







20天的时间参加了Kaggle的 Avito Demand Prediction Challenged ,第一次参加,成绩离奖牌一步之遥,感谢各位队友,学到的东西远比成绩要丰硕得多。作为新手,希望每记录一次可以进步一次。下面将我这段时间的心路历程进行记录,作为经历,也作为自己的经验:
可点击 -- Github
一、审题
审题过程应该是在这道题中焦灼的一环,因为直到现在我都不确定我是否完全明白了题意。
In their fourth Kaggle competition, Avito is challenging you to predict demand for an online advertisement based on its full description (title, description, images, etc.), its context (geographically where it was posted, similar ads already posted) and historical demand for similar ads in similar contexts. With this information, Avito can inform sellers on how to best optimize their listing and provide some indication of how much interest they should realistically expect to receive.
Excuse me! 可能我英语真的不好,但是你真的只说了举办这个比赛你们是为了什么,而没说我们对于比赛要干什么?!
这道题是由Avito这个公司发起,这个公司我暂时把它理解为国内‘闲鱼’类型的二手平台,给的主要数据为150多万个样本,每个样本对应一个商品信息,具体包括用户id,商品id,商品的描述,类型,价格,图片等等。要预测的target是一个概率,可以说是一个商品的成交转换率。所以,我认为,Avito发起这个竞赛的主要目的是为了给用户提供一个编辑自己商品广告使得成交转化率最高的方法。
样本对应的特征可以分为如下几类:类别,文本,图片,数值,日期。
这里几乎把所有的特征类别都包括了,所以对于特征的处理主要分为三大块:
1、特征工程
2、文本NLP
3、图片处理
介于分工,图片处理不是我干的事,而且最后其实也没有派上用场,所以在这里你发现不到关于图片的内容哦!
比赛的数据集链接在这里:https://www.kaggle.com/c/avito-demand-prediction/data
二、Kernels
成也kernel,败也kernel。这么说Kaggle这个比赛实在是太合适不过,每个竞赛的kernels栏目中提供了大量的竞赛者的开源分析和代码,你可以站在别人的肩膀上来操作你自己的想法。对于数据的初步分析,你完全可以在kernel里找到现成的分析结果,这确实为熟悉题目,熟悉数据创造了捷径,节省了时间。
然而,必须吐槽一下,在比赛的前一天有人发布了一个成绩可排在15%的blending的kernel,这使得当时的排名发生巨大混乱,对用心做比赛的人伤害颇深,kaggle官方确实得管一管这种事。
三、构建baseline
baseline是处理一切的框架,这时候可以借助kernel,
参考我的github
四、特征工程
不知道把特征工程放在这个位置对不对,因为这是一个贯穿始终的东西。内容太多了,记录的东西也太多了。
4.1 缺失值处理
数据中的缺失值有很多,由于我使用的模型是lightgbm,此模型对于缺失值可以不做处理,但是应该仅仅是针对类别特征。对于数值型的特征,采用的方法可以见这篇文章【转】数据分析中的缺失值处理
- 对于文本特征
descripition和title,我是直接采用了填充'missing'的方法 - 对于数值特征
price,我是直接填充-999,因为两点:1、这是一个很重要的特征,2、采用的决策树模型即将填充的-999直接分为一类,若采用的是线性模型,则不能这样。 - 对于其他的类别特征,我没有对缺失值进行处理,原因还是因为lightgbm
4.2 类别特征
该竞赛中类别特征很多,我是直接将这些类别进行labelencoder,由于采用的是基于决策树的lightgbm,所以没有必要进行onehot编码。
cat_cols = {"region","city","parent_category_name","category_name","user_type","image_top_1","param_2","param_3"}
lbl = LabelEncoder()
for col in cat_cols:
merge[col] = lbl.fit_transform(merge[col].astype(str))对于类别特征,尤其是高势集类别(High Categorical)特征,在discuss中,我学到了一种用word2vec对特征做聚类的方法,另行介绍。
4.3 数值型特征
唯一一个数值型特征是price,经过plot后发现price的数值呈现一个方差很大的分布,从0到百万不等。所以,这时候,采用log变换将数值映射到一个小的范围是一个比较好的选择。
merge["price"] = np.log(merge["price"]+0.001)
merge["price"].fillna(-999,inplace=True)下图是经过log后变换的price:

4.4 日期特征
简单的,将年月日进行提取,都作为一个新的特征:
merge["activation_weekday"] = merge['activation_date'].dt.weekday
merge["Weekd_of_Year"] = merge['activation_date'].dt.week
merge["Day_of_Month"] = merge['activation_date'].dt.day五、文本特征
还是单独拿出一章写吧, 因为在这里花费的时间才是最多的。这里会介绍一些NLP的基本用法,当然很浅显。
5.1 挖掘文本特征
题目中的文本特征一共有三个,且是俄文,分别是
descripition:对于商品的描述,文字较多(10-100不等),有数字和表情符号
title:商品的题目,文字较少(3-20)
param_1: 不知道什么的文字特征,文字很少
我们提取了很多关于这些文本的特征,包括每个特征的总次数,stopwords次数,数字的数目,标点符号的数目,以及各种字符所占的比例等等。对于最开始的特征挖掘,先不管三七二十一,头脑风暴能挖一个是一个,到时候再删也可以。
代码借鉴了某kernel:
for cols in textfeats:
merge[cols] = merge[cols].astype(str)
merge[cols] = merge[cols].astype(str).fillna('missing') # FILL NA
merge[cols] = merge[cols].str.lower() # Lowercase all text, so that capitalized words dont get treated differently
merge[cols + '_num_stopwords_en'] = merge[cols].apply(lambda x: len([w for w in x.split() if w in stopwords_en])) # Count number of Stopwords
merge[cols + '_num_stopwords'] = merge[cols].apply(lambda x: len([w for w in x.split() if w in stopwords])) # Count number of Stopwords
merge[cols + '_num_punctuations'] = merge[cols].apply(lambda comment: (comment.count(RE_PUNCTUATION))) # Count number of Punctuations
merge[cols + '_num_alphabets'] = merge[cols].apply(lambda comment: (comment.count(r'[a-zA-Z]'))) # Count number of Alphabets
merge[cols + '_num_alphanumeric'] = merge[cols].apply(lambda comment: (comment.count(r'[A-Za-z0-9]'))) # Count number of AlphaNumeric
merge[cols + '_num_digits'] = merge[cols].apply(lambda comment: (comment.count('[0-9]'))) # Count number of Digits
merge[cols + '_num_letters'] = merge[cols].apply(lambda comment: len(comment)) # Count number of Letters
merge[cols + '_num_words'] = merge[cols].apply(lambda comment: len(comment.split())) # Count number of Words
merge[cols + '_num_unique_words'] = merge[cols].apply(lambda comment: len(set(w for w in comment.split())))
merge[cols + '_words_vs_unique'] = merge[cols+'_num_unique_words'] / merge[cols+'_num_words'] # Count Unique Words
merge[cols + '_letters_per_word'] = merge[cols+'_num_letters'] / merge[cols+'_num_words'] # Letters per Word
merge[cols + '_punctuations_by_letters'] = merge[cols+'_num_punctuations'] / merge[cols+'_num_letters'] # Punctuations by Letters
merge[cols + '_punctuations_by_words'] = merge[cols+'_num_punctuations'] / merge[cols+'_num_words'] # Punctuations by Words
merge[cols + '_digits_by_letters'] = merge[cols+'_num_digits'] / merge[cols+'_num_letters'] # Digits by Letters
merge[cols + '_alphanumeric_by_letters'] = merge[cols+'_num_alphanumeric'] / merge[cols+'_num_letters'] # AlphaNumeric by Letters
merge[cols + '_alphabets_by_letters'] = merge[cols+'_num_alphabets'] / merge[cols+'_num_letters'] # Alphabets by Letters
merge[cols + '_stopwords_by_letters'] = merge[cols+'_num_stopwords'] / merge[cols+'_num_letters'] # Stopwords by Letters
merge[cols + '_stopwords_by_words'] = merge[cols+'_num_stopwords'] / merge[cols+'_num_words'] # Stopwords by Letters
merge[cols + '_stopwords_by_letters_en'] = merge[cols+'_num_stopwords_en'] / merge[cols+'_num_letters'] # Stopwords by Letters
merge[cols + '_stopwords_by_words_en'] = merge[cols+'_num_stopwords_en'] / merge[cols+'_num_words'] # Stopwords by Letters
merge[cols + '_mean'] = merge[cols].apply(lambda x: 0 if len(x) == 0 else float(len(x.split())) / len(x)) * 10 # Mean
merge[cols + '_num_sum'] = merge[cols].apply(sum_numbers)
merge['title_desc_len_ratio'] = merge['title_num_letters']/(merge['description_num_letters']+1)
merge['title_param1_len_ratio'] = merge['title_num_letters']/(merge['param_1_copy_num_letters']+1)
merge['param_1_copy_desc_len_ratio'] = merge['param_1_copy_num_letters']/(merge['description_num_letters']+1)5.2 TF-IDF
TF-IDF是一个对于关键字权重的度量,简单来说:
1、统计句子中每个词的数目,并将该数目标在该句子的句向量对应位置上。(句向量每个位置对应词库中的一个特定词,每句话的句向量的相同位置对应的词相同)
2、对于1中生成的句向量,进行单文本词频TF(Term Frequency)处理:因为对于长句子,词出现的数目会更多,为了对词出现的频率进行归一化,对句向量进行TF 处理(每个词的个数除以该句子总词数)。
3、对于句向量中的每个词,要给予权重。为什么呢?例如:对于‘原子能的应用’这个句子,‘应用’这个词是个通用词,在不同句子中出现的概率很高,而‘原子能’是个很专业的词,后者在相关性排名中比前者更重要。因此,一个词预测主题的能力越强,权重越大。
对于某些停止词(stopwords),如‘的’,‘是’之类的词,由于其出现频率相当之高,权重为0。
权重的设定采用的是‘逆文本频率指数’(IDF)的方法,公式为\(log(\frac{D}{D_w})\),其中D为全部句子数量,D_w为某词在D_w个句子中出现过的数量。所以,如果一个词只在很少的句子中出现,通过它就容易将该句子分类,它的权重就越大。
tv = TfidfVectorizer(max_features=100000,
ngram_range=(1, 3),
stop_words=set(stopwords.words('russian')))
X_name_train = tv.fit_transform(all_train['title'])由于该题文本数据量太大,在fit了三个文本特征后,默认是输出稀疏矩阵,如果这个时候进行toarray()的操作,我的渣渣机器就会出现爆内存的错误,所以建议这里直接对稀疏矩阵进行处理。我用了三种处理方法:
0、先将这三个文本的稀疏矩阵hstack:
sparse_merge_train = hstack((X_description_train, X_param1_train, X_name_train)).tocsr()PS:稀疏矩阵在scipy中可表示成几种储存形式,常用的有csr,csc。前者为行格式Row format,后者为列格式Columns format, 这两者互为转置。csc列切片操作快,csr行切片操作快,所以为了之后分离train和test数据集,后续需要进行行切片,所以进行tocsr()操作。
1、SVD
在茫茫的大稀疏矩阵中提取奇异值最高的几个维度。为什么不用PCA呢?PCA也能达到降维的目的,但是需要对数值进行零均值化,以至于丢失零矩阵的稀疏性,我是这样理解的啊哈哈。
svd_obj = TruncatedSVD(n_components=n_comp, algorithm='arpack')
svd_obj.fit(X_name_train)2、Ridge
其实很简单,就是将sparse_merge_train通过一个ridge模型进行训练,之后得出一个预测出来的特征。ridge简单来说就是一个一层线性回归加l2正则化。
def ridge_proc(train_data, test_data, y_train):
X_train_1, X_train_2, y_train_1, y_train_2 = train_test_split(train_data, y_train,
test_size = 0.5,
shuffle = False)
print('[{}] Finished splitting'.format(time.time() - start_time))
model = Ridge(solver="sag", fit_intercept=True, random_state=205, alpha=3.3)
model.fit(X_train_1, y_train_1)
ridge_preds1 = model.predict(X_train_2)
ridge_preds1f = model.predict(test_data)
model = Ridge(solver="sag", fit_intercept=True, random_state=205, alpha=3.3)
model.fit(X_train_2, y_train_2)
ridge_preds2 = model.predict(X_train_1)
ridge_preds_oof = np.concatenate((ridge_preds2, ridge_preds1), axis=0)
ridge_preds_test = (ridge_preds1f + ridge_preds2f) / 2.0
print('RMSLE OOF: {}'.format(rmse(ridge_preds_oof, y_train)))
return ridge_preds_oof, ridge_preds_test同理,这里用DNN,CNN也可以进行类似操作,这里不再深入。
3、直接做特征
将sparse_merge_train这个硕大的稀疏矩阵直接做特征不失为一个臃肿的方法,但是效果却是最好的。由于稀疏矩阵的合并需要使用hstack,所以其他特征也需要进行稀疏化。csr_matrix(),这个scipy中的函数了解一下。
5.3 Word2Vec
这里提一下Xin Rong的这篇论文,《word2vec Parameter Learning Explained》
简单来说:
w2v的模型是一个只有一个隐藏层的神经网络,input为上下文词(CBOW)或目标词(Skip-gram)的one-hot编码,output对应分别为目标词或上下文词的出现概率。
model = Word2Vec(texts, size=FEAT_VEC_SIZE, window=5, min_count=5, workers=4)在本题中,使用word2vec的目的不在于预测上下文,而在于提取文本特征。所以,word2vec的作用在于提供词向量,所以对于w2v模型,我们的关注点不在于最后的predict,而是输入层与隐藏层之间的参数权重矩阵W,这个矩阵一共有v行(v 为ont-hot编码中所有词的个数),每一行最后的训练结果即为对应词的词向量。隐藏层与输出层之间的权重矩阵W'的每列也可看作是另一种形式的词向量,output的每个位置的结果即为该位置词出现的概率。
为什么每一行可以看作对应词的词向量?假设input词为一个one-hot列,只有一个位置为1,其余为0,则隐藏层的结果即为该位置对应的权重矩阵W的行的copy的转置。隐藏层到输出的结果可以看成是这个copy与该词上下文词出现概率的对应关系。所以这个copy可以与一个特定的词一一对应。
那么句向量呢?我们已经通过word2vec模型得到了句子中每个词的词向量,我们只需要把这个句子每个词的词向量进行线性相加等操作就可得到该句子的句向量
在这之前还需要进行一系列的预处理:
# num_words: the maximum number of words to keep, based on word frequency. Only the most common num_words words will be kept.
tokenizer = Tokenizer(num_words=MAX_NUM_WORDS)
tokenizer.fit_on_texts(texts)
#将一个句子拆分成单词id构成的列表
sequences = tokenizer.texts_to_sequences(texts)
#单词字典
word_index = tokenizer.word_index
print('Found %s unique tokens' % len(word_index))
# 填充句子到相同长度, 作为最后模型训练数据
traindes = pad_sequences(sequences, maxlen=MAX_TEXT_LENGTH)
embedding_matrix = np.zeros((MAX_NUM_WORDS, FEAT_VEC_SIZE))
for word, i in word_index.items():
if word in model.wv and i < MAX_NUM_WORDS:
embedding_matrix[i] = model.wv.word_vec(word)上述这个嵌入矩阵为词向量矩阵,包含着所有保留词的词向量。
生成句向量后,处理方法跟5.2节几乎无异。
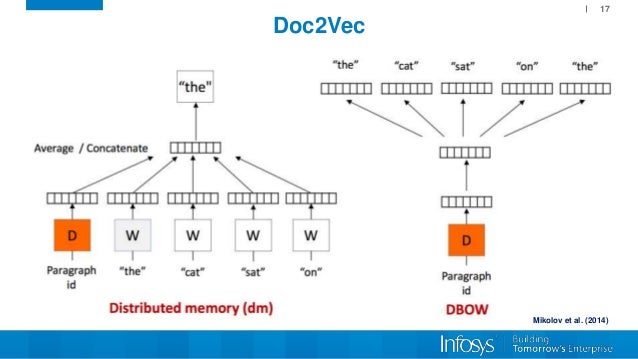
5.4 Doc2Vec
原理基于word2vec,只是在输入层中加了句子id,模型得到的结果直接为句向量。
TaggededDocument = gensim.models.doc2vec.TaggedDocument
x_train = []
for i, text in enumerate(texts):
document = TaggededDocument(text, tags=[i])
x_train.append(document)
d2v_model = Doc2Vec(x_train, min_count=1, window = 3, size= 100, sample=1e-3, negative=5, workers=4)
infered_vectors_list = []
for text, label in x_train:
vector = d2v_model.infer_vector(text)
infered_vectors_list.append(vector)处理方法:
我对doc2vec产生的句向量分别做了kmeans和DBSCAN聚类,不过效果并不是很理想。
六、模型预测
6.1 直接LightGBM-regression
这应该算是baseline中的模型了,但是其实这种最直接最简单的模型在最后的效果居然最好,调参过程还是比较重要的。献一张我们的feature-importance

6.2 LightGBM-classification-regression

由于target的呈现出了上图的分布,可以看到,target为0的样本远超其他样本的总和。所以,这里可以采用过采样或者欠采样的方法进行处理,但是我们没有?。
我们采用了先用分类器预测1/0值,再对于非0值进行回归预测的方法来想着提高最后的分数。
y_train1 = y_train.apply(lambda x: 1 if x>0 else 0)
y_test1 = y_test.apply(lambda x: 1 if x>0 else 0)
d_train = lgb.Dataset(df_train, label=y_train1, categorical_feature=list(cat_cols),free_raw_data=False)
d_valid = lgb.Dataset(df_test, label=y_test1, categorical_feature=list(cat_cols), reference=d_train,free_raw_data=False)
watchlist = [d_valid]
params = {
'learning_rate': 0.01,
'application': 'binary',
'is_unbalance':True,
'metric': ['auc','binary_error','fbeta']
}
modelC = lgb.train(params,
train_set=d_train,
num_boost_round=1000,
valid_sets=watchlist,
early_stopping_rounds=50,
verbose_eval=500)对于该分类器的metric,这里提取了验证集的precision,recall和f1用来选择合适的阈值。在本题来说,target为0值为负类,非0值的为正类。在这个分类器中,我们预测出0值,且要保证正类尽可能不被预测成负类,因为正类的值在回归器中预测的结果会更准确,所以对于此分类器的metric,我们要求查全率recall尽可能高。
def fbeta(y_true, pred):
# 调整阈值
best_recall=0
precision_recall = []
best_thershold=0
for thershold in [0.15,0.2, 0.25,0.3,0.4,0.45,0.5]:
preds = [1 if i > thershold else 0 for i in pred]
precision, recall, f_score, true_sum=precision_recall_fscore_support(y_true, preds)
if recall[1] > best_recall:
best_thershold = thershold
precision_recall = []
best_recall=recall[1]
return 'best_recall', best_recall, True对于分类器后的回归器,我们输入的数据集为经过分类器预测为1的所有数据,而并不是原始的通过判断0或非0得到的target的1/0数据。
下面这个流程图展示了两种输入到回归器中的方法。

6.3 CNN RNN FastFM
要说的太多,吐一口老血?
七、Blending
这是在最后一刻有人爆出来的kernel,这里直接借鉴过来吧。以下是进行筛选blending的模型结果的过程:
1、将之前所有模型预测过的结果merge起来,且将分数top3的模型结果标记
2、对1中merge的结果进行相关性分析
sns.heatmap(df_base.iloc[:,1:].corr(),annot=True,fmt=".2f")3、找到与1中标记的top3相关性最大的模型结果,然后drop
4、对剩下的模型结果进行averaging
提升效果很明显,但是应该也有瓶颈。
Reference:
- 数学之美,吴军
- http://scikit-learn.org/stable/modules/feature_extraction.html#text-feature-extraction
- https://zhuanlan.zhihu.com/p/26645088
- https://www.kaggle.com/sudalairajkumar/simple-exploration-baseline-notebook-avito
- https://blog.csdn.net/wangjian1204/article/details/50642732
- https://www.kaggle.com/dandres/best-public-blend-0-2204















 1199
1199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









