







 XPath是XML路径语言,用于定位XML文档中的元素。本文介绍了XPath的基础语法,包括节点类型、路径表达式、属性选择等,并通过实例展示了如何正确使用XPath选择元素,如选取特定节点、后代节点、属性等。还提到了常见错误及其解决方案,以及contains函数的应用。
XPath是XML路径语言,用于定位XML文档中的元素。本文介绍了XPath的基础语法,包括节点类型、路径表达式、属性选择等,并通过实例展示了如何正确使用XPath选择元素,如选取特定节点、后代节点、属性等。还提到了常见错误及其解决方案,以及contains函数的应用。
XPath 即 XML 路径语言(XML Path Language),它是一种用来确定 xml 文档中某部分位置的语言。
xml 文档( html 属于 xml )是由一系列节点构成的树,例如:
Hello Python
Click here
xml 文档的节点有多种类型,其中最常用的有以下几种:
- 根节点 整个文档树的根。
- 元素节点 html、body、div、p、a。
- 属性节点 href。
- 文本节点 Hello Python、Click here。
节点间的关系有以下几种:
- 父子 body 是 html 的子节点,p 和 a 是 div 的子节点,反过来 div 是 p 和 a 的父节点。
- 兄弟 p 和 a 为兄弟节点。
- 祖先/后裔 body、div、p、a 都是 html 的后裔节点;反过来 html 是 body、div、p、a 的祖先节点。
01 基础语法
以下表格列出了 XPath 常用的基本语法。
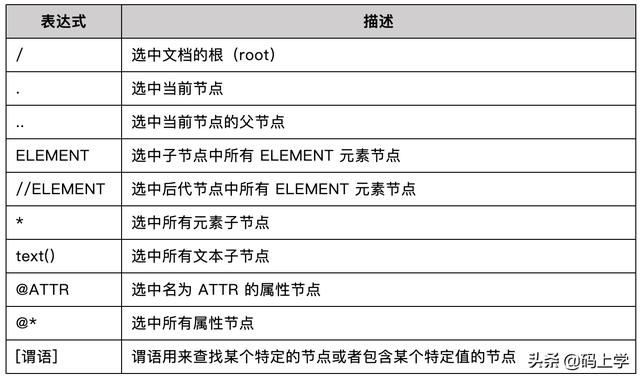
接下来,我们通过一些例子展示 XPath 的使用。
首先创建一个用于演示的 html 文档,并用其构造一个 HTMLResponse 对象:
>>> from scrapy.selector import Selector>>> from scrapy.http import HtmlResponse>>> body = '''... ... ... ... Hello Scrapy... ... ... ... Name:Image 1 ![]() ... Name:Image 2
... Name:Image 2 ![]() ... Name:Image 3
... Name:Image 3 ![]() ... Name:Image 4
... Name:Image 4 ![]() ... Name:Image 5
... Name:Image 5 ![]() ...
...
... ... ... '''>>> >>> response = HtmlResponse(url="http://www.example.com",body=body,encoding='utf8')
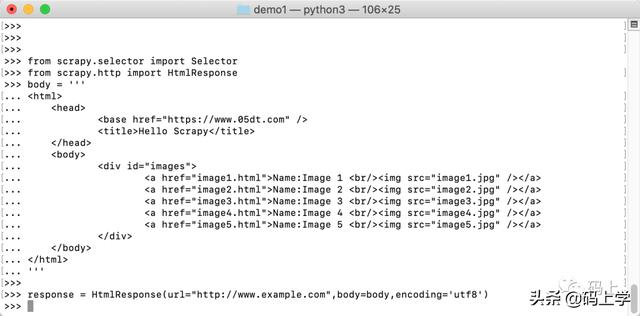
- /: 描述一个从根开始的绝对路径。
>>> response.xpath('/html')[]>>> response.xpath('/html/head')[] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3034
3034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









