






最近由于工作需要所以开始学习opencl,由于刚毕业不久所以只有c语言,c#的基础,写博文主要是给大部分和我一样准备学习opencl的菜鸟参考。
我的显卡是AMD公司的,所以先从AMD Opencl入手。
看了一些教程,因为都是从英文直接翻译过来的,感觉理解上有些费力,我觉得用图片理解起来方便一点。迈克老狼的博文都不错,大家可以参考下。

这个图演示了opencl编程的基本流程。
首先要创建平台对象Platform,然后创建GPU设备Device,然后创建上下文环境context,其次是创建command队列,接下来创建opencl内存对象,用来存放需要计算的输入和输出数据,创建kernel程序program对kernel代码进行编译,创建kernel对象,设置kernel参数并执行,将结果返回host并输出。
Context是指管理OpenCL对象和资源的上下文环境。为了管理OpenCL程序,下面的一些对象都要和Context关联起来:
—设备(Devices):执行Kernel程序对象。
—程序对象(Program objects): kernel程序源代码
—Kernels:运行在OpenCL设备上的函数。
—内存对象(Memory objects): device处理的数据对象。
—命令队列(Command queues): 设备之间的交互机制。
GPU的优势在于并行计算,我们先看看OpenCL中的线程结构:
大规模并行程序中,通常每个线程处理一个问题的一部分,比如向量加法,我们会把两个向量中对应的元素加起来,这样每个线程可以处理一个加法。下面我看一个16个元素的向量加法:两个输入缓冲A、B,一个输出缓冲C,在这种情况下,我们可以创建一维的线程结构去匹配这个问题。每个线程把自己的线程id作为索引,把相应元素加起来。原理如下图。

OpenCL中的线程结构是可缩放的,Kernel的每个运行实例称作WorkItem(也就是线程),WorkItem组织在一起称作WorkGroup,OpenCL中,每个Workgroup之间都是相互独立的。
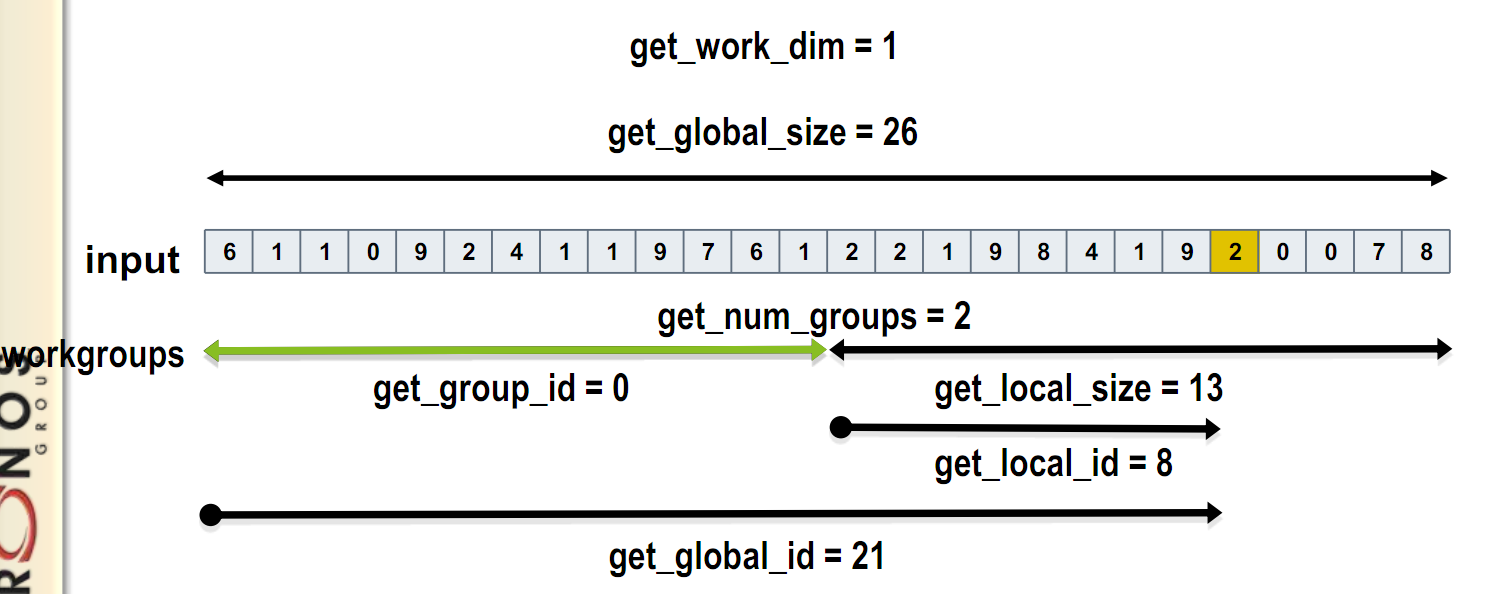
通过一个global id(在索引空间,它是唯一的)或者一个workgroup id和一个work group内的local id,就能标定一个workitem。如下图所示。

接下来用一个简单的程序演示一下:计算两个数组相加的和,放到另一个数组中去。为了简化代码方便理解,我们初始化数组buf1[]=buf2[]=0,1,2,3...并用cpu和gpu分别计算出结果进行验证。
代码如下:
#include <CL/cl.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <iostream>
#include <fstream>
using namespace std;
#define BUFSIZE 1024
#pragma comment (lib,"OpenCL.lib")
//该函数把kernel源文件读入到一个string中,用来读入kernel源文件,kernel源文件可以新建一个.cl文件单独存放。
int convertToString(const char *filename, std::string& s)
{
size_t size;
char* str;
std::fstream f(filename, (std::fstream::in | std::fstream::binary));
if(f.is_open())
{
size_t fileSize;
f.seekg(0, std::fstream::end);
size = fileSize = (size_t)f.tellg();
f.seekg(0, std::fstream::beg);
str = new char[size+1];
if(!str)
{
f.close();
return NULL;
}
f.read(str, fileSize);
f.close();
str[size] = '\0';
s = str;
delete[] str;
return 0;
}
printf("Error: Failed to open file %s\n", filename);
return 1;
}
//等待事件完成 ,通过event来查询我们的操作是否完成,没完成的话,程序就一直block在这行代码处,这个函数和clWaitForEvents其实效果一样,但是我发现在做有关图像的程序时最好用clWaitForEvents,不然会内存冲突造成蓝屏。
int waitForEventAndRelease(cl_event *event)
{
cl_int status = CL_SUCCESS;
cl_int eventStatus = CL_QUEUED;
while(eventStatus != CL_COMPLETE)
{
status = clGetEventInfo(
*event,
CL_EVENT_COMMAND_EXECUTION_STATUS,
sizeof(cl_int),
&eventStatus,
NULL);
}
status = clReleaseEvent(*event);
return 0;
}
int main(int argc, char* argv[])
{
//在host内存中创建三个缓冲区存放buf1,buf2,buf,buf1和buf2是输入数组,buf存放buf1和buf2的和。
int *buf1 = 0;
int *buf2 = 0;
int *buf = 0;
buf1 =(int *)malloc(BUFSIZE * sizeof(int));
buf2 =(int *)malloc(BUFSIZE * sizeof(int));
buf =(int *)malloc(BUFSIZE * sizeof(int));
//用一些随机值初始化buf1和buf2的内容,这里我们用0,1,2,3...
int i;
//srand( (unsigned)time( NULL ) );
for(i = 0; i < BUFSIZE; i++)
{
buf1[i] = i;
}
//srand( (unsigned)time( NULL ) +1000);
for(i = 0; i < BUFSIZE; i++)
{
buf2[i] = i;
}
//cpu计算buf1,buf2的和
for(i = 0; i < BUFSIZE; i++)
{
buf[i] = buf1[i] + buf2[i];
}
cl_uint status;
cl_platform_id platform;
//创建平台对象
//status = clGetPlatformIDs( 1, &platform, NULL );这行代码如果在只有一个平台的情况下可以使用,如果有多个opencl平台就会报错,就要使用如下的代码。
cl_uint numPlatforms;
std::string platformVendor;
status = clGetPlatformIDs(0, NULL, &numPlatforms);
if(status != CL_SUCCESS)
{
return 0;
}
if (0 < numPlatforms)
{
cl_platform_id* platforms = new cl_platform_id[numPlatforms];
status = clGetPlatformIDs(numPlatforms, platforms, NULL);
char platformName[100];
for (unsigned i = 0; i < numPlatforms; ++i)
{
status = clGetPlatformInfo(platforms[i],
CL_PLATFORM_VENDOR,
sizeof(platformName),
platformName,
NULL);
platform = platforms[i];
platformVendor.assign(platformName);
if (!strcmp(platformName, "Advanced Micro Devices, Inc."))
{
break;
}
}
std::cout << "Platform found : " << platformName << "\n";
delete[] platforms;
}
cl_device_id device;
//创建GPU设备
clGetDeviceIDs( platform, CL_DEVICE_TYPE_GPU,
1,
&device,
NULL);
//创建context
cl_context context = clCreateContext( NULL,
1,
&device,
NULL, NULL, NULL);
//创建命令队列
cl_command_queue queue = clCreateCommandQueue( context,
device,
CL_QUEUE_PROFILING_ENABLE, NULL );
//创建三个OpenCL内存对象,并把buf1的内容通过隐式拷贝的方式拷贝到clbuf1,buf2的内容通过显示拷贝的方式拷贝到clbuf2,这里只是告诉大家隐式和显式的代码的区别。
cl_mem clbuf1 = clCreateBuffer(context,
CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
BUFSIZE*sizeof(cl_uint),buf1,
NULL );
cl_mem clbuf2 = clCreateBuffer(context,
CL_MEM_READ_ONLY ,
BUFSIZE*sizeof(cl_uint),NULL,
NULL );
cl_event writeEvt;
status = clEnqueueWriteBuffer(queue, clbuf2, 1,
0, BUFSIZE*sizeof(cl_uint), buf2, 0, 0, &writeEvt);
status = clFlush(queue);
//等待数据传输完成再继续往下执行
waitForEventAndRelease(&writeEvt);
//clWaitForEvents(1, &writeEvt);
cl_mem buffer = clCreateBuffer( context,
CL_MEM_WRITE_ONLY,
BUFSIZE * sizeof(cl_uint),
NULL, NULL );
//kernel文件为add.cl
const char * filename = "add.cl";
std::string sourceStr;
status = convertToString(filename, sourceStr);
const char * source = sourceStr.c_str();
size_t sourceSize[] = { strlen(source) };
//创建程序对象
cl_program program = clCreateProgramWithSource(
context,
1,
&source,
sourceSize,
NULL);
//编译程序对象
status = clBuildProgram( program, 1, &device, NULL, NULL, NULL );
if(status != 0)
{
printf("clBuild failed:%d\n", status);
char tbuf[0x10000];
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0x10000, tbuf, NULL);
printf("\n%s\n", tbuf);
return -1;
}
//创建Kernel对象
cl_kernel kernel = clCreateKernel( program, "vecadd", NULL );
//设置Kernel参数
cl_int clnum = BUFSIZE;
clSetKernelArg(kernel, 0, sizeof(cl_mem), (void*) &clbuf1);
clSetKernelArg(kernel, 1, sizeof(cl_mem), (void*) &clbuf2);
clSetKernelArg(kernel, 2, sizeof(cl_mem), (void*) &buffer);
//执行kernel,首先要设置线程索引空间的维数以及workgroup大小等。Range用1维,work itmes size为BUFSIZE,没有设置group size时,系统会使用默认的work group size,通常可能是256
cl_event ev;
size_t global_work_size = BUFSIZE;
clEnqueueNDRangeKernel( queue,
kernel,
1,
NULL,
&global_work_size,
NULL, 0, NULL, &ev);
status = clFlush( queue );
waitForEventAndRelease(&ev);
//clWaitForEvents(1, &ev);
//当Kernel函数执行完毕后,我们要把数据从device memory中拷贝到host memory中去。
cl_uint *ptr;
cl_event mapevt;
ptr = (cl_uint *) clEnqueueMapBuffer( queue,
buffer,
CL_TRUE,
CL_MAP_READ,
0,
BUFSIZE * sizeof(cl_uint),
0, NULL, &mapevt, NULL );
status = clFlush( queue );
waitForEventAndRelease(&mapevt);
//clWaitForEvents(1, &mapevt);
//结果验证,和cpu计算的结果比较
if(!memcmp(buf, ptr, BUFSIZE))
printf("Verify passed\n");
else printf("verify failed");
if(buf)
free(buf);
if(buf1)
free(buf1);
if(buf2)
free(buf2);
printf("Result=\n");
for(int m=0;m<BUFSIZE;m++)
printf("%d ",ptr[m]);
cin.get();
//删除OpenCL资源对象,大多数的OpenCL资源都是指针,不使用的时候需要释放掉。
clReleaseMemObject(clbuf1);
clReleaseMemObject(clbuf2);
clReleaseMemObject(buffer);
clReleaseProgram(program);
clReleaseCommandQueue(queue);
clReleaseContext(context);
return 0;
}
kernel函数就是gpu的计算部分了,这个示例的代码很简单,如下:
__kernel void vecadd(__global const uint* A, __global const uint* B, __global uint* C)
{
int id = get_global_id(0);
C[id] = A[id] + B[id];
}
每个Kernel函数都必须以__kernel开始,而且必须返回void。每个输入参数都必须声明使用的内存类型。通过一些API,比如get_global_id之类的得到线程id。
内存对象地址空间标识符有以下几种:
__global
__local
__private
__constant
这四个分别对应了CL架构中的存储区域(设备全局、work group、compute unit 、设备constant)。目前global一定是constant的,也就是声明global时必须赋值 (global就等于 global constant),Kernel函数参数如果是内存对象,那么一定是__global,__local或者constant。
如图所示:get_global_id是获取总的线程数,比如设置kernel的work group size是256,数组大小为512,那就是有两个group,group_id[2]={0,1},每个group里面的线程的唯一id为local_id,local_size=group size。















 8267
8267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









