






1.在linux系统创建文件 vi aa.txt --------i 进行编辑 输入 内容(多个单词例如:aa bb cc aa)
2.在HDFS上面创建文件夹 hdfs dfs -mkdir /cc ------------hdfs dfs -ls
3.将本地文件放到hdfs上面 hdfs dfs -put aa.txt /cc ---------------------hdfs dfs -ls /cc
4.hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /cc/put.txt /jiegou/jg1
5.hdfs dfs -cat /jiegou/jg1/part-r-00000
如下图:






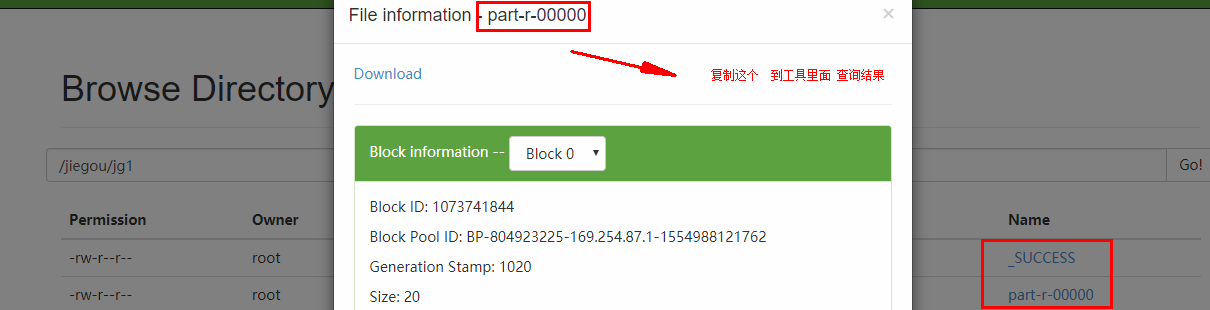
root@linux01 mapreduce]# hdfs dfs -cat /jiegou/jg1/part-r-00000

=======================================================================================================================================================

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









