







 本文介绍了分布式机器学习、联邦学习和多智能体系统的基本概念,讨论了它们在数据并行、模型并行、隐私保护和容错性等方面的特点,并指出联邦学习作为特殊分布式学习的挑战和潜在研究领域。
本文介绍了分布式机器学习、联邦学习和多智能体系统的基本概念,讨论了它们在数据并行、模型并行、隐私保护和容错性等方面的特点,并指出联邦学习作为特殊分布式学习的挑战和潜在研究领域。
1 分布式机器学习、联邦学习、多智能体介绍
最近这三个方面的论文都读过,这里写一篇博客归纳一下,以方便搞这几个领域的其他童鞋入门。我们先来介绍以下这三种机器学习范式的基本概念。
1.1 分布式机器学习介绍
分布式机器学习(distributed machine learning),是指利用多个计算/任务节点(Worker)协同训练一个全局的机器学习/深度学习模型(由主节点(Master)调度)。需要注意的是,分布式机器学习和传统的HPC领域不太一样。传统的HPC领域主要是计算密集型,以提高加速比为主要目标。而分布式机器学习还兼具数据密集型特性,会面临训练数据大(单机存不下)、模型规模大的问题。此外,在分布式机器学习也需要更多地关注通信问题。对于计算量大、训练数据量大、模型规模大这三个问题,分布式机器学习可以采用以下手段进行解决:
1)对于计算量大的问题,分布式多机并行运算可以基本解决。不过需要与传统HPC中的共享内存式的多线程并行运算(如OpenMP),以及CPU-GPU计算架构做区分。这两种单机的计算模式我们一般称为计算并行)。
2)对于训练数据大的问题,需要将数据进行划分,并分配到多个工作节点上进行训练,这种技巧一般被称为数据并行。每个工作节点会根据局部数据训练出一个子模型,并且会按照一定的规律和其他工作节点进行通信(通信的内容主要是子模型参数或者参数更新),以保证最终可以有效整合来自各个工作节点的训练结果并得到全局的机器学习模型。
如果是训练数据的样本量比较大,则需要对数据按照样本进行划分,我们称之为“数据样本划分”,按实现方法可分为“随机采样法”和“置乱切分法”。
如果训练数据的维度比较高,还可以对数据按照维度进行划分,我们称之为“数据维度划分”。相比于数据样本划分,数据维度划分与模型性质和优化方法的耦合度较高。
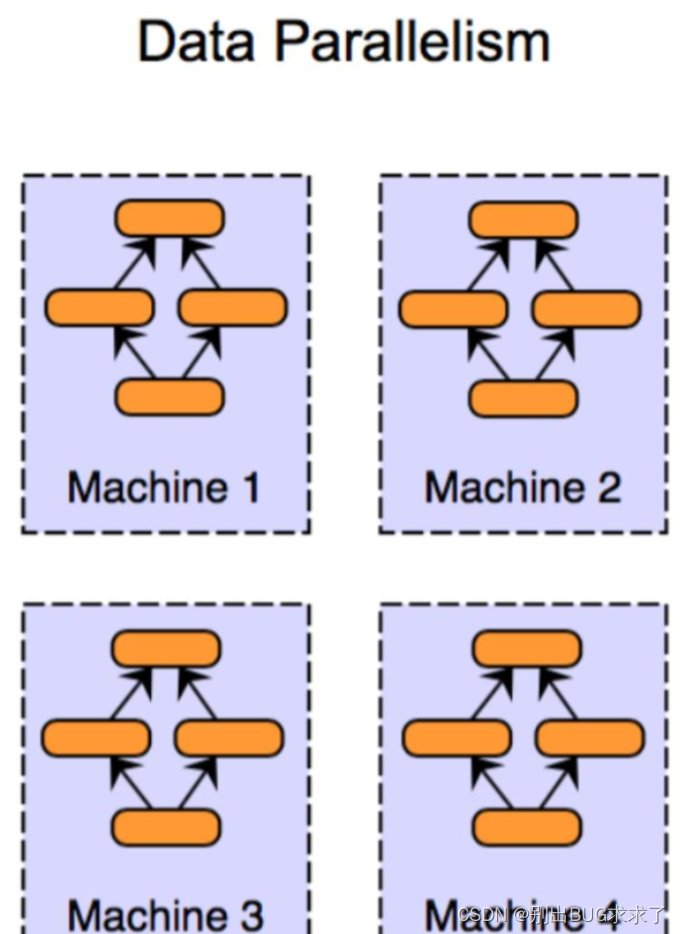
。每个工作节点会根据局部数据训练出一个子模型,并且会按照一定的规律和其他工作节点进行通信(通信的内容主要是子模型参数或者参数更新),以保证最终可以有效整合来自各个工作节点的训练结果并得到全局的机器学习模型。
3)对于模型规模大的问题,则需要对模型进行划分,并且分配到不同的工作节点上进行训练,这种技巧一般被称为模型并行。与数据并行不同,模型并行的框架下各个子模型之间的依赖关系非常强,因为某个子模型的输出可能是另外一个子模型的输入,如果不进行中间计算结果的通信,则无法完成整个模型训练。因此,一般而言,模型并行相比数据并行对通信的要求更高。
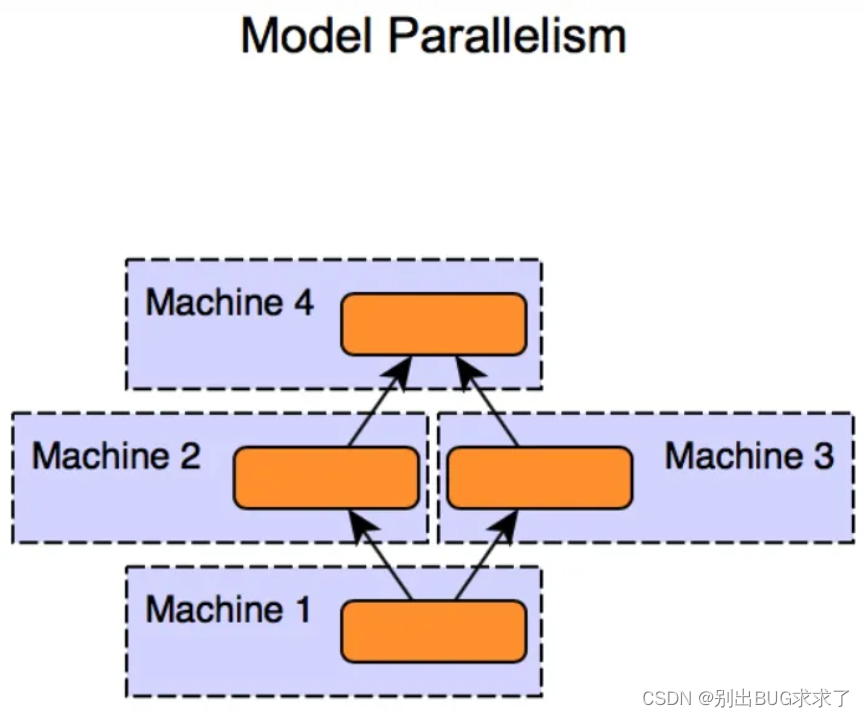
1.2 联邦学习介绍
联邦学习是一种特殊的采用数据并行的分布式机器学习(可分为横向联邦学习(对应分布式机器学习中的数据样本划分)和纵向联邦学习(对应分布式机器学习中的数据维度划分)),除了关注传统分布式机器学习的算法、通信、收敛率等问题之外,还要关注用户的数据隐私和容错性问题(因为用户终端是用户手机或物联网设备,很可能随时挂掉)。 其设计目标是在保障大个人数据隐私、保证合法合规的前提下,在多参与方(可能是现实中的多个机构)或多计算结点之间协同学习到一个更好的全局模型。联邦学习的数据不共享,(加密后的)参数可共享,它可以基于server-client主从的中心化(centralized)结构,也可以是去中心化(decentralized)结构。
形式化地,传统联邦学习的优化目标函数可以写为[1]:
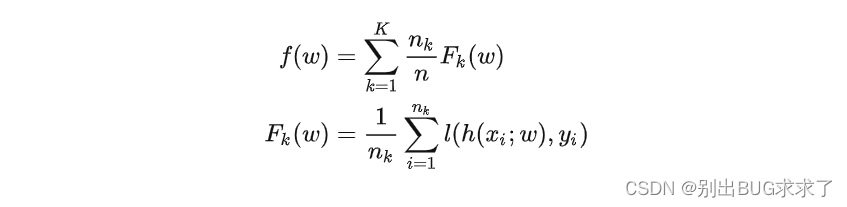


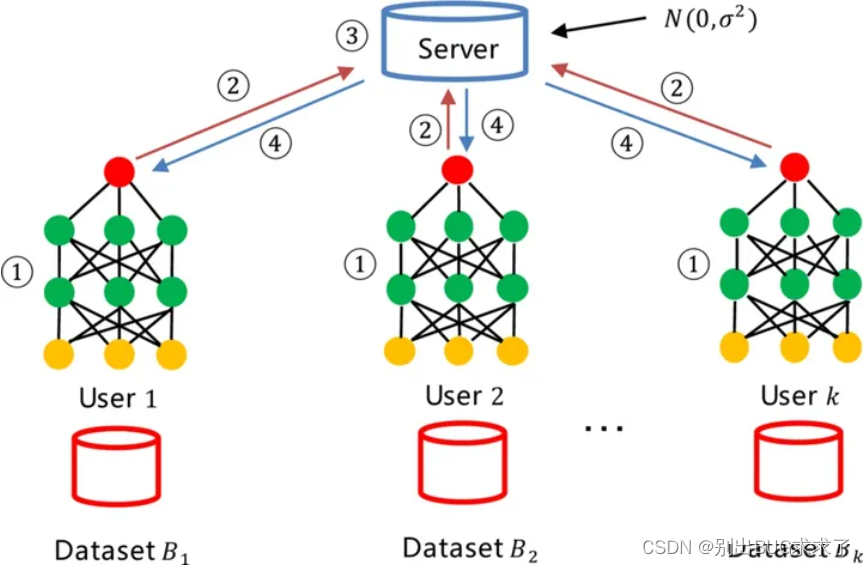
经典的server-client式的联邦学习框架的训练过程可以简单概括为以下步骤:
1)server端建立初始模型,并将模型的参数发往各client端;
2)各client端利用本地数据进行模型训练,并将结果返回给server端;
3)server端汇总各参与方的模型,构建更精准的全局模型,以整体提升模型性能和效果。
当然,以上仅仅指中心化的server-client联邦学习
相比传统的分布式机器学习,它需要关注系统异质性(system heterogeneity)、统计异质性(statistical heterogeneity)和数据隐私性(data privacy )。系统异质性体现为昂贵的通信代价和节点随时可能宕掉的风险(容错);统计异质性数据的不独立同分布(Non-IID)和不平衡。由于以上限制,传统分布式机器学习的优化算法便不再适用,需要设计专用的联邦学习优化算法。
联邦学习框架包含多方面的技术,比如传统分布式机器学习中的模型训练与参数整合技术、Server与Client高效传输的通信技术、隐私加密技术、分布式容错技术等。
最后,大家如果想寻找FedAvg算法的实现,可以参考我的GitHub仓库
https://github.com/orion-orion/FedAO
该项目集成了FedAvg算法的Pytorch/Tensorflow、多进程/分布式、同步/异步实现,可供有这个需要的童鞋使用。
1.3 群体智能基本概念
多智能体系统(multi-agent system) 是一组自主的,相互作用的实体,它们共享一个共同的环境(environment),利用传感器感知,并利用执行器作动。多智能体系统提供了用分布式来看待问题的方式,可以将控制权限分布在各个智能体上。
尽管多智能体系统可以被赋予预先设计的行为,但是他们通常需要在线学习,使得多智能体系统的性能逐步提高。而这就天然地与强化学习联系起来,智能体通过与环境进行交互来学习。在每个时间步,智能体感知环境的状态并采取行动,使得自身转变为新的状态,在这个过程中,智能体获得奖励,智能体必须在交互过程中最大化期望奖励。
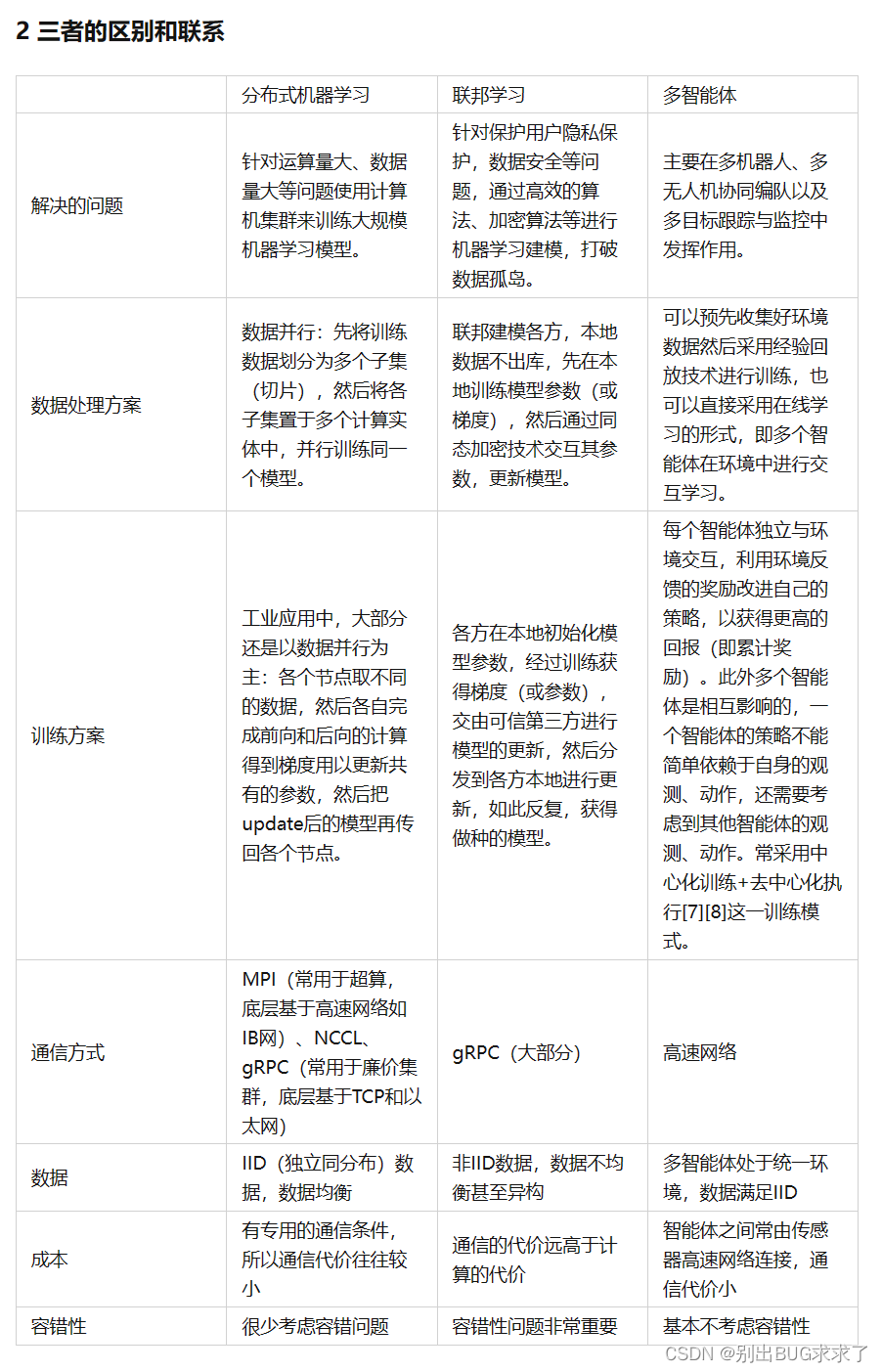
2 三者的区别和联系
3 个人研究体会
传统的分布式机器学习已经被研究十几年了,Low-hanging fruits几乎被人摘完了,目前各大顶会上的分布式机器学习主要是数学味道很浓的分布式数值优化算法。而其他方面,像我关注的分布式多任务学习,近年来相关的顶会论文开始减少。
联邦学习可以看做一种特殊的分布式学习,它有一些特殊的设定,比普通的分布式学习要困难一些,还是有很多方向可以研(灌)究(水)的,做好了应该可以发顶会。
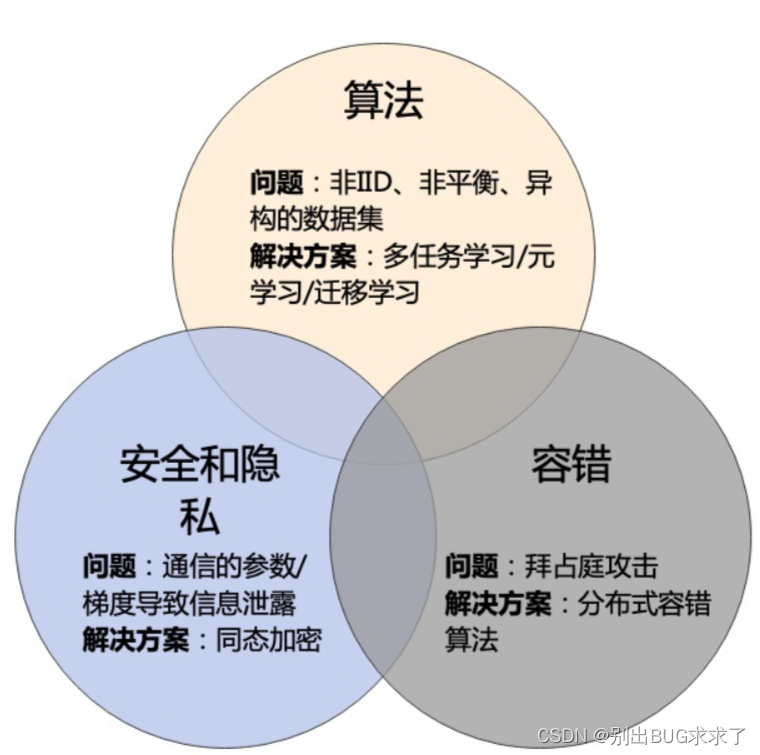
- 算法层面 可以在优化算法的通信层面降低算法通信次数,用少量的通信达到收敛;也可以从优化算法中的权重/梯度聚合(aggregation)入手,提高最终模型精度。基于IID数据集的分布式数值优化算法已经被研究得比较透彻了, 但因为联邦学习面临数据是IID/非平衡甚至是异构的,需要引入很多其他技巧才能解决,比如异构数据联合学习、多任务学习[5][6](也是我研究的方向)等。这个方向很适合数值优化、机器学习、多任务学习背景的童鞋切入。
- 安全/隐私问题 虽然联邦学习的基础设定就是节点之间不共享数据以保护用户隐私,但熟悉网络安全的同学应该知道,我们很容易从梯度、模型参数中反推出用户数据。而针对这方面提出攻击和防御的方法都可以发表出论文,这方面适合网络安全背景的童鞋切入。
- 容错性/鲁棒性。联邦学习中常常遇到拜占庭攻击问题(即恶意参与者问题)。比如在中心化的算法中,有节点恶意发送错误的梯度给服务器,让训练的模型变差;在去中心化算法中,可能有多个任务节点化为拜占庭攻击者互相攻击[4]。对于这种问题设计新的攻击方法和防御方法都可以发表论文。这个方向很适合有分布式系统背景的童鞋切入。


















 1032
1032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











