






三种常用的迭代搜索优化方法
梯度下降 牛顿法 坐标上升
因为梯度下降和牛顿法都是非常常用的,在前面的文章中也做过总结,这里不做详细说明。
梯度下降与牛顿方法是两种非常常用的迭代优化方法,主要的思想就是通过迭代,一步一步地逼近最优解。
梯度下降比较直观,沿着梯度的反方向进行搜索,属于典型的贪婪算法,迭代搜索的每一步都是当前最优的下降方向,但在全局看来可能并不是最优的下降曲线;所以梯度下降法的初始值如果比较好的话,比如想象一下目标函数曲线像是一个连绵起伏的山峰,如果初始值能够初始在具有最低谷的坡面上,通过梯度下降一定能够得到全局的最优值;而如果初始值不好,站在了一个较高山谷的坡面上,通过常规的梯度下降法,只能搜索到该局部最优的山谷低,而不能从该山谷爬出来,重新搜索更低谷。要改善梯度下降这一局部最优困境的方法,可以采用模拟退火,让搜索具有一定概率爬坡能力,即在搜索到了较高山谷时,使之有一定的概率爬出山谷,继续搜索。具体的可以参看随机神经网络一章节的文章,《随机神经网络之模拟退火》
牛顿法则是通过分析极大和极小值处曲线的特性,通过求导,并使导数为0,构造典型的f(X)=0的优化形式,每一步都从该点处的切线位置与X轴(或平面)相交的处的X作为下一次迭代的搜索位置的X坐标(对应的y可以通过f(X)求得)。通常情况下牛顿法收敛速度比梯度下降方法要快。
第三个要将的是以前没有了解的坐标上升的方法,这个优化搜索方法是在支持向量机部分引入的,为了解决soft margin SVM的优化问题。
问题描述:
坐标上升(coordinate ascent)算法描述:
Loopuntilconvergence:{
For i=1,...,m, {
αi:=arg maxαiW(α1,...,αi−1,αi,αi+1,...,αm).
}
}
算法分析说明:
调节 αi,固定其余所有的 αj,然后解决单变量的优化问题,得到一个最优值对应的 α∗i,然后换一个变量 α,同样固定其余的,再次解单变量的优化问题,重复操作直到满足迭代终止条件为之。
算法的优点:
坐标上升算法的最内层的循环是非常简单的,所以迭代的效率可能比较高,也就是说经过拆分后的优化问题转变为了单变量优化,这种优化问题十分简单,所以算法从整体上比较容易实施。
算法的缺点:
优点简单,缺点也很明显,因为简单所以搜索的速度、效率可能比梯度下降和牛顿法要差。
算法的注意事项:
类似于梯度下降,为了避免局部最优,一种可能的方法就是引入随机因素。采用随机选择变量优化顺序,比如可以采用洗牌,将顺序打乱,然后再进行逐个变量的优化,一轮过后再次洗牌,在进行优化,这样的方式可能更加易于收敛。
算法的直观演示,如下图:
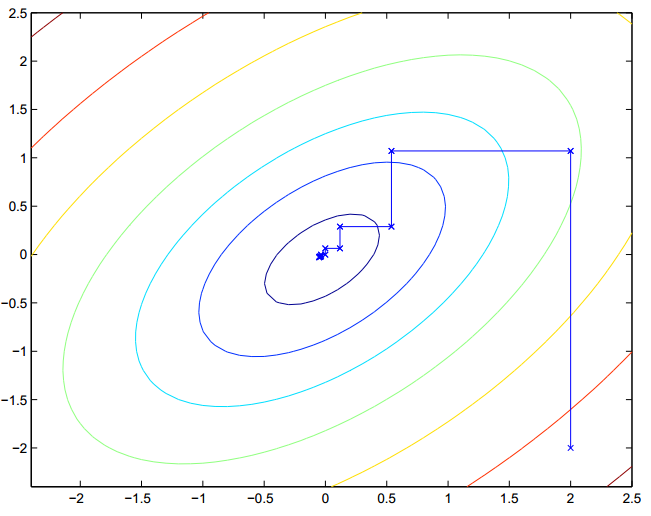
图中不同的颜色标识不同的变量,梯度上升的方法就是一步步的逼近,一次只对一个变量进行最优化。
该方法还可以应用在一些特定约束条件下的优化,比如同样的问题:
算法可以改为: α1×y(1)+α2×y(2)=ρ,
这样的话可以固定 α3,α4,...,αm,调整 α1,α2,这样等于说将 α1,α2通过 ρ联系在了一起,具体的算法调整示意图如下图所示:
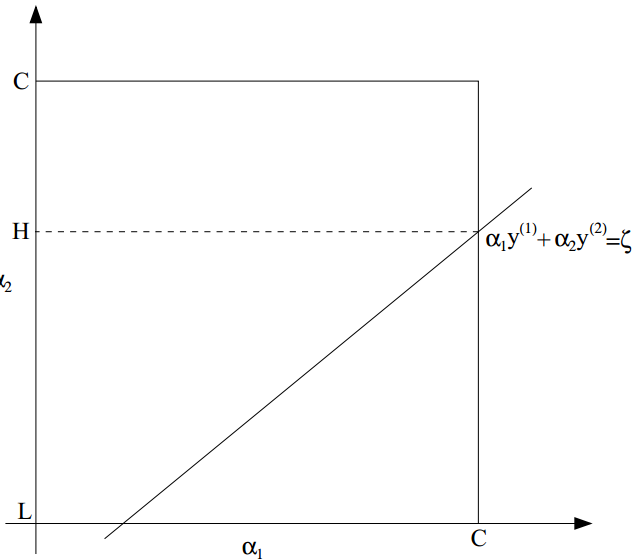
图中所示的方框是可行域,而那条斜线表示正是 α1,α2的关系,也就是约束,这样的话, α1,α2只能在这条斜线在可行域内部的一段上取值了。
说明:主要是在soft margin的SVM中,对于最后的W(α1,α2,...,αm)优化时,通过这样的改造后的坐标系上升方法实现的,在固定完其余的变量后,W被改造为α2的二次函数,这样通过求得最低点,如果不在可行域的那段斜线上,就取最近的那个作为最优值。即如下图所示:
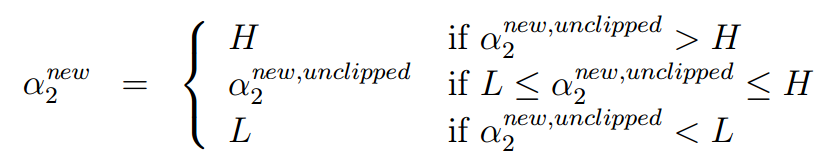
2015-9-10 艺少















 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









