






PyTorch Hook¶
- 为什么要引入hook? -> hook可以做什么?
- 都有哪些hook?
- 如何使用hook?
1. 为什么引入hook?¶
参考:Pytorch中autograd以及hook函数详解
在pytorch中的自动求梯度机制(Autograd mechanics)中,如果将tensor的requires_grad设为True, 那么涉及到它的一系列运算将在反向传播中自动求梯度。
x = torch.randn(5, 5) # requires_grad=False by default
y = torch.randn(5, 5) # requires_grad=False by default
z = torch.randn((5, 5), requires_grad=True)
a = x + y
b = a + z
print(a.requires_grad, b.requires_grad)
但是自动求导的机制有个我们需要注意的地方:在自动求导机制中只保存叶子节点,也就是中间变量在计算完成梯度后会自动释放以节省空间. 所以下面代码我们在计算过程中只得到了z对x的梯度,而y和z的梯度都在梯度计算后被自动释放了,所以显示为None.
x = torch.tensor([1,2],dtype=torch.float32,requires_grad=True)
y = x * 2
z = torch.mean(y)
z.backward()
print("x.grad =", x.grad)
print("y.grad =", y.grad)
print("z.grad =", z.grad)
那么能否得到y,z的梯度呢?这就需要引入hook.
在pytorch的tutorial中介绍:
We’ve inspected the weights and the gradients. But how about inspecting / modifying the output and grad_output of a layer ? We introduce hooks for this purpose. hook的引入是为了让我们可以检测或者修改一个layer的output或者grad_output.
2. hook的种类¶
- TENSOR.register_hook(FUNCTION)
- MODULE.register_forward_hook(FUNCTION)
- MODULE.register_backward_hook(FUNCTION)
可以为Module或者Tensor注册hook。
如果为Tensor注册hook, 用register_hook();
如果为Module注册hook, 若希望获取前向传播中layer的input, output信息,可以用register_forward_hook(); 如果为Module注册hook, 若希望获取反向传播中layer的grad_in, grad_out信息,可以用register_backward_hook().
3. TENSOR.register_hook(FUNCTION)¶
x = torch.tensor([1,2],dtype=torch.float32,requires_grad=True)
y = x * 2
y.register_hook(print)
z = torch.mean(y)
z.backward()
以上代码中,对y进行register_hook引入print这个函数,print即是简单的打印,将y相关的grad打印出来。
在执行z.backward()执行的时候,由于y的hook函数也执行了,打印出了y关于输出z的梯度, 即 tensor([0.5000, 0.5000]) 便是y的梯度。
4. MODULE.register_forward_hook(FUNCTION) && MODULE.register_backward_hook(FUNCTION)¶
参考链接:Toy example to understand Pytorch hooks
介绍这两个的用法前,我们先定义module, 之后的hook便是为以下的module注册的。
import numpy as np
import torch
import torch.nn as nn
from IPython.display import Image
1. Define the network¶
''' Define the Net '''
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(2,2)
self.s1 = nn.Sigmoid()
self.fc2 = nn.Linear(2,2)
self.s2 = nn.Sigmoid()
self.fc1.weight = torch.nn.Parameter(torch.Tensor([[0.15,0.2],[0.250,0.30]]))
self.fc1.bias = torch.nn.Parameter(torch.Tensor([0.35]))
self.fc2.weight = torch.nn.Parameter(torch.Tensor([[0.4,0.45],[0.5,0.55]]))
self.fc2.bias = torch.nn.Parameter(torch.Tensor([0.6]))
def forward(self, x):
x= self.fc1(x)
x = self.s1(x)
x= self.fc2(x)
x = self.s2(x)
return x
net = Net()
print(net)
''' Get the value of parameters defined in the Net '''
# parameters: weight and bias
print(list(net.parameters()))
''' feed the input data to get the output and loss '''
# input data
data = torch.Tensor([0.05,0.1])
# output of last layer
out = net(data)
target = torch.Tensor([0.01,0.99]) # a dummy target, for example
criterion = nn.MSELoss()
loss = criterion(out, target)
print(loss)
2. The structure of hook input, output && grad_in, grad_out¶
在MODULE.register_forward_hook(FUNCTION)中,涉及到input, output参数,
在MODULE.register_backward_hook(FUNCTION)中,涉及到grad_in, grad_out参数, 下面的图示显示了input, output分别是一个layer的输入和输出;
grad_in是整个神经网络的输出(可以想成最终的损失L)对layer的output求偏导, grad_out是 ( L对output求偏导 × output对input的偏导) => 链式法则。
from google.colab import files
from IPython.display import Image
uploaded = files.upload()
Image("hook_in_out.png")
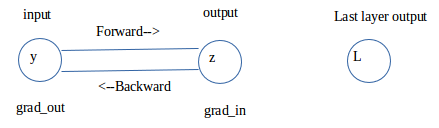
input ----------------------------> output------------------> Last layer output
y--------------------------------------------z -----> ... ------------> L
grad_out <------------------------ grad_in
(dL/dz) * (dz / dy) ---------------(dL/dz)
下面代码中,如果backward = False, 表示的是前向传播,input, output分别对应layer的输入和输出;
如果backward = True, 表示的是反向传播过程,input 表示的是上图中的 grad_in, output 表示的是上图中的 grad_out.
''' Define hook
'''
# A simple hook class that returns the input and output of a layer during forward/backward pass
class Hook():
def __init__(self, module, backward=False):
if backward==False:
self.hook = module.register_forward_hook(self.hook_fn)
else:
self.hook = module.register_backward_hook(self.hook_fn)
def hook_fn(self, module, input, output):
self.input = input
self.output = output
def close(self):
self.hook.remove()
# get the _modules.items()
# format: (name, module)
print(list(net._modules.items()))
# use layer[0] to get the name and layer[1] to get the module
for layer in net._modules.items():
print(layer[0], layer[1])
为Hook类创建对象时,需要传入module参数,以下代码通过layer[1] 获取。将前向的hook都放在hookF数组中,将反向的hook都放在hookB的数组中。
注意一定要先注册hook, 之后再将data传入神经网路进行前向传播,即注册hook一定要在net(data)之前进行,因为hook函数是在forward的时候进行绑定的。
''' Register hooks on each layer
'''
hookF = [Hook(layer[1]) for layer in list(net._modules.items())]
hookB = [Hook(layer[1],backward=True) for layer in list(net._modules.items())]
# run a data batch
out=net(data)
print(out)
3. Get the hook input, output and grad_in, grad_out value¶
注意loss.backward(retain_graph = True) 对于backward_hook并不适用
以下报错显示了 'Hook' object has no attribute 'input', 对于loss, 它并不是一个有input,output的网络层,而只是网络最后一层的输出与target的aggregated的结果。
而之前定义的Hook中,要求有明确的input和output,所以,并不适用于loss.backward()
应该采用out.backward(label_tensor, retain_graph = True)
3.1 loss.backward(retain_graph = True)¶
loss.backward(retain_graph = True)
print('***'*3+' Forward Hooks Inputs & Outputs '+'***'*3)
for hook in hookF:
print(hook.input)
print(hook.output)
print('---'*17)
print('\n')
#! loss.backward(retain_graph=True) # doesn't work with backward hooks,
#! since it's not a network layer but an aggregated result from the outputs of last layer vs target
print('***'*3+' Backward Hooks Inputs & Outputs '+'***'*3)
for hook in hookB:
print(hook.input)
print(hook.output)
print('---'*17)
3.2 out.backward(TENSOR, retain_graph = True)¶
下面采用的是正确的out.backward(torch.tensor([1,1],dtype=torch.float),retain_graph=True)的形式。
由于调用backward()的是out, 一个tensor而不是scalar, pytorch中不能直接求解它的Jacobian矩阵,需要为其指定grad_tensors.grad_tensors 可以看做对应张量的每个元素的梯度。
比如对于 y.backward(v,retain_graph = True), 其中 y = (y1, y2, y3), v = (v1, v2, v3), 那么backward中执行的操作是,先分别 (y1 v1, y2 v2, y3 * v3),之后再对y求偏导,y再对parameter求偏导, 链式法则。
其实也可以看做,在一般对网络的输出y, 与标签l,利用损失函数得到一个损失标量L,表示为:
L = v1 y1 + v2 y2 + v3 y3;
dL/dy = (v1, v2, v3);
dL/dw = dL/dy dy/dw =( v1 dy/dw, v2 dy/dw, v3 * dy/dw)
上式dL/dw中的v即为 y.backward(v,retain_graph = True)的v的体现。相当于对于y.backward()的梯度都对应乘了v的系数。
out.backward(torch.tensor([1, 1], dtype = torch.float), retain_graph = True)
print('***'*3+' Forward Hooks Inputs & Outputs '+'***'*3)
for hook in hookF:
print(hook.input)
print(hook.output)
print('---'*17)
print('\n')
print('***'*3+' Backward Hooks Inputs & Outputs '+'***'*3)
for hook in hookB:
print(hook.input)
print(hook.output)
print('---'*17)
4. Module Hooks Problem¶
Problem with backward hook function #598
在该Issue中,指出了pytorchde module的一个问题:
“Ok, so the problem is that module hooks are actually registered on the last function that the module has created. In your case x + y + z is computed as ((x + y) + z) so the hook is registered on that (_ + z) operation, and this is why you're getting only two grad inputs.
We'll definitely have to resolve this but it will need a large change in the autograd internals. However, right now @colesbury is rewriting them to make it possible to have multiple functions dispatched in parallel, and they would heavily conflict with his work. For now use only Variable hooks (or module hooks, but not on containers). Sorry!”
翻译过来是,module hooks只为一个module的最后的function注册,比如对于 (x + y + z),本应分别得到关于(x, y, z)这三个的grad, 但是pytorch会先计算(x + y), 之后计算( _ + z), 所以最终只有两个grad,一个是关于(x + y)整体的grad, 一个是关于z的grad. 这是pytorch开发中一个比较难以解决的问题,目前该问题还没有被解决。
鉴于这个问题,为了避免不必要的bug出现,设计者建议使用tensor的register_hook, 而不是module的hook。如果出现类似问题,可以知道从这里找原因。















 3187
3187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









