






文章链接:
https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/41159.pdf
补充:https://courses.cs.washington.edu/courses/cse599s/14sp/scribes/lecture20/lecture20_draft.pdf
- abstract
FTRL-proximal在线学习算法得到的模型更稀疏、收敛性质更佳,使用各坐标单独的学习率。
- introduction
扩展性问题
省内存、效果分析、置信度预估、校准、特征管理
- brief system overview
revenue = bid price * ctr
目标:预估ctr = P(click | q,a)
特征:query,ad creative text,ad metadata等
方法:regularized logistic regression(正则化逻辑回归,rLR)
平台:Photon(谷歌流式特征平台)
训练方式:DistBelief(谷歌训练平台),Downpour SGD
重点考虑:稀疏性、线上预估阶段延时
- online learning and sparsity
对于大规模在线学习,以LR为例的广义线性模型(generalized linear models)很有优势。十亿维特征,非零值只有几百维,每个样本只读一遍。
LogLoss(logistic loss):![]()
梯度:![]()
OGD(online gradient descent)适合此类问题,但难得到稀疏解。直接在loss上加L1惩罚不能得到稀疏解(?)
FOBOS和truncated gradient可得到稀疏解,RDA进一步平衡正确率和稀疏性。为了同时拥有RDA的稀疏性(sparsity)和OGD正确性(accuracy)提升,提出FTRL-Proximal。可简单理解为OGD上增加正则项,但是由于各维度独立更新参数w,因此方便引入L1正则。


lambda_1 = 0时两者得到相同参数向量序列,但FTRL-Proximal使用lambda_1 > 0很好地得到稀疏解。
迭代中每维只需要存一个值,更新w方式:

因此对比OGD保留w,FTRL-Proximal内存中只保留z。算法1额外增加了逐维学习率调整,并支持L2正则,存储-eta_t*z_t而非z_t

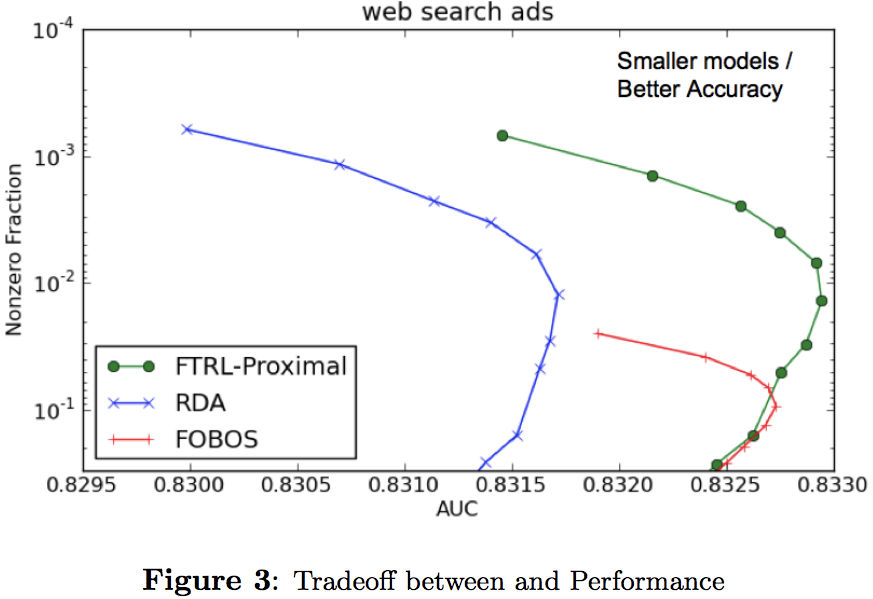
—— experimental results
FTRL-Proximal with L1显著优于RDA和FOBOS,并且很好平衡accuracy和model size。
每维参数不为零要求至少见过k次特征数值。
—— per-coordinate learning rates
逐维设定学习率显著提升效果(高频特征学习率低):
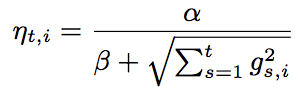
alpha最优值和数据有关,beta取1足够好。效果相对全局唯一学习率AucLoss下降11.2%。
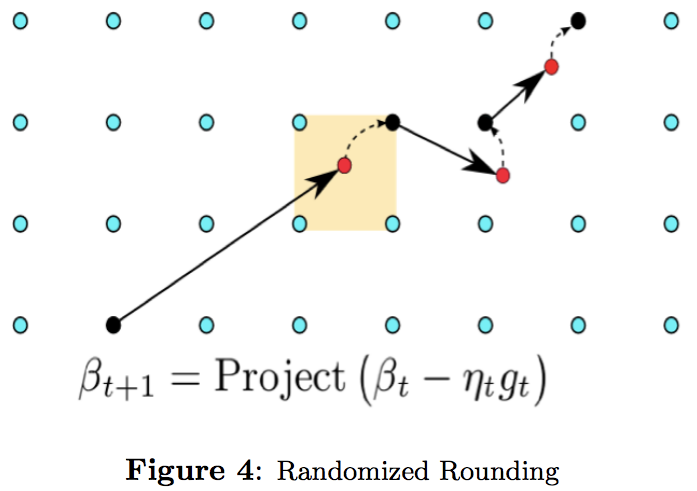
- saving memory at massive scale
包括相似item分组,randomized rounding,L1正则。
—— Probabilistic Feature Inclusion
有些模型情形,十亿级别样本中,一半特征数值只出现一次。
1)Poisson Inclusion:以概率p添加特征
2)Bloom Filter Inclusion:Counting Bloom Filter,设定阈值n
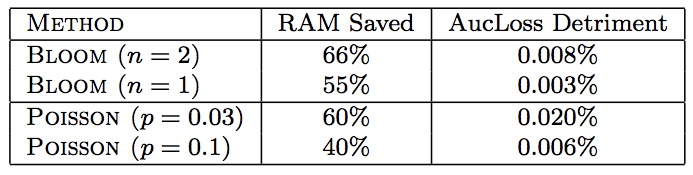
两种方法都不错,BF方式有更好的均衡性(RAM saving和loss)
—— encoding values with fewer bits
【TODO】(没有效果损失)
—— training many similar models
【TODO】
—— a single value structure
【TODO】
—— computing learning rates with counts
【TODO】
—— subsampling training data
1)保留至少点击一个ad的query
2)按概率r采样无点击ad的query
采样query是合理的,因为包含通用特征query phrase。但是要纠偏,对于每个样本计算loss(梯度同理)提权:
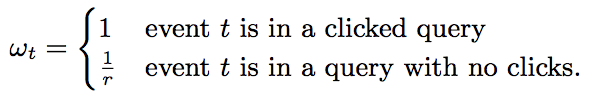
得到相同的期望loss。试验显示激进的下采样对accuracy影响甚微。
- evaluating model performance
AucLoss = 1 - AUC,LogLoss,SquaredError
—— progressive validation
计算评估度量(metrics)在country、query topic、layout等维度
只在最近的数据上度量
绝对度量是有误导性的。输出不点击可以预估为接近50%,可以预估为2%。明显2%更好,所以需要LogLoss这种度量。而且需要在country、query等细分维度做度量。
相对度量也有必要:对比基线(baseline)的相对数值。
—— deep understanding through visualization
大致是可视化细分维度的各种指标
—— confidence estimates
accuracy的预期,用作给explore/exploit算法做参考。本文提出uncertainty score。核心思想是每维保存一个uncertainty counters n_{t,i},用来做学习率调整。大的n_i得到一个小的学习率,因为参数很可能足够精确了。
LogLoss的梯度叫log-odds score = (p_t - y_t),绝对值<=1。假设特征向量长度x_{t,i}<=1,我们能做到根据一个样本(x,y)来预测log-odds。做简化lambda_1 = lambda_2 = 0,如此FTRL-Proximal等效于OGD。
令![]() ,结合:
,结合:

—— calibrating predictions
增加校准层(calibration layer)将预估ctr调整到观测ctr。
拟合校准函数![]() ,p是预估ctr。用Poisson regression在额外的数据上拟合。也可以用单调递增的分段线性函数(折线)或者分段常数函数拟合。比如用isotonic regression(加权最小二乘法拟合)。相对而言分段线性函数能对高和低的边界区域有效纠偏。
,p是预估ctr。用Poisson regression在额外的数据上拟合。也可以用单调递增的分段线性函数(折线)或者分段常数函数拟合。比如用isotonic regression(加权最小二乘法拟合)。相对而言分段线性函数能对高和低的边界区域有效纠偏。
但是没有有效的理论保证校准有效。
- automated feature management
将特征空间组织成各种信号(signals),比如ad words、country,能转换为实数特征。为了管理signals和models,做了metadata index。
- unsuccessful experiments
—— aggressive feature hashing
一些文献声称的feature hashing(用作省内存)的方式在试验中无效。因此保存可解释(即non-hashed)的特征数值向量。
—— dropout
对特征采样的尝试往往是负向的
—— feature bagging
k overlapping subsets of feature space做bagging,结论是大概0.1%-0.6%负向。
—— feature vector normalization
往往负向。















 7458
7458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









