sklearn分类算法的评价指标调用
#二分类问题的算法评价指标
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import datasets
d=datasets.load_digits()
x=d.data
y=d.target.copy()
print(len(y))
y[d.target==9]=1
y[d.target!=9]=0
print(y)
print(pd.value_counts(y))
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=666)
from sklearn.linear_model import LogisticRegression
log_reg=LogisticRegression(solver="newton-cg")
log_reg.fit(x_train,y_train)
print(log_reg.score(x_test,y_test))
y_pre=log_reg.predict(x_test)
def TN(y_true,y_pre):
return np.sum((y_true==0) & (y_pre==0))
def FP(y_true,y_pre):
return np.sum((y_true==0) & (y_pre==1))
def FN(y_true,y_pre):
return np.sum((y_true==1) & (y_pre==0))
def TP(y_true,y_pre):
return np.sum((y_true==1) & (y_pre==1))
print(TN(y_test,y_pre))
print(FP(y_test,y_pre))
print(FN(y_test,y_pre))
print(TP(y_test,y_pre))
def confusion_matrix(y_true,y_pre):
return np.array([
[TN(y_true,y_pre),FP(y_true,y_pre)],
[FN(y_true,y_pre),TP(y_true,y_pre)]
])
print(confusion_matrix(y_test,y_pre))
def precision(y_true,y_pre):
try:
return TP(y_true,y_pre)/(FP(y_true,y_pre)+TP(y_true,y_pre))
except:
return 0.0
def recall(y_true,y_pre):
try:
return TP(y_true,y_pre)/(FN(y_true,y_pre)+TP(y_true,y_pre))
except:
return 0.0
print(precision(y_test,y_pre))
print(recall(y_test,y_pre))
from sklearn.metrics import confusion_matrix
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
print((confusion_matrix(y_test,y_pre)))
print(precision_score(y_test,y_pre))
print(recall_score(y_test,y_pre))
print(log_reg.score(x_test,y_test))
def F1(pre,rec):
try:
return (2*pre*rec)/(pre+rec)
except:
return 0.0
print(F1(precision(y_test,y_pre),recall(y_test,y_pre)))
print(F1(0.1,0.9))
print(F1(0,1))
from sklearn.metrics import f1_score
print(f1_score(y_test,y_pre))
print(log_reg.decision_function(x_test))
#改变阈值,可以改变机器学习的召回率和精准率
decision_scores=log_reg.decision_function(x_test)
y_pre2=np.array(decision_scores>=5,dtype="int")
print(precision(y_test,y_pre2))
print(recall(y_test,y_pre2))
print(confusion_matrix(y_test,y_pre2))
y_pre3=np.array(decision_scores>=-5,dtype="int")
print(precision(y_test,y_pre3))
print(recall(y_test,y_pre3))
print(confusion_matrix(y_test,y_pre3))
print(y_pre3)
#绘制出决策边界阈值与精准率和召回率的变化曲线
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
thresholds=np.arange(np.min(decision_scores),np.max(decision_scores),0.1)
pre=[]
rec=[]
for threshold in thresholds:
y_pre11=np.array(decision_scores>threshold,dtype="int")
pre.append(precision_score(y_test,y_pre11))
rec.append(recall_score(y_test,y_pre11))
plt.figure()
plt.plot(thresholds,pre,"r",thresholds,rec,"g")
plt.show()
#输出精确率和召回率曲线
plt.plot(pre,rec,"g",linewidth=5)
plt.show()
#直接在sklearn中调用精准率召回率曲线直接输出相应的精准率变化和召回率变化以及决策阈值
from sklearn.metrics import precision_recall_curve
decision_scores=log_reg.decision_function(x_test)
pre1,rec1,thre1=precision_recall_curve(y_test,decision_scores)
print(rec1.shape)
print(pre1.shape)
print(thre1.shape)
plt.figure()
plt.plot(thre1,pre1[:-1],"r")
plt.plot(thre1,rec1[:-1],"g")
plt.show()
plt.plot(pre1,rec1)
plt.show()
#sklearn中调用ROC(TPR与FPR曲线)
from sklearn.metrics import roc_curve
decision_scores=log_reg.decision_function(x_test)
fpr,tpr,thre2=roc_curve(y_test,decision_scores)
plt.plot(fpr,tpr,"r")
plt.show() #曲线和x轴所围成的面积越大则性能越好一点
from sklearn.metrics import roc_auc_score
print(roc_auc_score(y_test,decision_scores)) #输出ROC与x轴围成的面积大小roc_auc
#多分类问题下的各个评判指标应用
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import datasets
d=datasets.load_digits()
x=d.data
y=d.target
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=666)
from sklearn.linear_model import LogisticRegression
log1=LogisticRegression()
log1.fit(x_train,y_train)
print(log1.score(x_test,y_test))
y_p=log1.predict(x_test)
from sklearn.metrics import precision_score
print(precision_score(y_test,y_p,average="micro")) #输出精准率的大小(需要设定average参数)
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test,y_p)) #输出混淆矩阵
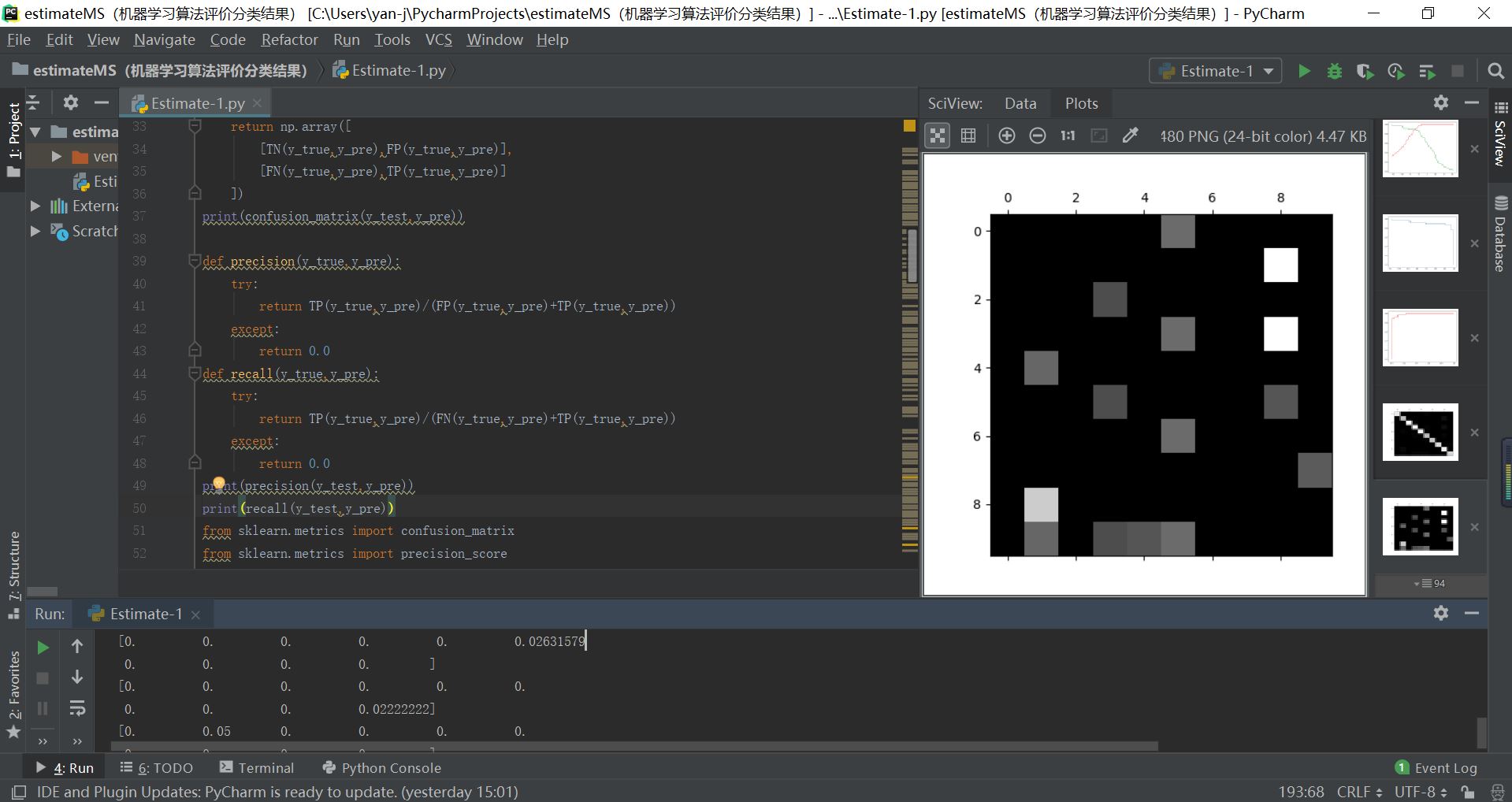
#绘制混淆矩阵通过灰度图的方法可以看出各个行列元素的相对大小
c=confusion_matrix(y_test,y_p)
plt.matshow(c,cmap=plt.cm.gray)
plt.show()
row_sum=np.sum(c,axis=1)
erro_matrix=c/row_sum
np.fill_diagonal(erro_matrix,0) #将对角线的值填充为0
print(erro_matrix)
plt.matshow(erro_matrix,cmap=plt.cm.gray) #输出多元分类结果时所输出的错误结果
plt.show()





















 1412
1412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









