







欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。
技术交流QQ群:433250724,欢迎对算法、技术、应用感兴趣的同学加入。
文章索引::”机器学习方法“,”深度学习方法”,“三十分钟理解”原创系列
2017年3 月,谷歌大脑负责人 Jeff Dean 在 UCSB 做了一场题为《通过大规模深度学习构建智能系统》的演讲[9]。Jeff Dean 在演讲中提到,当前的做法是:
解决方案 = 机器学习(算法)+ 数据 + 计算力
未来有没有可能变为:
解决方案 = 数据 + 100 倍的计算力?
由此可见,谷歌似乎认为,机器学习算法能被超强的计算力取代[9]。

[11]研究工作表明,任务表现与训练数据数量级呈线性增长关系。或许最令人震惊的发现是视觉任务的表现和用于表征学习的训练数据量级(对数尺度)之间的关系竟然是线性的!即使拥有 300M 的大规模训练图像,我们也并未观察到训练数据对所研究任务产生任何平顶效应(plateauing effect)。
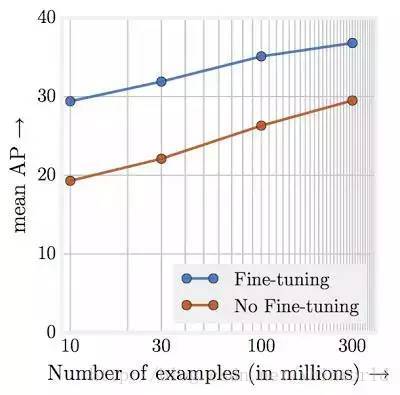
上图说明预训练模型在 JFT-300M 不同子数据集中的目标检测性能。其中 x 轴代表数据集的大小,y 轴代表在 mAP@[.5,.95] 中 COCO-minival 子数据集上的检测性能。
要完成超大规模数据的训练,以及训练超大规模的神经网络,靠单GPU是行不通的(至少目前来看),必须要有分布式机器学习系统的支撑,本文以及接下来几篇博客,会记录一下前面几年比较经典的分布式机器学习系统的学习笔记,文中资料都参考了public的paper或者网上资料,我会自己整理一下,并标明出处。作为第一篇,先总体地介绍一个全貌的基本概念。
并行模型
- 模型并行( model parallelism ):分布式系统中的不同机器(GPU/CPU等)负责网络模型的不同部分 —— 例如,神经网络模型的不同网络层被分配到不同的机器,或者同一层内部的不同参数被分配到不同机器;[14]
- 数据并行( data parallelism ):不同的机器有同一个模型的多个副本,每个机器分配到不同的数据,然后将所有机器的计算结果按照某种方式合并。
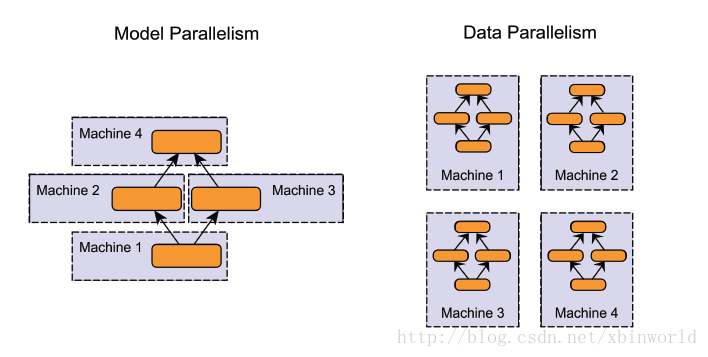
- 当然,还有一类是混合并行(Hybrid parallelism),在一个集群中,既有模型并行&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 490
490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









