







基础知识
首先我们了解一些基础知识(注:文中图片皆可点击放大查看!):
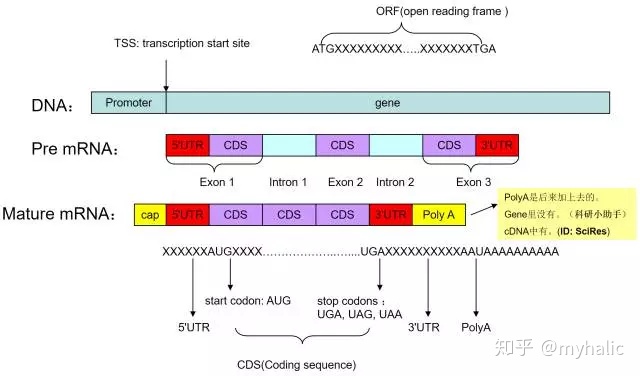
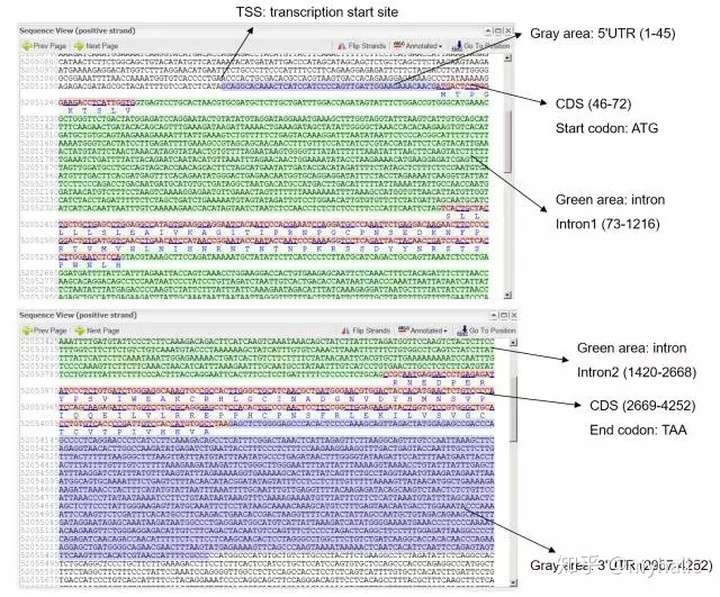
启动子(promoter):与RNA聚合酶结合并能起始mRNA合成的序列。转录起始点(TSS):转录时,mRNA链第一个核苷酸相对应DNA链上的碱基,通常为一个嘌呤。
UTR(Untranslated Regions):即非翻译区,是信使RNA(mRNA)分子两端的非编码片段。 5'-UTR从mRNA起点的甲基化鸟嘌呤核苷酸帽延伸至AUG起始密码子,3'-UTR从编码区末端的终止密码子延伸至多聚A尾巴(Poly-A)的末端。
1查找基因的启动子区域-NCBI
1. 打开PubMed:https://www.ncbi.nlm.nih.gov/pubmed
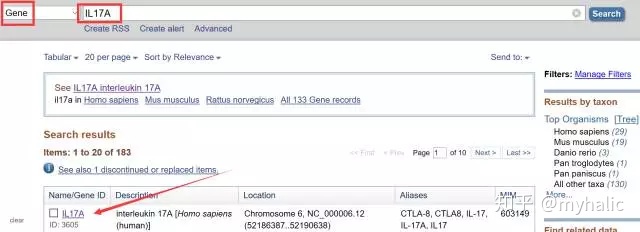
2. 选择Gene,输入IL17A,点击search,结果如下图,点击第一个:
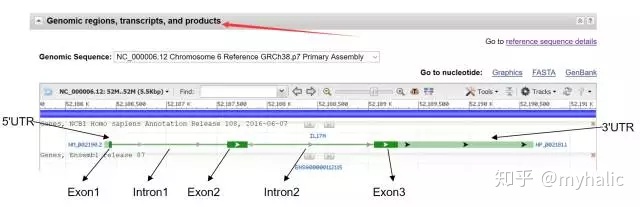
3. 下拉到下图位置,可以看到该基因的以下信息:
点击Tools,选择Sequence Text View:
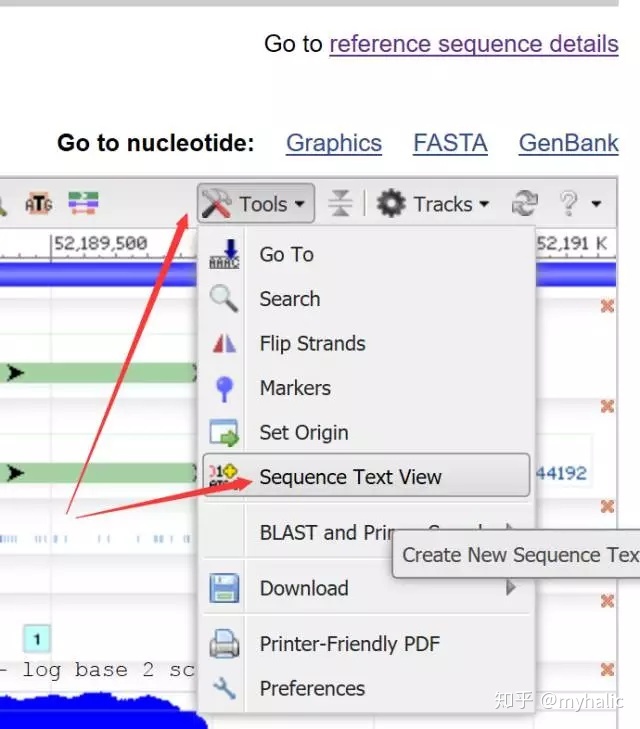
还可以看到如下序列信息:
4. 以上只是该基因的一些信息,可以用于查找相应的UTR等区域,下面进入正题,寻找promoter区域。还是拉到如下图位置,点击FASTA:

5. 基因位置信息如下图:

6. 一般认为基因上游2 kb区域为该基因的promoter区域,所以将基因上游2 kb序列调出来:
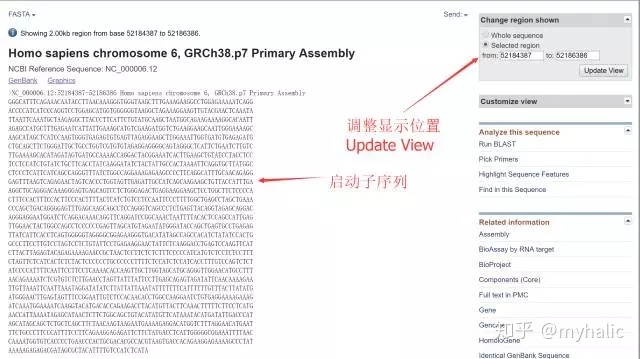
7. 复制上述序列就是基因的启动子序列了。
2查找基因的启动子区域-UCSC
1. 打开UCSC:http://www.genome.ucsc.edu/,点击Table Browser:
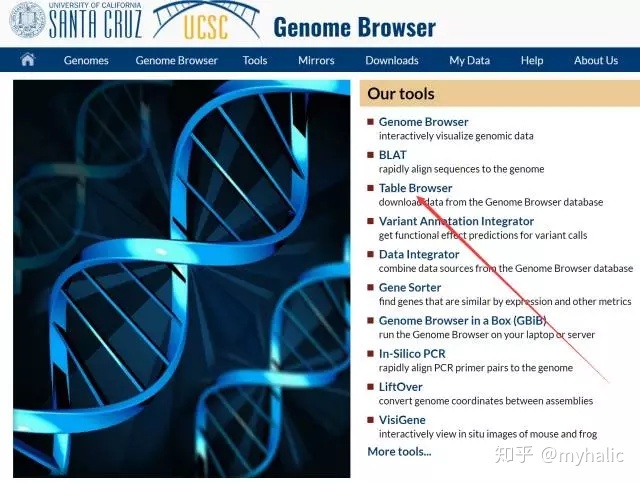
2. 按照下图所示填好基因相关信息,点击get output:
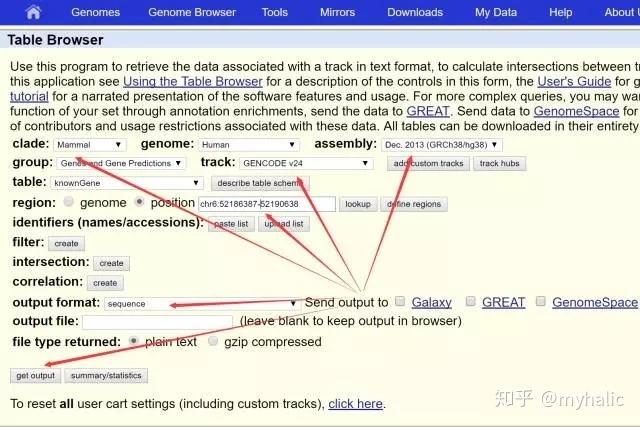
3.选择genomic:
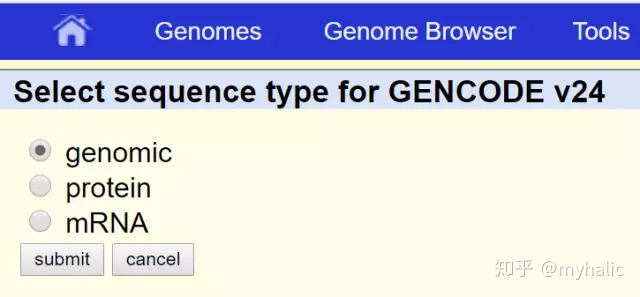
4. 勾选Promoter/Upstream by选项,并将其改为2000 bases,然后点击get sequence:

5. 得到下面的序列信息,开头直到第一个大写字母前面的所有小写字母序列即为该基因的promoter序列,你可以跟NCBI上得到的序列比对一下,看看是不是一样的呢?

6. 当然查找promoter的网站有很多,比如UCSC,在这里就不介绍了,大家可以自行探索,或者加小编微信amateur_1988交流。
3转录因子结合位点的预测
1. 打开http://jaspar.genereg.net/(我这边这个网址暂时打不开了,所以我登录了这个网址:http://jaspardev.genereg.net/),输入转录因子NFAT,点击Quick Search:
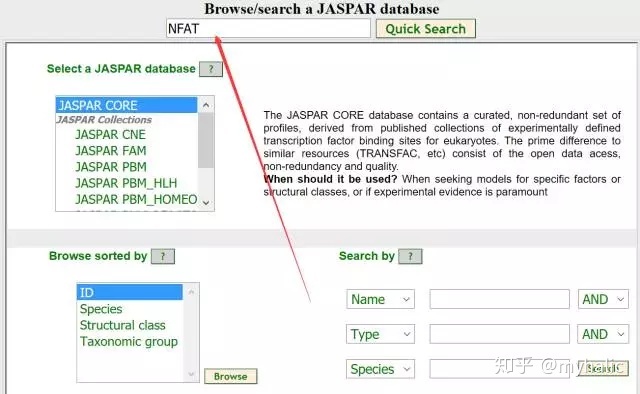
2. 将promoter序列粘贴进入右下角的框中,选中左侧转录因子,点击SCAN:
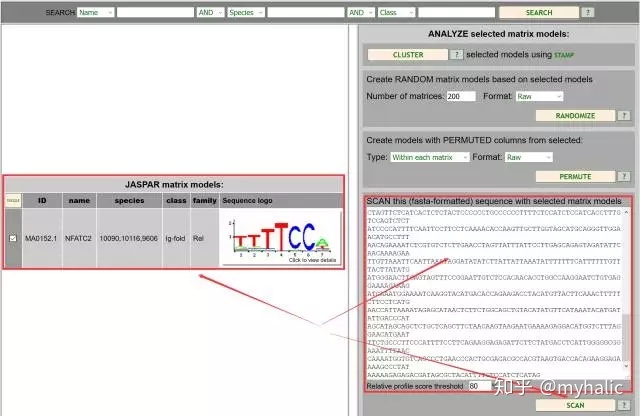
3. 得到28条转录因子NFAT与IL17A的结合位点,其中Strand -1没有特殊意义,只需选择Strand 1即可。
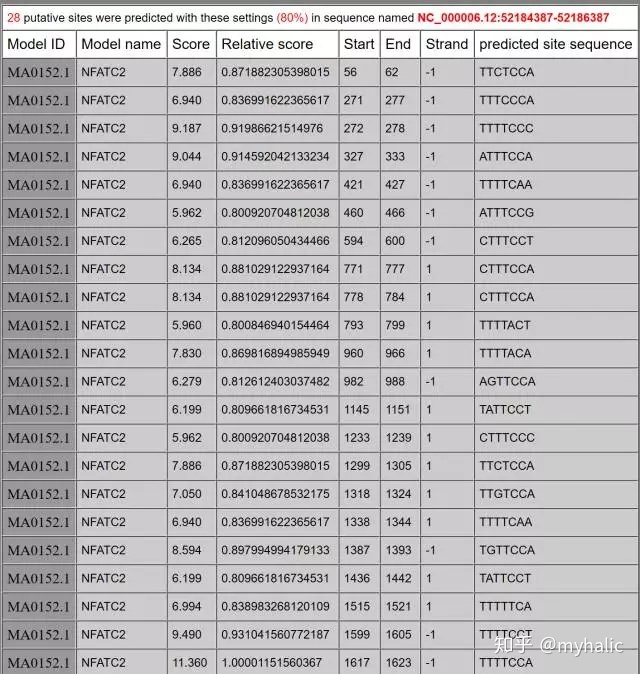
4. 好了,转录因子与promoter结合位点已经有了,接下来就是愉快的通过实验验证了!Luciferase、点突变、截短、ChIP等统统拉上来就可以了!
文章转自微信公众号科研小助手















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









