







简介:Apache Spark是一个高效的大数据处理框架,它通过内存计算提高了数据处理速度,并且支持批处理、交互式查询、流处理和机器学习等任务。本文将详细解析Spark的架构、主要组件、编程模型、部署模式和性能优化方法,以及其在Jupyter Notebook中的应用。通过深入了解Spark,读者将获得使用这个强大的工具来处理不同类型数据问题的能力。
1. Spark简介和核心优势
1.1 Spark是什么?
Apache Spark是一个开源的分布式计算系统,它提供了一个快速通用的数据处理平台。与传统的MapReduce相比,Spark能够更加有效地执行基于内存的计算,使得数据处理速度更快,能够处理批量数据、实时数据流以及交互式查询。
1.2 Spark的核心优势
Spark的核心优势体现在以下几个方面:
- 速度 :Spark的内存计算能力比Hadoop MapReduce快100倍以上,磁盘I/O也有显著提升。
- 易用性 :支持多种编程语言,包括Scala、Java、Python,使得开发者可以轻松上手。
- 通用性 :Spark提供了用于处理数据流、批处理、机器学习和图计算的API,是一个全面的数据处理工具。
- 容错性 :基于RDD的容错机制能够有效地处理错误和恢复数据。
通过以上优势,Spark已经成为大数据处理领域的重要工具之一,尤其在对实时计算要求较高的场景中应用广泛。在未来的章节中,我们将更深入地探讨Spark的架构、组件以及如何在实际工作中应用和优化这一强大的计算框架。
2. Spark架构与主要组件解析
2.1 Spark运行架构概述
2.1.1 驱动程序(Driver Program)的角色和功能
在Apache Spark的运行架构中,驱动程序(Driver Program)扮演着至关重要的角色。它是启动Spark作业的入口点,同时也是整个应用的指挥中心。
驱动程序包含以下主要组件:
- 任务调度器 :负责将应用中的转换操作和行动操作转换为执行计划,并分配给执行器执行。
- Spark上下文 (SparkContext):作为与Spark集群的连接,负责通信,并为应用配置资源。
- 分布式数据集 (RDD)操作:维护应用中的数据集及其依赖关系,并在必要时重新计算部分数据集。
驱动程序通常运行在客户端机器上,并通过集群管理器与工作节点交互。在本地模式下,驱动程序也可以运行在提交作业的机器上。
2.1.2 集群管理器(Cluster Manager)的种类及特点
集群管理器负责资源的分配和任务调度。Spark支持多种集群管理器,主要有:
- Standalone :Spark自带的集群管理器,适用于小型和中型集群,配置简单,易于管理。
- YARN :Hadoop的资源管理器,可实现资源的共享,适合大规模集群和与Hadoop生态系统的整合。
- Mesos :一种通用的集群管理器,能运行各种类型的工作负载,但配置较为复杂。
- Kubernetes :作为一种新兴的容器编排系统,Kubernetes逐渐成为主流的云原生应用部署和管理平台,Spark在Kubernetes上的支持也越来越成熟。
每种集群管理器都有其独特的资源分配和调度机制,用户可以根据具体需求和环境选择最合适的集群管理器。
2.2 工作节点(Worker Nodes)的组件构成
2.2.1 执行器(Executor)的工作原理
执行器(Executor)是在工作节点上运行的长期存在的进程。其主要功能包括:
- 任务执行 :执行器运行应用代码,并返回结果给驱动程序。
- 内存管理 :存储持久化数据集(RDD)以及执行并行操作。
- 任务调度 :在接收到驱动程序的任务后,执行器会进行任务调度和执行。
执行器通过与驱动程序的通信保持同步,执行器的数量和大小可以通过配置调整。
2.2.2 资源管理与任务调度机制
Spark的任务调度机制是其架构的核心部分之一,主要包括以下几个方面:
- 资源调度 :集群管理器负责向执行器分配资源,包括CPU核心和内存。
- 任务调度 :驱动程序中的任务调度器将任务分配给执行器。
- 任务执行顺序 :基于任务依赖关系和可用资源,调度器确定任务执行顺序。
Spark支持基于FIFO和公平调度策略的调度机制。公平调度器允许多个应用共享集群资源,实现资源的公平使用。
graph TD
A[客户端提交Spark应用] -->|创建SparkContext| B[驱动程序启动]
B --> C[任务调度器制定执行计划]
C --> D[集群管理器分配资源]
D -->|资源分配给| E[执行器启动]
E -->|执行任务并返回结果| B
style B fill:#f9f,stroke:#333,stroke-width:4px
在上述的mermaid流程图中,我们看到了从客户端提交Spark应用到集群管理器分配资源给执行器,并由执行器执行任务后返回结果给驱动程序的过程。这是Spark运行架构的核心流程,其中驱动程序和执行器是主要参与者。
请注意,以上内容仅为第二章“Spark架构与主要组件解析”章节的第二部分“工作节点(Worker Nodes)的组件构成”的一部分。根据要求,章节二的内容需要不少于2000字,因此,请确保整章节内容的扩展和深化,以便满足字数要求。
3. Spark技术栈核心组件深入
3.1 Spark Core的核心概念
3.1.1 RDD的创建、转换与行动操作
弹性分布式数据集(RDD)是Spark Core的核心数据结构,它是分布在一组节点上可以并行操作的数据集合。RDD有两个主要操作类型:转换(transformations)和行动(actions)。
RDD创建
RDD可以由两种方式创建:一种是通过读取外部存储系统的数据,如HDFS文件系统;另一种是通过在驱动程序中对集合进行并行化操作。代码示例如下:
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
RDD转换操作
转换操作是惰性的,意味着它们不会立即执行,而是会等待行动操作的触发,这样可以有效地构建计算图。转换操作包括 map() , filter() , flatMap() 等。例如:
val doubles = distData.map(x => x * 2)
RDD行动操作
行动操作会触发实际的计算并返回结果给驱动程序。行动操作包括 collect() , count() , reduce() 等。例如,获取所有元素的总和:
val sum = doubles.reduce(_ + _)
3.1.2 广播变量与累加器的作用与应用
广播变量和累加器是两种共享变量,它们在Spark作业中用于高效的数据共享和聚合。
广播变量
广播变量允许程序员缓存一个只读变量在工作节点上,而不是为每个任务发送一份副本,这在需要将数据分发到每个节点时非常有用。代码示例如下:
val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar.value
累加器
累加器是一个仅用于“添加”操作的变量,比如计数器和求和,它可以在工作节点之间进行累积操作。代码示例如下:
val accum = sc.longAccumulator("Sum Accumulator")
distData.foreach(x => accum.add(x))
accum.value
3.1.3 RDD持久化与内存管理
RDD持久化(或称为缓存)是Spark中一个重要的性能优化手段。当一个RDD被标记为持久化,其会被保存在内存中,以便之后的行动操作能够更快速地访问。代码示例如下:
doubles.persist()
doubles.count()
doubles.unpersist()
3.1.4 RDD分区和任务调度
在Spark中,数据被自动分区,任务被调度到这些分区上执行。可以通过 partitionBy() 方法自定义RDD的分区方式,分区数可以通过 repartition() 或 coalesce() 方法进行调整。
3.2 高级组件功能概览
3.2.1 Spark SQL的SQL查询优化
Spark SQL是用于处理结构化数据的Spark组件,它允许开发者以SQL查询的方式读取、处理和存储数据。
SQL查询优化
为了提高查询性能,Spark SQL利用了多种策略,包括列式存储、项目下推、谓词下推和向量化执行。通过使用 explain() 方法,可以查看Spark如何执行SQL查询。
val df = spark.read.json("path/to/json/file")
df.createOrReplaceTempView("people")
val results = spark.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
results.show()
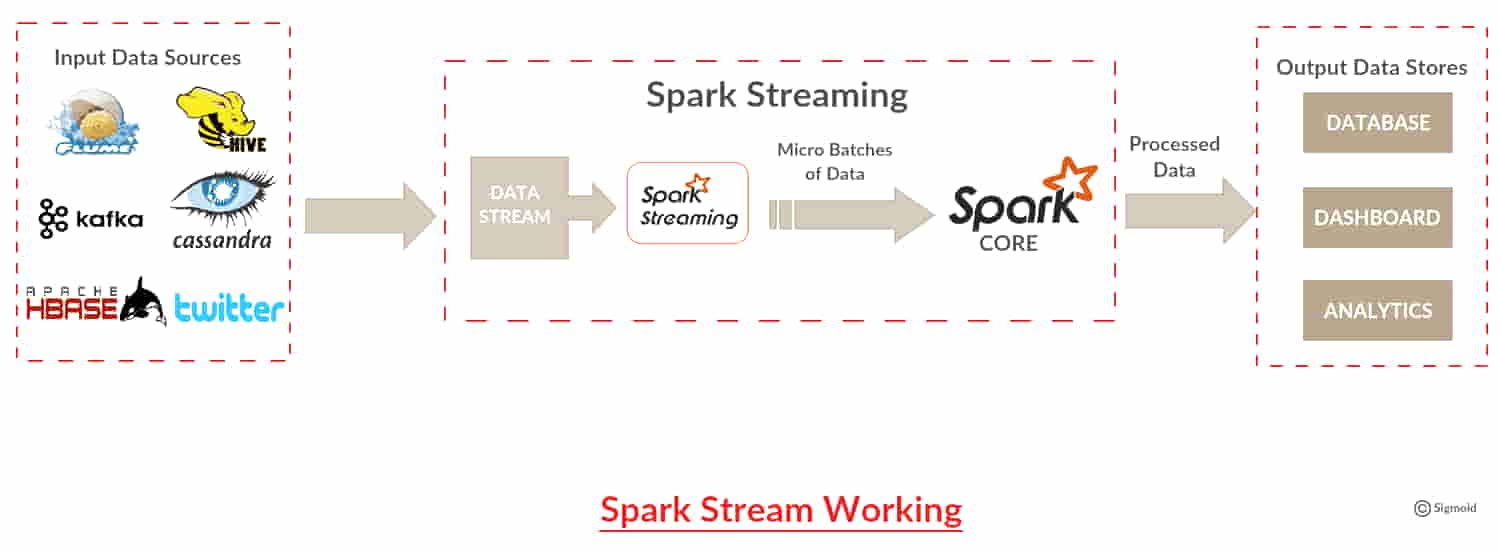
3.2.2 Spark Streaming的数据流处理机制
Spark Streaming可以处理实时数据流,它将实时数据流分解成一系列的小批次数据,然后应用Spark Core的转换操作。
数据流处理机制
数据流首先被接收器(receivers)收集,然后被转换为DStream,DStream是一系列的RDD。这种设计允许用户使用Spark Core的所有转换操作。示例代码如下:
val ssc = new StreamingContext(sc, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
3.2.3 MLlib机器学习库的基本使用
MLlib是Spark的机器学习库,提供了多种机器学习算法以及底层优化原语,这些算法可以用于分类、回归、聚类等任务。
基本使用
使用MLlib首先需要导入需要的算法包,然后创建相应的数据结构。比如使用逻辑回归进行分类:
import org.apache.spark.mllib.classification.LogisticRegressionWithSGD
val data = sc.textFile("path/to/mllib/input")
val parsedData = data.map { line =>
val parts = line.split(' ')
LabeledPoint(parts(0).toDouble, parts.tail.map(x => x.toDouble))
}
val model = LogisticRegressionWithSGD.train(parsedData)
parsedData.take(5).foreach(println)
3.2.4 GraphX图计算框架的特点
GraphX是Spark针对图计算的API,提供了强大的图并行计算能力,可应用于社交网络分析、推荐系统等。
图计算框架
GraphX将图数据抽象为顶点和边的集合,并引入了属性图的概念。它内置了图并行操作的丰富接口,如三角形计数、PageRank等。代码示例:
import org.apache.spark.graphx._
val vertexArray = Array((1L, ("Alice", 28)), (2L, ("Bob", 27)),
(3L, ("Charlie", 65)), (4L, ("David", 42)),
(5L, ("Ed", 55)), (6L, ("Fran", 50)))
val vertexRDD = sc.parallelize(vertexArray)
val edgeArray = Array Edge(2L, 1L, 7), Edge(2L, 4L, 2),
Edge(3L, 2L, 4), Edge(3L, 6L, 3),
Edge(4L, 1L, 1), Edge(5L, 2L, 22),
Edge(5L, 3L, 5), Edge(5L, 6L, 15))
val edgeRDD = sc.parallelize(edgeArray)
val graph = Graph(vertexRDD, edgeRDD)
GraphX中包含了多种图运算的高级操作,比如PageRank:
val ranks = graph.pageRank(0.0001).vertices
这些核心组件是Spark强大的基石,它们共同构成了Spark的大数据处理生态系统,为不同层次的数据分析提供了丰富多样的工具和接口。在接下来的章节中,我们将深入探讨Spark的编程语言支持和部署模式,以及性能优化和生态系统拓展。
4. Spark编程语言与部署模式
4.1 支持的编程语言及环境配置
4.1.1 Scala、Python、Java在Spark中的应用
Apache Spark自诞生以来,就致力于提供一个快速、通用且高效的计算平台。为了满足不同开发者的使用习惯和业务需求,Spark支持多种编程语言,其中最核心和最广泛使用的语言是Scala、Python和Java。
-
Scala :作为Spark的原生语言,Scala以其简洁优雅的语法和强大的类型系统,在Spark社区中占据着核心地位。由于Spark底层基于Scala的函数式编程特性,用Scala编写的Spark程序往往能够更加简洁和直观,能够充分利用Spark的高级抽象,如RDD和DataFrame。不仅如此,许多Spark的API在设计时都是以Scala为中心的,这使得Scala成为想要充分利用Spark能力的最佳选择。
-
Python :Python的简洁语法和强大的社区支持使其在数据科学领域非常流行。Spark通过PySpark模块提供了对Python的支持,这使得数据分析师和数据科学家能够利用Python进行大规模数据处理。PySpark不仅保留了Python的易用性,还通过Apache Arrow等技术优化了性能,使得Python用户能够无缝地处理大数据。
-
Java :对于已经熟悉Java语言的开发者来说,Spark同样提供了良好的支持。通过使用Java,开发者可以利用Java丰富的库和成熟的开发工具链。虽然Spark的某些高级抽象可能在Java中不如Scala那么直观,但Java的稳定性和广泛的应用场景,特别是在企业级应用中,依然使得Java成为Spark开发的一个重要选择。
// 示例代码:用Scala编写Spark程序
val spark = SparkSession.builder()
.appName("Scala Example")
.getOrCreate()
val data = Seq(1, 2, 3, 4, 5)
val dataFrame = spark.createDataFrame(data.map(Tuple1.apply)).toDF("number")
dataFrame.show()
spark.stop()
在上述Scala示例代码中,创建了一个简单的DataFrame,展示了如何使用SparkSession创建DataFrame并进行展示。这不仅体现了Scala在Spark中的简洁性,也展现了其对数据处理的高效性。
# 示例代码:用Python编写Spark程序
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("Python Example") \
.getOrCreate()
data = [1, 2, 3, 4, 5]
data_frame = spark.createDataFrame(data, ["number"])
data_frame.show()
而在Python示例代码中,我们使用了PySpark库来完成相同的操作。通过这个例子,可以看到Python代码同样简洁,并且因为使用了pandas风格的DataFrame API,对于数据科学家来说非常友好。
对于Java的支持,以下是使用Java API进行Spark编程的示例代码:
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
public class JavaExample {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder()
.appName("Java Example")
.getOrCreate();
JavaSparkContext sc = new JavaSparkContext(spark.sparkContext());
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> rdd = sc.parallelize(data);
spark.createDataFrame(rdd.map(t -> new Tuple1(t)), Encoders.tuple(Encoders.INT()).schema()).show();
}
}
这个Java示例展示了如何创建一个简单的RDD,并将其转换为DataFrame。可以看出,虽然在语法上比Scala更为繁琐,但Java编写的Spark代码同样具有高度的可读性和可维护性。
4.1.2 集成开发环境(IDE)的选择与配置
在进行Spark应用的开发时,选择一个合适的集成开发环境(IDE)能够大大提高开发效率。以下是三种流行的IDE及其配置方法:
-
IntelliJ IDEA :作为Java开发者的首选IDE,IntelliJ IDEA在支持Scala和Python方面也做得非常出色。通过安装相应的插件,如Scala插件或PyCharm的Python支持,开发者可以轻松地在IDE中处理Spark项目。
-
PyCharm :专为Python设计,PyCharm对于数据科学和数据分析来说是一个很好的IDE选择。对于Spark项目,需要安装和配置PySpark,并且可能需要将PyCharm连接到一个运行中的Spark集群,以便运行和调试应用程序。
-
Eclipse :尽管在Java开发中非常流行,Eclipse对于Spark的支持主要依靠社区提供的插件。通过安装Scala IDE插件和配置Spark的依赖项,Eclipse也可以成为一个合适的开发环境。
<!-- pom.xml 中的 Maven 配置示例,以使用 IntelliJ IDEA -->
<dependencies>
<!-- Spark Core dependency -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.1</version>
</dependency>
<!-- Spark SQL dependency -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.1</version>
</dependency>
</dependencies>
在开发Spark应用程序时,通常会使用Maven或SBT作为构建工具,而IntelliJ IDEA完美集成了Maven和SBT。因此,许多开发者更倾向于使用IntelliJ IDEA来开发Spark应用程序。上述Maven配置示例展示了如何在 pom.xml 中添加Spark Core和SQL模块的依赖。
配置IDE后,开发者可以开始编写代码、运行本地测试,并最终将应用部署到集群上。正确配置IDE和构建工具是高效Spark开发的关键。
4.2 Spark的多部署模式实操
4.2.1 本地模式的搭建与运行
在本地模式下,Spark应用程序可以在单个节点上运行,这对于开发、测试和小规模的实验性任务是非常有用的。搭建和运行本地模式的Spark非常简单:
- 下载并解压Spark到本地目录。
- 编写Spark应用程序代码。
- 使用
spark-submit命令提交应用程序到本地模式运行。
# spark-submit命令示例,提交本地运行
spark-submit \
--class "com.example.MyApp" \
--master local[4] \
/path/to/app.jar
在上面的命令中, --master local[4] 指定了应用程序将在本地模式下运行,并使用4个线程。 --class 指定了主类的名称,而 /path/to/app.jar 是打包好的应用程序jar文件路径。
4.2.2 Standalone、Mesos、YARN部署策略比较
Spark支持多种集群管理器,包括Standalone、Mesos和YARN。以下是每种部署策略的简要比较:
-
Standalone模式 :Spark自带的集群管理器,部署简单,且能够充分利用Spark自身的特性。适合小型组织或在没有Hadoop生态系统组件的环境中部署Spark。
-
Mesos模式 :Apache Mesos是一个通用的集群管理器,提供了更高的资源利用率和调度灵活性。Mesos能够管理Spark以及Hadoop MapReduce、Kafka等其他工作负载。对于需要混合多种计算框架的大型组织来说,这是一个较好的选择。
-
YARN模式 :作为Hadoop的资源管理器,YARN已经广泛部署在许多企业中。Spark在YARN上运行时,可以利用已有的Hadoop基础设施。这种方式适合已经在使用Hadoop并希望使用Spark进行数据处理的大型组织。
graph LR
A[用户代码] -->|编译打包| B[Spark运行时]
B -->|提交至| C[集群管理器]
C -->|任务调度| D[工作节点]
D -->|执行任务| E[数据]
style A stroke:#f66,stroke-width:2px
style B stroke:#f66,stroke-width:2px
style C stroke:#f66,stroke-width:2px
style D stroke:#f66,stroke-width:2px
style E stroke:#f66,stroke-width:2px
以上Mermaid流程图展示了一个Spark应用程序从编写、打包到部署执行的整个流程。图中表示了不同的Spark部署策略,强调了集群管理器在任务调度和资源分配中的关键作用。
# Spark配置文件示例
spark.master: "yarn"
spark.executor.memory: "4g"
spark.executor.cores: 2
如上所示的Spark配置文件片段,展示了如何在不同的部署模式下配置Spark运行时参数。对于YARN模式,需要指定 spark.master 为 yarn 。
4.2.3 Kubernetes环境下Spark的部署与管理
随着容器化技术的普及,越来越多的组织开始利用Kubernetes作为他们的容器编排工具。Apache Spark也支持在Kubernetes环境中运行,这使得Spark能够更好地与现代云原生架构集成。
部署Spark到Kubernetes的基本步骤如下:
- 准备Spark应用的Docker镜像。
- 创建Spark应用程序的Kubernetes部署配置文件。
- 使用
kubectl命令部署应用到Kubernetes集群。 - 监控和管理在Kubernetes上运行的Spark应用。
# Kubernetes部署配置文件示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: spark-app
spec:
replicas: 3
selector:
matchLabels:
app: spark-app
template:
metadata:
labels:
app: spark-app
spec:
containers:
- name: spark
image: my-spark-image:latest
ports:
- containerPort: 4040
在此YAML配置文件中,定义了Spark应用的Kubernetes部署,包含三个副本的 spark-app 。每个容器运行一个Spark实例,通过 kubectl apply -f 命令提交此配置文件后,Kubernetes将根据配置文件启动并运行Spark应用。
总之,通过本地模式可以方便快捷地进行Spark应用的开发和测试。而对于生产环境,Standalone模式、Mesos和YARN提供了强大的集群管理能力,适合于各种不同的应用场景。随着容器化和云原生架构的兴起,Kubernetes正在成为Spark部署的一个热门选项。
5. Spark性能调优与生态系统拓展
随着大数据量的持续增长和实时数据处理需求的提升,Spark作为大数据处理的领军框架,性能调优和生态系统的拓展变得至关重要。正确地调优Spark作业不仅可以提升数据处理速度,还能有效利用计算资源,降低成本。同时,Spark与其他大数据组件的集成,不仅丰富了其处理能力,也为构建完整的数据处理流程提供了可能。
5.1 Spark性能优化的实践技巧
性能优化可以从多个角度进行,包括硬件资源的充分利用、配置参数的合理设置,以及作业层面的优化。
5.1.1 硬件资源对Spark性能的影响
在任何大数据处理系统中,硬件资源的配置都对性能有着决定性的影响。对Spark而言,以下几点是需要重点考虑的:
- 内存大小 :执行器(Executor)的内存大小直接关系到任务执行的速度。通常,更大的内存可以缓存更多的数据,加快处理速度,但同时也要求更高配置的服务器。
- CPU核心数 :CPU核心数决定了可以并行处理的任务数。合理配置核心数可以确保Spark充分利用多核处理器的优势。
- 网络I/O :Spark在数据Shuffle阶段会进行大量的数据传输。因此,一个高速网络对于性能的提升至关重要。
- 磁盘I/O :虽然Spark主要基于内存计算,但在某些情况下,如数据倾斜,磁盘I/O性能也会成为瓶颈。
5.1.2 配置参数调优与作业优化策略
Spark提供了大量的配置参数供用户根据具体的应用场景进行优化。以下是一些关键的配置项和优化策略:
- spark.executor.memory :设置执行器的内存大小,确保有足够的内存用于数据处理和缓存。
- spark.executor.cores :设置执行器的核心数,这将影响到能并行运行的任务数量。
- spark.default.parallelism 和 spark.sql.shuffle.partitions :这两个参数控制了数据Shuffle操作中创建的分区数量,应根据数据量和资源情况适当调整。
- spark.speculation :启用推测执行机制,可以减少由于单个任务运行缓慢导致的作业延迟。
- 数据序列化 :使用高效的序列化库,如Kryo,可以减少内存占用,提升处理速度。
作业层面的优化策略包括:
- 减少Shuffle操作 :Shuffle操作是性能的瓶颈之一,应当尽可能减少不必要的Shuffle,例如通过优化Join操作。
- 广播大变量 :对于需要跨任务共享的大变量,使用广播变量可以减少内存的使用和网络传输。
- 使用持久化 :合理使用RDD的持久化功能,可以有效减少重复计算,加快后续操作的速度。
5.2 Spark生态系统组件集成
Spark作为一个强大的数据处理引擎,与各种生态系统组件的集成是其一大优势,下面介绍几个与Spark集成最紧密的组件。
5.2.1 HDFS在Spark中的使用与优势
Hadoop分布式文件系统(HDFS)是大数据存储的事实标准,而Spark与HDFS的集成具有以下优势:
- 兼容性强 :Spark原生支持HDFS,可以无缝对接。
- 性能提升 :Spark在HDFS上的读写操作可以被优化,从而提升整体性能。
- 容错机制 :利用HDFS的高容错性,Spark可以在遇到节点故障时快速恢复计算任务。
5.2.2 Spark与HBase、Kafka、Hive的集成示例与分析
-
Spark与HBase :HBase作为Hadoop生态中用于随机访问的NoSQL数据库,与Spark集成后可以进行实时的数据处理和分析。Spark可以利用HBase作为数据源和数据存储,尤其在需要实时处理大量小文件的场景中具有优势。
scala // Spark读取HBase数据的示例代码 val hbaseConf = HBaseConfiguration.create() val table = new Table(hbaseConf, "test") val scan = new Scan() val result = table.getScanner(scan) // 处理result中的数据 -
Spark与Kafka :Kafka作为分布式流式消息系统,与Spark Streaming的集成用于实时数据流处理非常高效。Spark Streaming可以读取Kafka的数据,进行实时的数据分析处理。
scala // Spark Streaming读取Kafka数据的示例代码 val kafkaParams = Map[String, String]("metadata.broker.list" -> "localhost:9092") val topics = Set("test") val stream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder]( ssc, kafkaParams, topics) // 处理stream中的数据
- Spark与Hive :Hive提供了一个数据仓库的基础架构,Spark通过HiveContext可以与Hive集成,利用Hive的元数据管理功能进行数据仓库的操作,特别适合进行复杂的数据分析任务。
scala // Spark通过HiveContext读取Hive表数据的示例代码 val hiveContext = new HiveContext(sc) val dataFrame = hiveContext.sql("SELECT * FROM hive_table") // 对dataFrame中的数据进行处理
以上各章节的深入探讨,展示Spark性能调优的实践技巧和如何将Spark与其他生态系统组件进行有效集成。掌握这些技巧和方法,可以帮助数据工程师和架构师进一步提升Spark项目的性能和效率。
简介:Apache Spark是一个高效的大数据处理框架,它通过内存计算提高了数据处理速度,并且支持批处理、交互式查询、流处理和机器学习等任务。本文将详细解析Spark的架构、主要组件、编程模型、部署模式和性能优化方法,以及其在Jupyter Notebook中的应用。通过深入了解Spark,读者将获得使用这个强大的工具来处理不同类型数据问题的能力。

















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









