





这里讲述处理不平衡数据集和提高机器学习模型性能的各种技巧和策略,涵盖的一些技术包括重采样技术、代价敏感学习、使用适当的性能指标、集成方法和其他策略。都是py代码哦~~ 写的很狂飙~~
不平衡数据集是指一个类中的示例数量与另一类中的示例数量显著不同的情况。例如在一个二元分类问题中,一个类只占总样本的一小部分,这被称为不平衡数据集。类不平衡会在构建机器学习模型时导致很多问题。
不平衡数据集的主要问题之一是模型可能会偏向多数类,从而导致预测少数类的性能不佳。这是因为模型经过训练以最小化错误率,并且当多数类被过度代表时,模型倾向于更频繁地预测多数类。这会导致更高的准确率得分,但少数类别得分较低。
另一个问题是,当模型暴露于新的、看不见的数据时,它可能无法很好地泛化。这是因为该模型是在倾斜的数据集上训练的,可能无法处理测试数据中的不平衡。
在本文中,我们将讨论处理不平衡数据集和提高机器学习模型性能的各种技巧和策略。将涵盖的一些技术包括重采样技术、代价敏感学习、使用适当的性能指标、集成方法和其他策略。通过这些技巧,可以为不平衡的数据集构建有效的模型。
处理不平衡数据集的技巧
重采样技术是处理不平衡数据集的最流行方法之一。这些技术涉及减少多数类中的示例数量或增加少数类中的示例数量。
欠采样可以从多数类中随机删除示例以减小其大小并平衡数据集。这种技术简单易行,但会导致信息丢失,因为它会丢弃一些多数类示例。
过采样与欠采样相反,过采样随机复制少数类中的示例以增加其大小。这种技术可能会导致过度拟合,因为模型是在少数类的重复示例上训练的。
SMOTE是一种更高级的技术,它创建少数类的合成示例,而不是复制现有示例。这种技术有助于在不引入重复项的情况下平衡数据集。
代价敏感学习(Cost-sensitive learning)是另一种可用于处理不平衡数据集的技术。在这种方法中,不同的错误分类成本被分配给不同的类别。这意味着与错误分类多数类示例相比,模型因错误分类少数类示例而受到更严重的惩罚。
在处理不平衡的数据集时,使用适当的性能指标也很重要。准确性并不总是最好的指标,因为在处理不平衡的数据集时它可能会产生误导。相反,使用 AUC-ROC等指标可以更好地指示模型性能。
集成方法,例如 bagging 和 boosting,也可以有效地对不平衡数据集进行建模。这些方法结合了多个模型的预测以提高整体性能。Bagging 涉及独立训练多个模型并对它们的预测进行平均,而 boosting 涉及按顺序训练多个模型,其中每个模型都试图纠正前一个模型的错误。
重采样技术、成本敏感学习、使用适当的性能指标和集成方法是一些技巧和策略,可以帮助处理不平衡的数据集并提高机器学习模型的性能。
在不平衡数据集上提高模型性能的策略
收集更多数据是在不平衡数据集上提高模型性能的最直接策略之一。通过增加少数类中的示例数量,模型将有更多信息可供学习,并且不太可能偏向多数类。当少数类中的示例数量非常少时,此策略特别有用。
生成合成样本是另一种可用于提高模型性能的策略。合成样本是人工创建的样本,与少数类中的真实样本相似。这些样本可以使用 SMOTE等技术生成,该技术通过在现有示例之间进行插值来创建合成示例。生成合成样本有助于平衡数据集并为模型提供更多示例以供学习。
使用领域知识来关注重要样本也是一种可行的策略,通过识别数据集中信息量最大的示例来提高模型性能。例如,如果我们正在处理医学数据集,可能知道某些症状或实验室结果更能表明某种疾病。通过关注这些例子可以提高模型准确预测少数类的能力。
最后可以使用异常检测等高级技术来识别和关注少数类示例。这些技术可用于识别与多数类不同且可能是少数类示例的示例。这可以通过识别数据集中信息量最大的示例来帮助提高模型性能。
在收集更多数据、生成合成样本、使用领域知识专注于重要样本以及使用异常检测等先进技术是一些可用于提高模型在不平衡数据集上的性能的策略。这些策略可以帮助平衡数据集,为模型提供更多示例以供学习,并识别数据集中信息量最大的示例。
不平衡数据集的练习
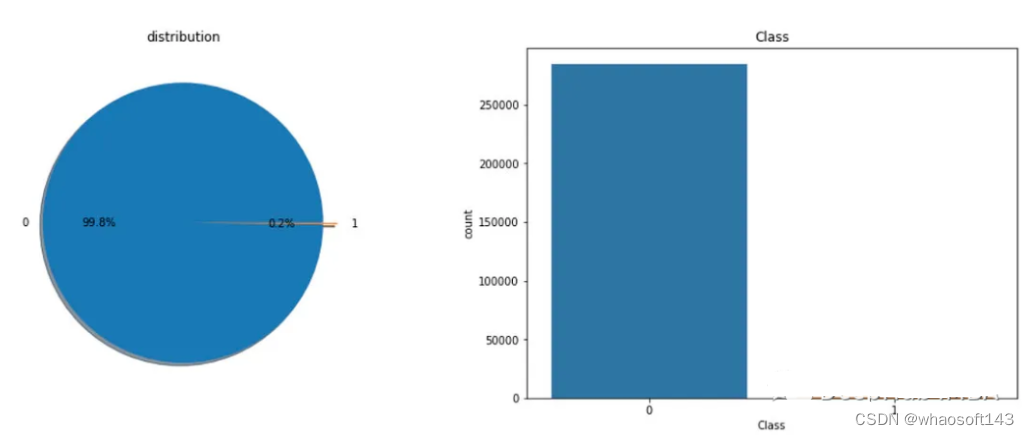
这里我们使用信用卡欺诈分类的数据集演示处理不平衡数据的方法
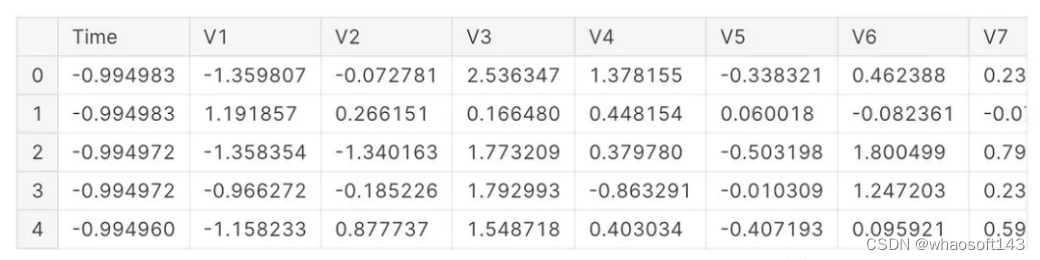
读取数据:
查看数据集信息:
查看分类类别:
创建基类模型:
我们创建的模型的准确率评分为0.999。我们可以说我们的模型很完美吗?混淆矩阵是一个用来描述分类模型的真实值在测试数据上的性能的表。它包含4种不同的估计值和实际值的组合。
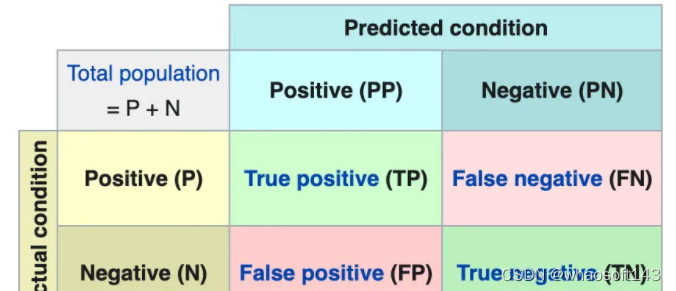
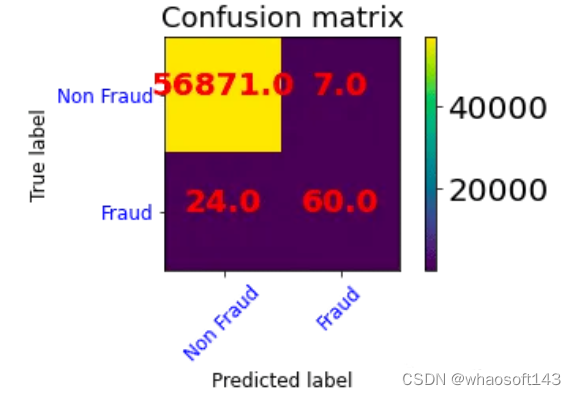
- 非欺诈类共进行了56875次预测,其中56870次(TP)正确,5次(FP)错误。
- 非欺诈类共进行了56875次预测,其中56870次(TP)正确,5次(FP)错误。
- 欺诈类共进行了87次预测,其中31次(FN)错误,56次(TN)正确。
该模型可以预测欺诈状态,准确率为0.99。但当检查混淆矩阵时,欺诈类的错误预测率相当高。也就是说该模型正确地预测了非欺诈类的概率为0.99。但是非欺诈类的观测值的数量高于欺诈类的观测值的数量,这拉搞了我们对准确率的计算,并且我们更加关注的是欺诈类的准确率,所以我们需要一个指标来衡量它的性能。
选择正确的指标
在处理不平衡数据集时,选择正确的指标来评估模型的性能非常重要。传统指标,如准确性、精确度和召回率,可能不适用于不平衡的数据集,因为它们没有考虑数据中类别的分布。
经常用于不平衡数据集的一个指标是 F1 分数。F1 分数是精确率和召回率的调和平均值,它提供了两个指标之间的平衡。计算如下:
F1 = 2 * (precision * recall) / (precision + recall)
另一个经常用于不平衡数据集的指标是 AUC-ROC。AUC-ROC 衡量模型区分正类和负类的能力。它是通过绘制不同分类阈值下的TPR与FPR来计算的。AUC-ROC 值的范围从 0.5(随机猜测)到 1.0(完美分类)。
返回对0(非欺诈)类的预测有多少是正确的。查看混淆矩阵,56870 + 31 = 56901个非欺诈类预测,其中56870个预测正确。0类的精度值接近1 (56870 / 56901)
返回对1 (欺诈)类的预测有多少是正确的。查看混淆矩阵,5 + 56 = 61个欺诈类别预测,其中56个被正确估计。0类的精度为0.92 (56 / 61),可以看到差别还是很大的
过采样
通过复制少数类样本来稳定数据集。
随机过采样:通过添加从少数群体中随机选择的样本来平衡数据集。如果数据集很小,可以使用这种技术。可能会导致过拟合。randomoverampler方法接受sampling_strategy参数,当sampling_strategy = ' minority '被调用时,它会增加minority类的数量,使其与majority类的数量相等。
我们可以在这个参数中输入一个浮点值。例如,假设我们的少数群体人数为1000人,多数群体人数为100人。如果我们说sampling_strategy = 0.5,少数类将被添加到500
采样后训练

应用随机过采样后,训练模型的精度值为0.97,出现了下降。但是从混淆矩阵来看,模型的欺诈类的正确估计率有所提高。
SMOTE 过采样:从少数群体中随机选取一个样本。然后,为这个样本找到k个最近的邻居。从k个最近的邻居中随机选取一个,将其与从少数类中随机选取的样本组合在特征空间中形成线段,形成合成样本。
使用SMOTE后的数据训练

可以看到与基线模型相比,欺诈的准确率有所提高,但是比随机过采样有所下降,这可能是数据集的原因,因为SMOTE采样会生成心的数据,所以并不适合所有的数据集。
总结
在这篇文章中,我们讨论了处理不平衡数据集和提高机器学习模型性能的各种技巧和策略。不平衡的数据集可能是机器学习中的一个常见问题,并可能导致在预测少数类时表现不佳。
本文介绍了一些可用于平衡数据集的重采样技术,如欠采样、过采样和SMOTE。还讨论了成本敏感学习和使用适当的性能指标,如AUC-ROC,这可以提供更好的模型性能指示。
处理不平衡的数据集是具有挑战性的,但通过遵循本文讨论的技巧和策略,可以建立有效的模型准确预测少数群体。重要的是要记住最佳方法将取决于特定的数据集和问题,为了获得最佳结果,可能需要结合各种技术。因此,试验不同的技术并使用适当的指标评估它们的性能是很重要的。















 4087
4087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









