






前言
最近,因个人兴趣做了一点视频类的项目实践,部分流程需要GPU服务器,所以写一篇文章记录一下购买GPU服务器后,需要做的一些操作。
首先,因为各种模型的资源主要在海外,所以一开始选择AWS上的GPU,但因为有soft limit(AWS避免用户不小心使用这些比较贵的资源,需要申请,才能创建相应的EC2实例类型,申请需要时间),所以又换回了阿里云。
阿里云购买方式很简单,选择对应的GPU机器,然后勾选安装CUDA环境,这样阿里云在初始化实例化会自动帮我们安装好CUDA这些基础环境,方便我们搭建深度学习环境。
我的配置是:
ubuntu 22.04
GPU A10
硬盘100G
大概11块钱一小时。
设置http代理
国内的服务器下载海外资源是很慢的,之前我在 [国内服务器如何下载海外资源](https://mp.weixin.qq.com/s/-qeuaT5GMOdoIaz90XFBjQ)一文中提过解决方案,这次也依旧用这种方式,最为简单。
首先,开启阿里云1080端口,用于设计proxy。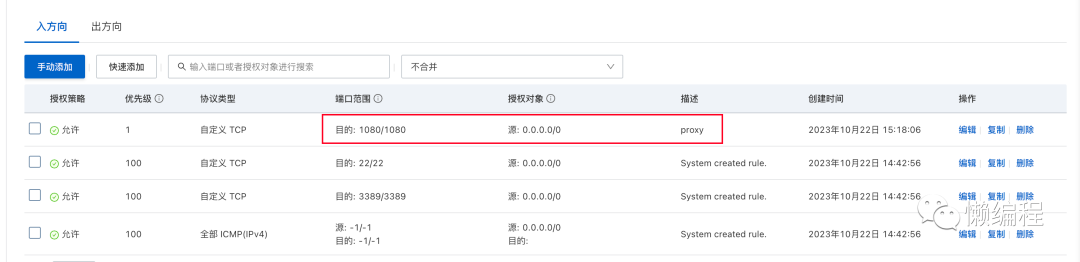
然后在本地(我的是Mac,所以命令是Unix的,如果你是windows可能需要调整)通过ssh命令开启远程流量转发。
ssh -i ~/.ssh/rsa_key -fnqgNTR server_ip:1080:localhost:7890 root@server_ip因为ssh默认只能监听localhost,需要开启GatewayPorts才能监听其他ip,所以我们需要改一下配置文件。
> vim /etc/ssh/sshd_config
# GatewayPorts: no
------ 改成 -----
GatewayPorts: yes然后在服务器上设置http与https的proxy,则可使用MacOS的代理来访问海外资源,从而提升下载速度了。
export http_proxy="127.0.0.1:1080"
export https_proxy="127.0.0.1:1080"可以通过curl -vv http://www.google.com命令判断一下http_proxy是否生效。
设置conda代理
很多AI项目都建议使用anaconda来安装环境,访问download url:https://www.anaconda.com/download
找到你的平台,比如ubuntu就是Linux平台。

复制链接,在服务器上,使用wget命令下载,因为设置了proxy,所以下载速度不错:
wget https://repo.anaconda.com/archive/Anaconda3-2023.09-0-Linux-x86_64.sh下载后,执行命令安装,conda init相关的都选yes,这个shell脚本就会帮你弄好所有的设置。
base Anaconda3-2023.09-0-Linux-x86_64.sh安装后,再设置一下conda的proxy,毕竟conda默认从海外拉资源,要设置conda proxy,首先需要先创建.condarc文件:
vim ~/.condarc然后在文件中,写入如下配置:
proxy_servers:
http: http://127.0.0.1:1080
https: http://127.0.0.1:1080
ssl_verify: false这样conda获取资源速度也会比较快了。
下载google云盘上的资源
很多项目会将自己的模型放到gogle云盘上,一般我们下载到MacOS本地,然后再通过scp将模型上传到服务器上,另外一个方法就是使用gdown(https://github.com/wkentaro/gdown)。
具体可以看gdown的文档,主要是学习一下怎么获得资源在google云盘上的唯一id,然后就可以通过gdown去下载了。

基础命令
我一般会使用vscode的ssh功能去链接服务器,这样可以直接通过类似GUI的形式访问项目中的各种文件,也方便我修改代码。
此外,我还会安装一下小工具帮助我管理服务器。
apt update
apt install jnettop htopjnettop:流量查看工具,通过它可以看到某些软件在拉取数据时,网络情况。比如某些流程卡主了,就可以看看,是不是在拉取网络数据,从而判断是不是因为网络问题导致这里卡主了,我感觉在国内这样的开发环境,快速的判断网络是否ok是一个硬技能...
htop:top工具增强版,动态查看当前活跃的、占用资源高的进程。有一些项目,启动预测时,但从命令行看,似乎卡死了,此时就可以开新的窗口,然后通过htop查看CPU使用情况,从而判断项目是不是在running。
结尾
以上就是我对阿里云GPU服务器会做的常规操作。
今天还体验了一下,怎么扩容,一开始默认买的是40G磁盘空间的服务器,实践3~4个项目,磁盘空间就满了,进行了扩容,阿里云有相应的视频教程,很清晰。
整体而已,除了受限于国内网络问题,阿里云还是挺好用的。
















 2959
2959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











