们课题,
本课题旨在研究VIX、投资者恐慌情绪和沪深300ETF收益率这三个变量组成的系统,探究变量之间的冲击关系,同时研究COVID-19疫情对其的影响。
这爬虫只是基于我们大创课题下面的一小部分工作,我们需要爬虫得到评论数据,对数据进行下一步情感分析处理,构造投资者恐慌情绪。对我们课题还有兴趣的可进一步了解github

















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









