







简介:本项目着重于在RK3568处理器上实现人脸检测和人脸五点关键点检测的AI应用。RK3568是一款专为嵌入式AI设计的高性能低功耗SoC,提供了CPU、GPU及AI加速器等强大硬件支持。项目将通过使用深度学习模型如MTCNN和基于CNN的方法来完成人脸检测和关键点识别任务。此外,还包含了从数据准备到模型移植、硬件集成和性能优化的完整开发流程。项目资料包括源代码、模型文件和使用说明,旨在帮助开发者掌握如何在资源受限的硬件上实现高效的人脸识别技术。 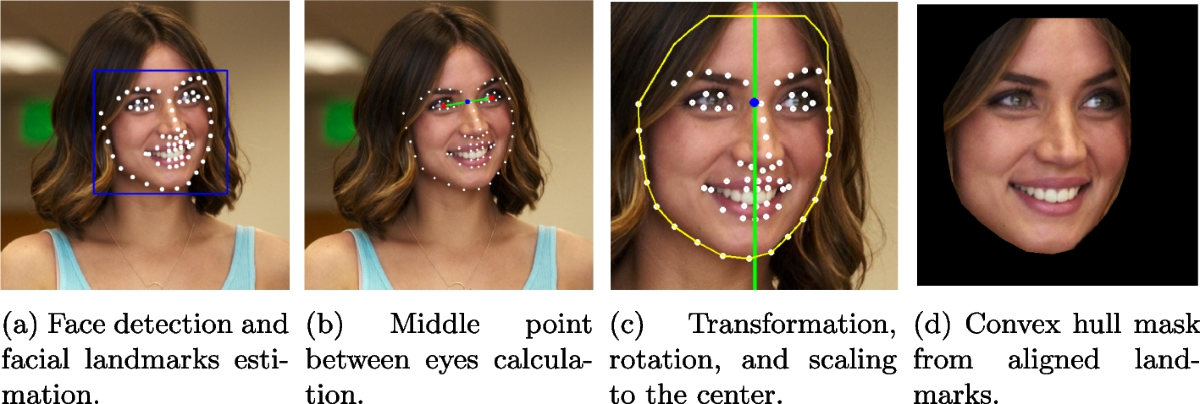
1. RK3568处理器特性与应用
1.1 RK3568处理器概览
RK3568是一款由瑞芯微电子(Rockchip)推出的高效能处理器,集成了高性能的CPU、GPU和NPU,特别适合用于边缘计算、多媒体处理、人工智能等应用领域。它采用了64位ARM架构,具备出色的处理能力和能效比,支持多种操作系统,为开发者提供了极大的便利和灵活性。
1.2 核心特性详解
RK3568的核心特性包括: - 多核ARM Cortex-A55 CPU :支持多线程应用,保证了高效的数据处理能力。 - ARM Mali-G52 GPU :提供了强大的图形处理能力,支持最新的图形API,如OpenGL ES 3.2和Vulkan。 - APU NPU :集成的神经网络处理单元,可以支持机器学习和深度学习模型的加速执行。 - 丰富的接口支持 :包括USB、HDMI、PCIe等,方便与各种外设集成。
1.3 应用场景与优势
RK3568的应用场景非常广泛,包括但不限于: - 智能监控摄像头 - AI语音助手和智能音箱 - 便携式媒体播放器 - 智能网络设备
其优势在于: - 高性能与低功耗 :平衡了性能和能源消耗,满足长时间运行的要求。 - 强大的多媒体处理能力 :为视频编解码和图像处理提供了强大支持。 - AI能力 :提供硬件加速AI能力,优化了相关算法的执行效率。
在接下来的章节中,我们将深入探讨如何将RK3568处理器应用到不同技术场景中,并对其进行性能优化和轻量化处理。
2. 人脸检测技术与深度学习模型
2.1 人脸检测基础理论
人脸检测是计算机视觉中的一个基础任务,它通过自动化的算法来定位图像中人脸的位置,并给出人脸存在的置信度。其目的是从图像或视频中找到所有的人脸,并将它们与其他物体区别开来。人脸检测的应用非常广泛,包括安全监控、人机交互、图像编辑和增强现实等领域。
2.1.1 人脸检测技术的发展历程
从20世纪90年代起,随着图像处理技术和机器学习方法的不断进步,人脸检测技术开始迅速发展。最初的尝试主要集中在基于规则和模板匹配的方法上,这些方法依赖于特定的人脸几何特征,如眼睛、鼻子和嘴巴的位置。然而,这种方法往往受限于光线、表情和姿态变化。
进入21世纪初,随着深度学习的兴起,人脸检测技术迎来了重大突破。基于深度学习的人脸检测模型,如卷积神经网络(CNN),能够从大规模数据集中自动学习特征表示,显著提高了检测的准确度和鲁棒性。特别是近年来,基于深度学习的目标检测框架,如R-CNN、YOLO和SSD,使得人脸检测的速度和准确率都有了质的提升。
2.1.2 当前主流的深度学习模型介绍
目前,基于深度学习的人脸检测模型主要分为两类:一类是一阶段检测器,如YOLO和SSD,它们在单个神经网络中直接预测边界框和类别概率,具有检测速度快的优点;另一类是两阶段检测器,以Faster R-CNN为代表,它们先生成候选框,然后对候选框进行分类,这种方法检测准确度更高,但速度相对较慢。
2.2 人脸检测模型的选择与应用
选择一个适合应用需求的人脸检测模型是关键,因为不同的模型有不同的性能特点,包括准确率、速度和资源消耗等。
2.2.1 模型选择的标准与考量因素
当选择人脸检测模型时,需要考虑以下因素:
- 实时性要求 :应用是否需要实时或接近实时的检测速度。
- 准确率 :在某些应用中,如安全监控,高准确率可能比速度更为重要。
- 硬件资源 :不同模型对计算能力和内存的需求不同,需要根据可用硬件资源做出选择。
- 鲁棒性 :在不同的环境和条件下(如不同的光照、表情和姿态变化)模型的稳定性如何。
2.2.2 应用案例分析:RK3568与人脸检测模型的集成
RK3568是一款高性能的处理器,专为边缘计算和AI应用设计。它内置了NPU(神经网络处理单元),能够高效地执行深度学习任务,对于人脸检测等视觉任务来说是一个理想的选择。通过将人脸检测模型与RK3568平台集成,可以开发出各种智能应用,如智能监控摄像头、智能门禁系统等。
在集成过程中,开发者需要将预训练好的深度学习模型转换为RK3568平台支持的格式,并使用其SDK或工具链进行部署。此外,开发者还需要对模型进行优化,以确保在资源有限的边缘设备上也能获得良好的性能。
# 示例代码:将TensorFlow模型转换为RK3568支持的格式
# 假设已有TensorFlow训练好的模型文件model.pb和权重文件model.ckpt
# 使用RKNN-Toolkit将模型转换为RKNN格式
# 注意:以下步骤需要在RK3568开发环境中执行,确保已安装RKNN-Toolkit
rknn_toolkit convert \
-i model.pb \
-w model.ckpt \
-o rknn_model.rknn \
--input_shape 1,3,224,224 \
--target_opset 12 \
--opt_npu True \
--opt_cpu True \
--opt蝌蚪 True
在上述示例代码中,我们使用了RKNN-Toolkit工具包将TensorFlow模型转换为RKNN格式。这一步骤涉及模型文件的指定、权重文件的指定、输出文件格式、输入张量的形状、目标算子集版本以及针对RK3568的NPU和CPU优化选项。代码执行后,开发者将得到一个优化过的RKNN模型文件,可用于RK3568平台。
转换完成后,开发者可以利用RK3568提供的SDK开发人脸检测应用,并在该平台上运行。在这个过程中,需要对RK3568的性能进行测试,评估模型在目标硬件上的实际表现。通过这种方式,RK3568处理器能够发挥其强大的计算能力,为各种AI应用提供支持。
3. 人脸五点关键点检测技术与深度学习模型
3.1 关键点检测基础理论
3.1.1 关键点检测技术的演变
关键点检测技术,亦称作关键点定位或特征点检测,是一种用于定位图像中特定对象的显著特征点的技术。这种技术最早可以追溯到计算机视觉诞生之初,初期多采用手工设计的特征和算子,例如SIFT、HOG等描述符,但随着深度学习的出现,基于卷积神经网络(CNN)的关键点检测方法逐渐成为主流。
深度学习方法通过端到端的训练,能够自动学习从输入图像到关键点坐标的复杂映射,极大提高了检测的准确度和鲁棒性。近年来,关键点检测技术已从最初的手势识别、面部表情分析等简单的二维关键点检测,发展到今天能准确检测人体姿态、面部表情、手势等的三维关键点。
3.1.2 深度学习在关键点检测中的作用
在深度学习框架下,关键点检测主要依赖于卷积神经网络(CNN)的高级特征提取能力,以及回归或分类策略的联合使用。卷积神经网络特别是深度卷积网络对于图像特征的提取具有天然的优势,它们能够逐层抽象出图像中的不同层次的特征,这对于定位关键点至关重要。
利用深度学习,研究者们开发了诸多有效的网络结构,例如Hourglass网络、Stacked Hourglass网络和DeepPose等,这些网络在关键点检测任务中取得了显著的成果。特别是在解决关键点定位的精确性和检测多对象关键点(如人体姿态估计)的能力上,深度学习的方法展现出了巨大的优势。
3.2 关键点检测模型的选择与优化
3.2.1 模型的选择与精度平衡
在关键点检测任务中,选择一个合适的模型需要在检测精度、计算资源和响应速度之间做出平衡。例如,对于实时性要求较高的应用场景,可能需要选择一个速度快但精度略低的模型;对于精度要求极高的任务,则可能选用计算量大但精度更高的复杂模型。
当前,已有许多经典的模型在关键点检测领域得到了验证和应用,包括但不限于MobileNet、EfficientNet和DenseNet等。这些模型通常有各自的变体版本,通过改变网络结构、深度或宽度来适应不同性能需求的任务。选择合适的模型需要充分考虑到应用场景和硬件限制,以及优化模型以便更好地适应特定任务。
3.2.2 模型优化策略与效果评估
关键点检测模型的优化策略通常包含但不限于模型剪枝、量化、蒸馏以及知识蒸馏等技术。模型剪枝主要是去除冗余的网络参数来减少模型大小和推理时间;量化则是将模型的浮点权重转换为低比特的表示,这可以加快计算速度并减少模型存储需求;而蒸馏是将大模型的知识转移到小模型中,以此来保持准确率的同时降低模型复杂度。
效果评估通常包括准确率、召回率、F1分数等指标,同时也会考虑模型的推理速度和模型大小。在进行优化前,应先在标准数据集上测试模型的基准性能,之后才根据需要对模型进行优化。优化后需要重新评估模型性能,确保在提升效率的同时不牺牲太多的准确度。
| 模型类型 | 准确率 | 推理时间(ms) | 模型大小(MB) | 硬件需求 |
| -------------- | ------ | -------------- | -------------- | ---------------- |
| MobileNet | 90.0% | 20 | 15 | 高性能移动设备 |
| EfficientNet | 92.0% | 30 | 20 | 中端服务器 |
| DenseNet | 93.5% | 45 | 30 | 高端计算服务器 |
上表展示了不同模型类型在关键点检测任务中的基准性能对比。模型优化后,推理时间和模型大小都有不同程度的改进,但可能伴随着准确率的略微下降。这需要在实际应用中权衡。
代码示例
import torch
import torchvision.models as models
# 加载预训练的MobileNet模型
mobilenet = models.mobilenet_v2(pretrained=True)
# 评估模型的推理时间
input_tensor = torch.randn(1, 3, 224, 224)
with torch.no_grad():
start_time = time.time()
output = mobilenet(input_tensor)
end_time = time.time()
print(f"Inference Time: {end_time - start_time} seconds")
上述代码展示了如何加载一个预训练的MobileNet模型,并在标准输入张量上运行以测量其推理时间。通过评估不同模型的推理时间,开发者能够选择最适合其应用场景的模型。
模型优化后的参数调整和训练
当对模型进行优化如剪枝、量化之后,可能需要对模型的训练过程中的超参数进行调整。优化后的模型可能会面临过拟合的风险,需要增加数据增强、正则化项或是调整学习率等策略。在训练过程中,持续监控训练和验证集的损失曲线和性能指标,有助于调整模型至最佳状态。
优化流程涉及对模型结构的调整,如添加剪枝模块和量化模块等,并在训练过程中进行微调。训练优化流程示例代码:
def prune_and_quantize_model(model, pruning_ratio, quantization_bits):
"""
对模型进行剪枝和量化。
"""
# 剪枝模型的示例函数
prune_model(model, pruning_ratio)
# 量化模型的示例函数
quantize_model(model, quantization_bits)
return model
# 假设已经有了一个预训练模型
pretrained_model = ... # 预训练模型加载代码
# 对模型进行剪枝和量化
optimized_model = prune_and_quantize_model(pretrained_model, 0.5, 8)
# 使用优化后的模型进行训练和微调
def train_pruned_quantized_model(model, train_loader, val_loader):
"""
使用训练和验证数据集对剪枝和量化后的模型进行训练和微调。
"""
# 训练和微调的示例代码
...
return model
通过执行上述代码,可以得到一个经过剪枝和量化优化的模型,并对该模型进行重新训练以适应该模型的新的结构特性。模型优化后,性能评估和效果对比是必不可少的步骤。
4. 数据准备与模型训练
4.1 数据集的构建与预处理
4.1.1 数据来源与采集方法
在机器学习和深度学习项目中,数据集的质量直接影响到最终模型的性能。高质量的数据集意味着模型能更好地泛化,处理未见过的数据。因此,数据的采集和处理是机器学习工作流程中一个至关重要的步骤。
数据来源多种多样,常见的包括:
- 公开数据集:互联网上存在大量的公开数据集,如ImageNet、COCO、PASCAL VOC等,这些数据集已经过广泛使用,通常也包含预标注的数据,可以直接用于模型训练。
- 在线服务:一些公司提供了带有API接口的数据采集服务,例如通过网络爬虫从社交媒体或专业网站收集图片。
- 实地采集:对于特定的应用场景,可能需要自行通过摄像机、手机相机等方式在实地采集数据。
采集方法必须考虑到数据的多样性和代表性,以确保模型训练的全面性和鲁棒性。同时,为了保护隐私和遵守法律法规,在采集数据时还需要进行相应的伦理审查和数据合规性检查。
4.1.2 数据清洗与标注工具介绍
数据清洗的目的是去除数据集中无用、错误、重复或矛盾的信息。通常的数据清洗步骤包括:
- 缺失值处理:用均值、中位数、众数或基于模型的预测填补缺失值,或直接删除缺失值过多的记录。
- 异常值处理:通过统计分析识别并处理异常值,比如通过箱线图分析法或Z-Score方法。
- 数据格式统一:确保所有的数据都遵循相同的格式,便于后续的处理和分析。
对于图像数据,还需要进行标注,即为图片中的对象指定边界框(bounding box),标注关键点等信息。这一步对于监督学习尤其重要。市面上有多种图像标注工具:
- LabelImg:一个开源的图像标注工具,非常适合标注小规模的数据集,支持Pascal VOC和YOLO格式。
- CVAT:一个开源的Web标注工具,支持视频、图像和点云的标注。
- Labelbox:一个功能强大的商业标注工具,支持多种标注类型,适合大规模的数据集标注。
在数据预处理阶段,选择合适的工具和方法,能够为后续的模型训练奠定坚实的基础。
4.2 模型训练流程与技巧
4.2.1 训练环境的搭建与配置
深度学习模型的训练环境搭建涉及多个方面,包括选择合适的硬件、安装深度学习框架、配置开发环境等。
在硬件选择方面,GPU是深度学习训练中不可或缺的加速器。NVIDIA的GPU由于其CUDA编程模型和cuDNN库的支持,成为了业界的首选。不过,对于 RK3568 这样的嵌入式处理器,更注重的是能效比以及在轻量化模型训练中的表现。
在安装深度学习框架方面,TensorFlow、PyTorch和MXNet是目前较为流行的选择。安装时,可能会遇到依赖冲突问题,建议使用虚拟环境进行隔离,如Python的venv或conda环境。
配置开发环境包括安装必要的库和依赖,如numpy、pandas、scikit-learn等基础数据处理库,以及深度学习框架相关的库。以Python为例,可以通过pip进行安装:
pip install numpy pandas scikit-learn tensorflow
4.2.2 训练过程中问题的诊断与解决
训练深度学习模型是一个试错的过程,会遇到各种各样的问题。以下是几个常见的问题及解决策略:
- 过拟合:通过增加数据量、使用正则化、早停(early stopping)等方法减少过拟合。
- 梯度消失或爆炸:使用批量归一化(batch normalization)、合适的初始化方法和梯度裁剪技术。
- 优化器选择:不同的优化器(SGD、Adam、RMSprop等)对于不同的任务和网络结构表现不同,需要实验性选择。
- 超参数调整:通过网格搜索(grid search)、随机搜索(random search)或贝叶斯优化等方法调整超参数。
- 硬件资源限制:对于资源受限的环境,考虑使用模型剪枝、知识蒸馏、量化等技术来降低模型复杂度。
在训练过程中,实时监控训练指标(如loss和准确率)对于识别和解决上述问题至关重要。此外,日志记录、可视化工具(如TensorBoard)和版本控制系统(如Git)可以提供额外的帮助。
# 示例:使用TensorFlow进行模型训练的代码片段
import tensorflow as tf
# 构建模型
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(input_shape)),
tf.keras.layers.Dense(10, activation='softmax')
])
# 编译模型
***pile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(train_images, train_labels, epochs=10)
# 评估模型
test_loss, test_acc = model.evaluate(test_images, test_labels)
在上述代码中,我们展示了如何使用TensorFlow构建一个简单的多层感知器(MLP)模型,并进行编译和训练。这种训练流程是在准备一个高质量的深度学习模型时不可或缺的步骤。
5. 模型优化与轻量化处理
5.1 模型压缩与量化技术
5.1.1 模型压缩原理与方法
模型压缩技术是指通过各种手段减少深度学习模型的大小和计算需求,以提高其在资源受限设备上的运行效率。在不显著影响模型准确性的前提下,压缩技术主要包括剪枝(Pruning)、知识蒸馏(Knowledge Distillation)、权重共享(Weight Sharing)和参数量化(Parameter Quantization)等方法。
- 剪枝 是一种减少模型大小的方法,通过去除神经网络中的一些不重要的连接或神经元,减少模型的复杂度。
- 知识蒸馏 是通过训练一个小型网络来学习一个大型网络的软输出分布,以此来保留知识。
- 权重共享 通过限制网络中不同部分使用相同的参数来减少模型大小。
- 参数量化 则是将模型中的浮点数权重转换为低位数的表示,如将32位浮点转换为8位整数。
这些方法可以单独使用,也可以组合使用以达到更好的压缩效果。
5.1.2 量化的概念及其对性能的影响
量化是一种降低模型精度以减少模型大小和提高运算速度的技术。将模型的参数从32位浮点数(FP32)转换为16位、8位甚至更低位的整数(INT8, INT16)可以显著降低模型的存储和计算要求。量化的好处在于它减少了内存占用、加快了推理速度,同时降低了功耗,这对于边缘计算设备如RK3568处理器来说是极其重要的。
量化过程中,为了保持模型性能,可能需要引入校准数据集来校正量化带来的误差。通过校准,我们可以找到最优的量化策略,以最小化精度损失。
5.2 轻量化模型的部署与测试
5.2.1 部署策略的考虑与选择
在部署轻量化模型到边缘设备时,需要考虑多种策略,例如模型转换、资源分配和性能优化。在模型转换阶段,可以使用如TensorRT等工具将训练好的模型转换为适合特定硬件平台运行的格式。在资源分配方面,需要合理配置内存和计算资源,确保模型能够高效运行。性能优化可能包括对模型进一步的微调,或调整运行时的参数设置以适应目标平台的特性。
5.2.2 在RK3568上测试轻量化模型的性能
在RK3568处理器上测试轻量化模型的性能时,重点关注模型的推理速度、内存占用和功耗等指标。可以通过一系列基准测试来评估模型在该平台上的表现。这些测试应包括不同场景下的模型运行情况,如静态图像识别和实时视频处理等。通过比较优化前后的性能数据,可以验证模型优化和轻量化的效果。此外,采用诸如平均帧率、模型响应时间等指标来衡量模型的实际运行效率。
具体的测试流程包括:
- 准备测试环境:确保RK3568的开发板已正确安装所有必要的驱动和软件。
- 部署轻量化模型:通过适当的工具或库将模型部署到设备上。
- 执行基准测试:利用标准测试集和实际应用场景测试模型性能。
- 记录和分析结果:详细记录模型在不同测试下的性能表现,包括推理时间和资源消耗。
- 优化与调优:根据测试结果调整模型参数或优化策略,然后重复测试直到满足性能要求。
简介:本项目着重于在RK3568处理器上实现人脸检测和人脸五点关键点检测的AI应用。RK3568是一款专为嵌入式AI设计的高性能低功耗SoC,提供了CPU、GPU及AI加速器等强大硬件支持。项目将通过使用深度学习模型如MTCNN和基于CNN的方法来完成人脸检测和关键点识别任务。此外,还包含了从数据准备到模型移植、硬件集成和性能优化的完整开发流程。项目资料包括源代码、模型文件和使用说明,旨在帮助开发者掌握如何在资源受限的硬件上实现高效的人脸识别技术。

















 2260
2260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









