






3D-HEVC编码框架
3D-HEVC编码结构是对HEVC的扩展,每个视点纹理及深度图编码主要采用HEVC编码框架,但在其基础上增加了一些新的编码技术,使其更有利于深度图和多视点的编码。
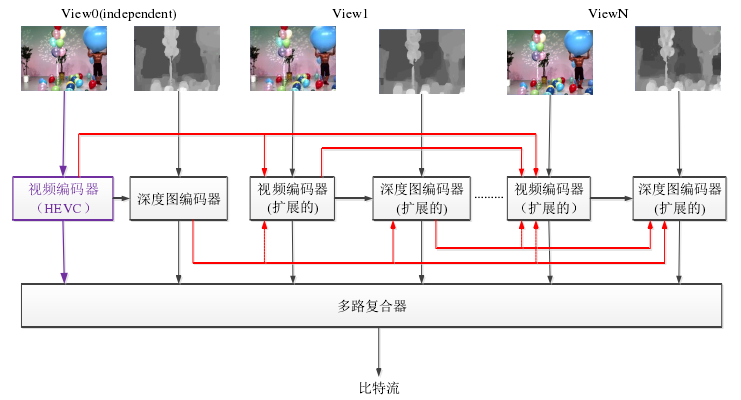
图1 3D-HEVC编码结构
如上图所示,3D-HEVC编解码结构和MVC类似。图中所有输入的视频图像和深度图像是同一时刻,不同拍摄位置的场景,这些图像组成一个存取层。在同一个存取层中,首先对独立视点(基准视点)编码,接着是该视点的深度图,再编码其他视点视频图像和深度图。原理上来说,每个视点的图像,包括视频图像和深度图像,均可以利用HEVC编码框架进行编码,输入的所有比特流复合形成3D比特流。
对于独立视点,利用未修正的HEVC编码结构,由于该视点的编码是独立的,不依赖于其他视点,因此其对应的比特流可以单独提取出来形成2D比特流,从而恢复出2D视频。由此可见,3D-HEVC兼容了2D视频的编解码。而其他视点和深度图采用修正的HEVC编码结构。如图中红色箭头表明可以利用视点间相似信息来去除视点间冗余,提高编码性能。
非独立视点编码技术
3D-HEVC在编码非独立视点时,除了使用独立视点编码所用的所有工具外,还用到了HEVC关于3D扩展的编码技术,使其更有利于多视点的编码。比如利用已编码的独立视点的信息来预测当前编码视点的信息,从而降低视点间冗余,提高编码效率。其中涉及的扩展技术主要是视差补偿预测,视点间运动预测和视点间冗余预测。
视差补偿预测
视差补偿预测(DCP)是非独立视点编码中一个重要的编码技术,视差补偿和运动补偿具有相似概念,均可理解为帧间预测的一种方法,但两者的参考帧存在本质区别。运动补偿预测(MCP)的参考帧是不同时刻,同一视点的编码帧,而DCP参考的是同一时刻,不同视点的已编码帧。由于DCP和MCP类似,因此DCP被添加到MCP列表中,作为MCP的一种预测模式。在宏块级的语法和解码过程中均没有修改,仅对高级语法元素进行了改进,从而可以将同一存取层已编码的视点图像加入到参考列表中。
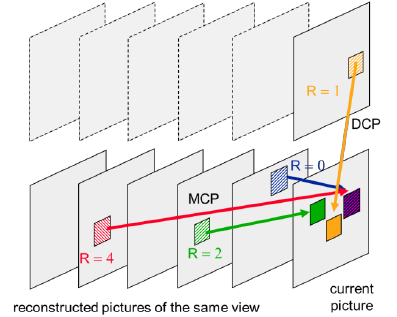
图2 视差补偿预测和运动补偿预测
如上图所示,引用图像索引(R值)来区别MCP和DCP,即当R=1时表示DCP,其余表示MCP。
视点间运动预测
多视点视频是在同一时刻同一场景下,多个camera从不同角度拍摄的视频,不同视点呈现的物体运动具有相似性。因此可以利用同一时刻已编码视点的运动信息来预测当前视点的运动信息。
关于视点间运动预测的一种方法是一帧图像的所有块均使用恒定的视差矢量。为了更有效确定当前块与参考视点中相应块之间的关系,还可以利用深度图信息更准确的预测当前视点和参考视点之间的关系。
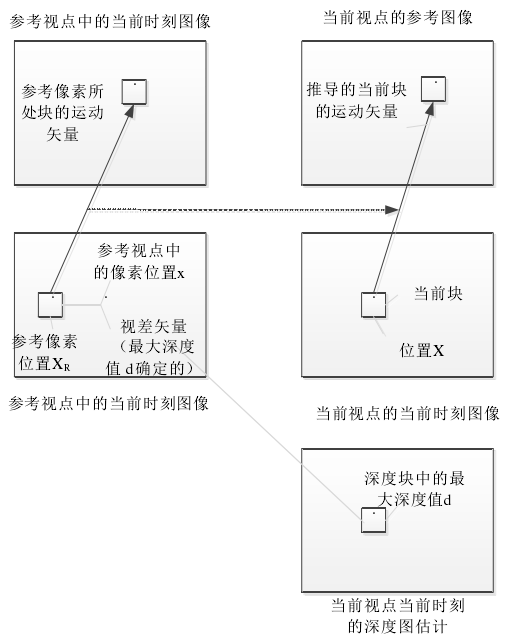
图3 基于参考视点的运动参数推导当前编码视点的运动参数
如上图所示,假设当前图像的深度图已给出或能够估计出,则将当前编码块的最大深度值转化成视差矢量。对于当前块的中心位置X加上已得到的视差矢量,从而得到参考视点中的位置XR,若XR是利用运动补偿预测进行编码的,则相关的运动矢量可以用作当前视点编码块运动信息的参考。同理,利用当前块的最大深度值推导出的视差矢量可以用于DCP。
视点间冗余预测
同一存取层的已编码图像的运动信息和冗余信息可以用来提高非独立视点的编码性能。为了利用视点间的冗余信息,在编码块之间的语法元素中添加一个标志信息用来表示该预测块是否利用了视点间冗余预测。视点间冗余预测过程和视点间运动矢量预测过程类似:
1.首先根据图3中的最大深度转化为视差矢量。
2.然后根据视差矢量确定在参考视点中的位置,得到该位置的冗余信息。
3.最后将当前块的冗余和预测的冗余差进行编码。若冗余信息是基于分像素的,则应该对参考视点的冗余信息进行插值滤波。

图4 视差冗余预测结构
如上图所示,Dc表示当前视点(View1)编码块,Bc和Dr分别表示同一时刻(Tj)参考视点(View0)对应的块和不同时刻(Ti)同一视点(View1)中对应的块,且VD是Dc和Dr之间的运动信息。由于Bc和Dc分别是同一时刻下,不同视点同一个物体的投射,因此两个块的运动信息应该是相同的。所以Bc的时域预测块Br可以通过VD进行确定,反之Bc的冗余信息和运动信息VD也可以通过加权因子映射到Dc。
深度图编码
一般而言,所有用于视频图像的编码技术均可用作深度图编码,但是HEVC的设计目的是视频序列编码最优,对深度图的编码并不是最优。而与视频序列相比,深度图的特征是具有大块相同区域以及尖锐的边缘信息。
3D-HEVC的深度图帧内编码在视频编码的基础上增加了四种模式,分为两类:用直线分割的楔形分割法(Wedegelets)和用任意形状分割的轮廓分割法(Contours)。深度图编码将一个深度块分割为两个非矩形区域,每个区域用一个常数表示。为了能够表示出分割信息,至少应该确定两个元素参数,分别用于表示属于哪个区域的参数以及该区域恒定的常数。
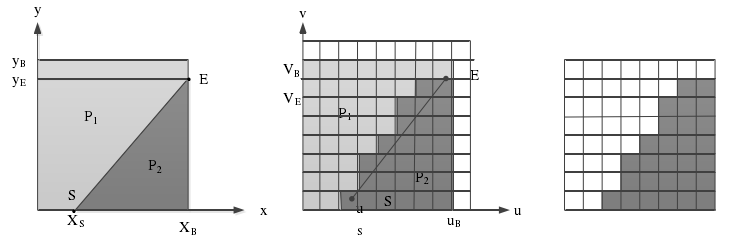
图5 楔形分割模式
如上图所示,楔形分割和轮廓分割的主要区别在于分割的方式不同。对于楔形分割,一个深度块的两个区域是通过一条直线分割的,分割的两个区域分别为P1和P2,分割线由起始位置S和终止位置E表示。从图5中可得,对于模拟信号(左图),可以采用线性函数来表示分割线。而中间图则描述了离散信号的分割,该块是一个uB*vB大小的采样矩阵,起始点S和结束点E对应于采样矩阵的边界值,用于表示分割线的位置。对于编码过程中的楔形分割,分割模式将被存储下来,其存储的信息包括uB*vB大小的一个矩阵,矩阵中的每个元素是一个二进制信息,表示当前块的采样值属于P1还是P2。右图表示为分割好的预测块,其中白色部分表示P1区域,黑色部分表示P2区域。
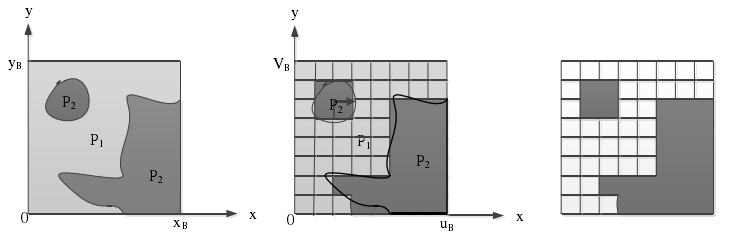
图6 轮廓分割模式
如上图所示,轮廓分割法的分割线不能像楔形分割法一样能够用一个几何函数表示出来。而P1和P2可以是任意形状的,甚至可以分成多个部分。同时在分割方式上,轮廓分割和楔形分割很大程度上是相似的。
除了分割信息需要传输,还要求传送第i个分割号的区域深度值,每个分割的区域深度值是一个固定的数,该值最好的选择应该是该区域原始深度值的均值。
因此根据分割模式和传输信息不同,深度图新增的帧内编码模式分为四种方法:
1.明确的楔形法:在编码端确定最佳匹配的分割,并且在比特流中传输分割信息,利用传输的分割信息,解码端可以重建该块的信号。
2.帧内预测楔形法:通过相邻已编码的帧内块预测当前块的楔形分割,传输一个修正值。
3.元素间楔形法:当前块的分割信息通过重建块的co-located块,即该块和当前编码块在同一图像中,推导得到。
4.元素间轮廓法:通过重建的co-located块推导得到两个任意形状的区域分割。

















 2366
2366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









