






一、过拟合与正则化作用
1、先了解什么是过拟合
了解什么是过拟合问题,以下面图片为例,我们能够看到有两个类别,蓝色是分类曲线模型。
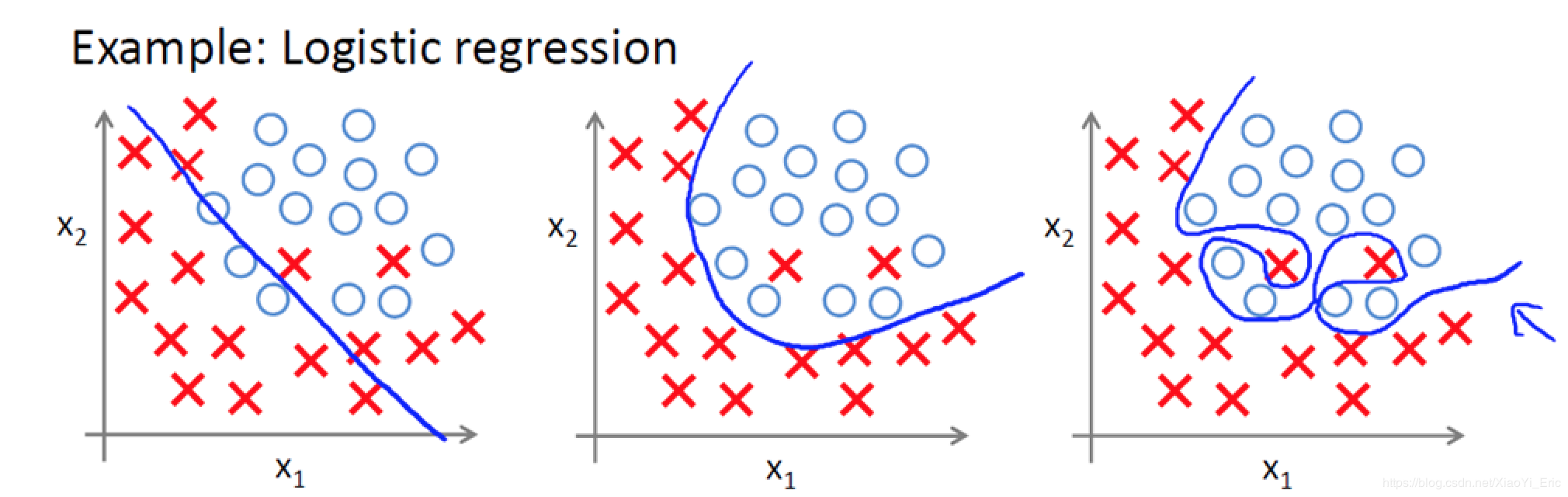
- 欠拟合:图1分类,不能很好的将X和O很好的分类,属于欠拟合。
- 正拟合:图2有两个X被误分类,但是大部分数据都能很好的分类,误差在可接受范围内,分类效果好,属于良好的拟合模型。
- 过拟合:图3虽然能够全部分类正确,但分类曲线明显过于复杂,模型学习的时候学习了过多的参数项,但其中某些参数项是无用的特征。当我们进行识别测试集数据时,就需要提供更多的特征,如果测试集包含海量的数据,模型的时间复杂度可想而知。
2、正则化作用
模型过拟合是因为模型过于复杂,可以通过对特征变量系数的调整来避免过拟合,而引入正则化正是为了实现这个目的,具体如何实现将在下一节说明。
常见的正则化方法有这几种:
- 当参数是向量的时候(如logistics回归,参数为$\left (\theta _{i}:\theta _{1},\theta _{2},...,\theta _{n} \right )$),有L1正则化、L2正则化。
- 当参数是矩阵的时候(如神经网络的权重矩阵W),这时候用的是F-1范数正则化、F-2范数正则化,现在基本都是使用F-2范数正则化比较多。
- 神经网络还有Drop正则化。
- 增加训练集的数据量可以避免过拟合,另外有些模型可以用集成学习的Bagging、boost方法来进行正则化。
二、神经网络的L1、L2正则化
1、矩阵的F-1范数、F-2范数
说明:这里的F-范数指的是Frobenius范数,和logistics回归的L1、L2正则化的向量范数不一样。
矩阵的F-1范数:矩阵所有元素的绝对值之和。公式为:
$$\left \| W \right \|_{1}=\sum_{i,j}\left |\omega _{i,j} \right |$$
矩阵的F-2范数:矩阵所有元素的平方求和后开根号。公式为:
$$\left \| W \right \|_{2}=\sqrt{\sum_{i,j}\left (\omega _{i,j} \right )^{2}}$$
2、L1正则化与L2正则化
假设神经网络的损失函数为J(W,b),参考逻辑回归的正则化,是在损失函数J(W,b)后面加一个正则化项,神经网络DNN也是一样的,只是变成了加F-范数,L1正则化与L2正则化如下所示:
$$L1: J(W,b)+\frac{\lambda }{2m}\sum_{l\epsilon L}\left \| W \right \|_{1}=J(W,b)+\frac{\lambda }{m}\sum_{l\epsilon L}\sum_{i,j}\left |\omega _{i,j} \right |$$
$$L2: J(W,b)+\frac{\lambda }{2m}\sum_{l\epsilon L}\left \| W \right \|_{2}=J(W,b)+\frac{\lambda }{2m}\sum_{l\epsilon L}\sqrt{\sum_{i,j}\left (\omega _{i,j} \right )^{2}}$$
这里m为样本数,l为各个隐藏层,$\lambda$为超参数,需要自己调试,L2中2m是为了后面求梯度的时候可以抵消掉常数2。
3、以L2正则的权重衰减防止过拟合
由于L1正则与L2正则原理相似,而且大多数神经网络模型使用L2正则,所以这里以L2为例来说明为什么能防止过拟合。
直观理解:
原损失函数$J(W,b)$加上正则项$\frac{\lambda }{2m}\sum_{l\epsilon L}\left \| W \right \|_{2}$之后的新损失函数$J(W,b)^{'}=J(W,b)+\frac{\lambda }{2m}\sum_{l\epsilon L}\left \| W \right \|_{2}$,在使用梯度下降训练模型时,目标是要最小化新的损失函数$ J(W,b)^{'}$,我们在训练前先设置超参数$\lambda$,若设置较大的超参数$\lambda=0.9$,则相对于设置较小的超参数$\lambda=0.1$,我们需要更小的权重F-2范数$\left \| W \right \|_{2}$才能够使得我们达到最小化$ J(W,b)^{'}$的目的。所以如果我们使用较大的超参数$\lambda$的时候,会使得W整体变得更加的稀疏,这样就可以使得W的影响减少,从而避免了由于模型过于复杂导致的过拟合。
公式推导(以平方差损失函数为例,即$J(W,b)=\frac{1}{2m}\sum_{m}\left \| a^{L}-y \right \|_{2}^{2}$):
$$原损失函数:$$J(W,b)$$
$$原损失函数对第l层的权重矩阵W求梯度:$$\frac{J(W,b) }{\partial W^{l}}$$
$$原损失函数的W迭代公式为:$$W^{l}=W^{l}-\alpha \frac{J(W,b) }{\partial W^{l}},其中\alpha为学习率$$
$$新损失函数:$$J(W,b)^{'}=J(W,b)+\frac{\lambda }{2m}\sum_{l\epsilon L}\left \| W \right \|_{2}$$
$$新损失函数对第l层的权重矩阵W求梯度:$$\frac{J(W,b)^{'} }{\partial W^{l}}=\frac{J(W,b) }{\partial W^{l}}+\frac{\lambda }{m}W^{l}$$
$$新损失函数的W迭代公式为:$$W^{l}=W^{l}-\alpha \frac{J(W,b) }{\partial W^{l}}-\alpha \frac{\lambda }{m}W^{l}=\left ( 1- \alpha \frac{\lambda }{m}\right )W^{l}-\alpha \frac{J(W,b) }{\partial W^{l}},其中\alpha为学习率$$
对比原迭代公式与新迭代公式可以发现,原迭代公式W的系数为1,新迭代公式的系数为$\left ( 1- \alpha \frac{\lambda }{m}\right )$,由于$\alpha$、$\lambda$、m都是正数,所以新迭代公式在原来的基础上使权重矩阵W进行了缩减,使得W变得更小,这就是L2正则的权重衰减,这样可以使得一些权重的值等于或更接近与0,从而减少了一些权重的影响,以极端情形来说,如果衰减后权重为零,即该神经元的影响为0,相当于神经元从神经网络中去除,这样就减少了神经元的个数,从而降低了模型的复杂度,防止了过拟合。
4、L1正则化与L2正则化的区别
L1 正则化项的效果是让权值 W 往 0 靠,使网络中的权值尽可能为 0,也就相当于减小了网络复杂度,防止过拟合。事实上,L1 正则化能产生稀疏性,导致 W 中许多项变成零。
L2 正则化项的效果是减小权值 W。事实上,更小的权值 W,从某种意义上说,表示网络的复杂度更低,对数据的拟合刚刚好。
三、神经网络的Drop正则化
说明:所谓的Dropout指的是在用前向传播算法和反向传播算法训练DNN模型时,一批数据迭代时,随机的从全连接DNN网络中去掉一部分隐藏层的神经元,下面用两个图来解释:
原始的神经网络结构:

在对训练集中的一批数据进行训练时,我们随机去掉一部分隐藏层的神经元(在训练模型的时候通常选择随机去除50%的神经元,长期实践证明效果较好),如下图:

总结Drop:去掉的神经元只是在当前的批次数据迭代中才去除,在下一批数据迭代的时候,要把DNN模型恢复成最初的全连接模型,再随机去掉部分隐藏层的神经元,接着去迭代更新W,b,每批数据迭代更新完毕后,要将残缺的DNN模型恢复成原始的DNN模型。
注意:Drop只有在数据量大的时候才能够使用,若数据量小可能会造成欠拟合的情况,另外,可以在容易造成过拟合的隐藏层使用Drop正则化。















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









