






Hash链表的应用比较常见,其目的就是为了将不同的值映射到不同的位置,查找的时候直接找到相应的位置,而不需要传统的顺序遍历或是二分查找,从而达到减少查询时间的目的。常规的hash是预定义一定的桶(bucket),规定一个hash函数,然后进行散列。然而Mysql中的hash没有固定的bucket,hash函数也是动态变化的,本文就进行非深入介绍。
基本结构体
Hash的结构体定义以及相关的函数接口定义在include/hash.h和mysys/hash.c两个文件中。下面是HASH结构体的定义。
成员名
说明
key_offset
hash时key的offset,在不指定hash函数的情况下有意义
key_length
key的长度,用于计算key值
blength
非常重要的辅助结构,初始为1,动态变化,用于hash函数计算,这里理解为bucket length(其实不是真实的bucket数)
records
实际的记录数
flags
是否允许存在相同的元素,取值为HASH_UNIQUE(1)或者0
array
存储元素的数组
get_key
用户定义的hash函数,可以为NULL
free
析构函数,可以为NULL
charset
字符集
成员名
说明
buffer
一块连续的地址空间,用于存储数据,可以看成一个数组空间
elements
元素个数
max_element
元素个数上限
alloc_increment
当元素达到上限时,即buffer满时,按照alloc_increment进行扩展
size_of_element
每个元素的长度
初始化函数
Hash初始化函数对外提供两个,my_hash_init和my_hash_init2,其区别即是否定义了growth_size(用于设置DYNAMIC_ARRAY的alloc_increment)。代码在mysys/hash.c中。
动态HASH函数
my_hash_key参数
说明
hash
HASH链表结构
record
带插入的元素的值
length
带插入元素的值长度
first
辅助参数
my_hash_mask参数
说明
hashnr
my_hash_key的计算结果
buffmax
hash结构体中的blength
maxlength
实际桶的个数
你可能要问我怎么有两个?其实这和我们平时使用的差不多,第一个函数my_hash_key是根据我们的值进行HashKey计算,一般我们在计算后,会对hash key进行一次模运算,以便计算结果在我们的bucket中。即my_hash_key的结果作为my_hash_mask的第一个输入参数。其实到这里都是非常好理解的,唯一让我蛋疼的是my_hash_mask的实现,其计算结果是和第二和第三个参数有关,即Hash结构体中的blength和records有关。动态变化的,我去..
看到这里我迷惑了,我上网经过各种百度,谷歌,终于让我找到了一封Mysql Expert的回信:
红色注释的地方是重点,dynamic hash,原来如此,动态hash,第一次听说,在网上下了个《Dynamic Hash Tables》的论文,下面图解下基本原理。
动态Hash的本质是Hash函数的设计,图中给出的动态hash函数只是论文中提到的一个例子。下面就具体解读下Mysql中的hash插入——my_hash_insert
my_hash_insert非深入解析
首先给出my_hash_insert的源代码,代码在mysys/hash.c中。
同时给出动态hash函数如下:
可以看出,hash函数是hash key与buffmax的模运算,buffmax即HASH结构中的blength,由my_hash_insert中最后几行代码可知:info->blength+= info->blength; 其初始值为1,即blength = 2^n,而且blengh始终是大于records。这个动态hash函数的基本意思是key%(2^n)。依然用图解这个动态hash函数。
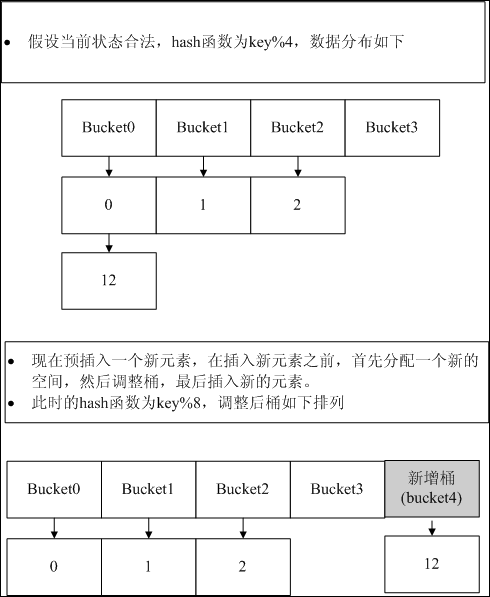
hash函数基本清楚了,但是mysql的具体实现还是比较值得探讨的。那封回信中也提到了without empty slots,是的,它这种实现方式是根据实际的数据量进行桶数的分配。我这里大概说下代码的流程(有兴趣的还需要大家自己仔细琢磨)。
根据flag去判断是否是否唯一Hash,如果是唯一Hash,去查找Hash表中是否存在重复值(dupliacate entry),存在则报错。
进行桶分裂,对应代码中的if (idx != info->records)分支。这个分支有些费解,稍微提示下:gpos和ptr_to_rec指示了低位需要移动的数据,gpos2和ptr_to_rec2只是了高位需要移动的数据。LOWFIND表示低位存在值,LOWUSED表示低位是否进行了调整。HIGH的宏意义基本相同。if (!(hash_nr & halfbuff)) 用于判断hash值存在高位还是低位。
计算新值对应的bucket号,插入。如果此位置上存在元素(一般情况都存在,除非是empty,概率比较小),调整原始元素的位置。















 1909
1909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









