






一.部署
1. 先把项目Clone下来
git clone https://github.com/jfzhang95/pytorch-video-recognition.git
2. 安装环境:
PyTorch 的安装可以参考这里https://pytorch.org/
pip install opencv-python tqdm scikit-learn tensorboardX
3.下载C3D预训练模型:
在项目目录下新建一个models目录,用来存放预训练模型
百度云地址:https://pan.baidu.com/s/1saNqGBkzZHwZpG-A5RDLVw
GoogleDrive:https://drive.google.com/file/d/19NWziHWh1LgCcHU34geoKwYezAogv9fX/view?usp=sharing
二.准备数据
本次实验用的是公开数据集UCF101,
下载地址:https://www.crcv.ucf.edu/datasets/human-actions/ucf101/UCF101.rar
如果是自己准备数据,按照下面方法来做
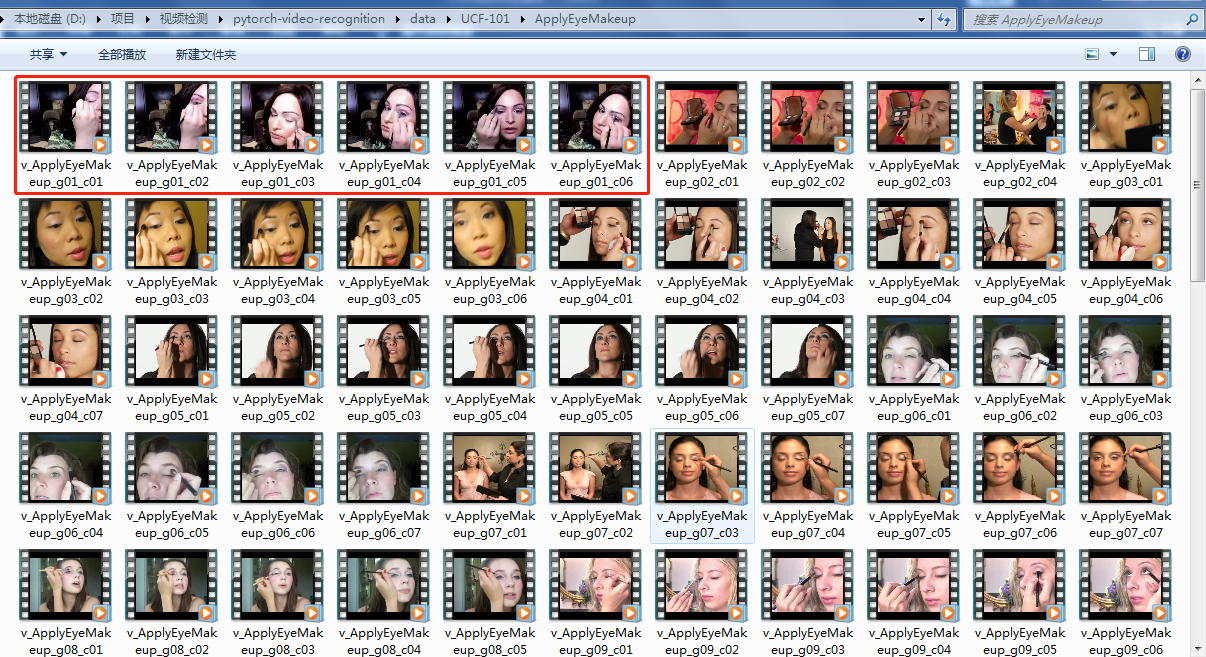
在项目目录下创建一个data目录,将数据集放在data目录下,每一个视频分类为一个文件夹,视频名称以v开头,”_”分隔,中间为类别名称,g01,g02依次类推,如果视频太长就分割成多个,名称在g01后再加上c01,c02以此类推,每个视频大小控制在500k内。结构如下:
data
├──UCF-101
├── ApplyEyeMakeup
│ ├── v_ApplyEyeMakeup_g01_c01.avi
│ └── ...
├── ApplyLipstick
│ ├── v_ApplyLipstick_g01_c01.avi
│ └── ...
└── Archery
│ ├── v_Archery_g01_c01.avi
│ └── ...
视频名称参见下图:
三.训练模型
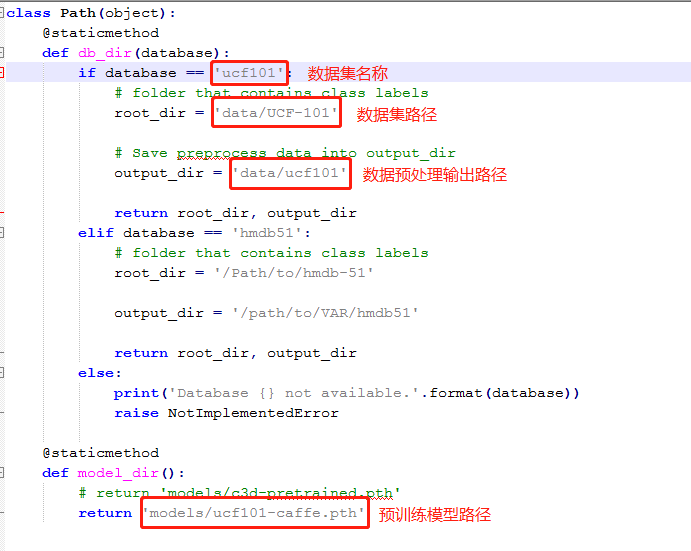
1. 修改数据集和预训练模型路径,在mypath.py文件中需要改四个位置,参考下图:
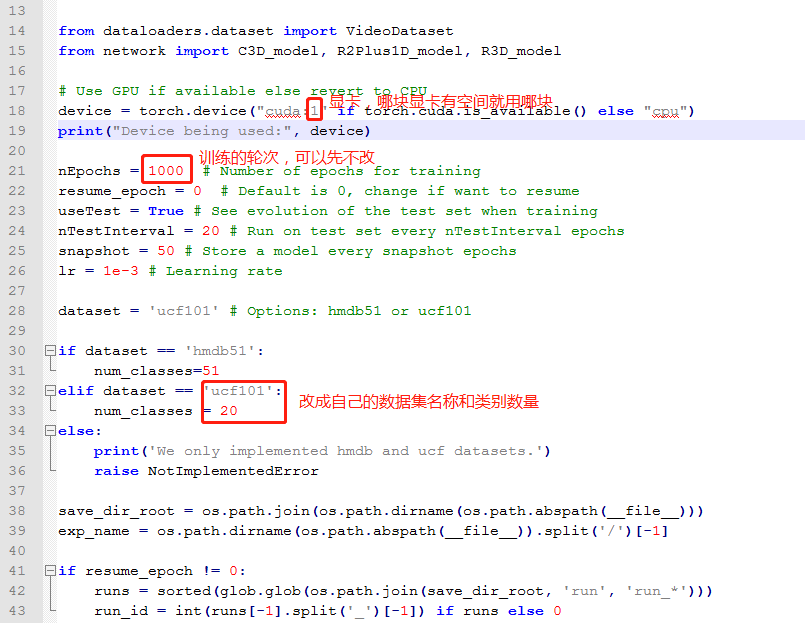
2. 训练模型,在train.py文件中需要修改
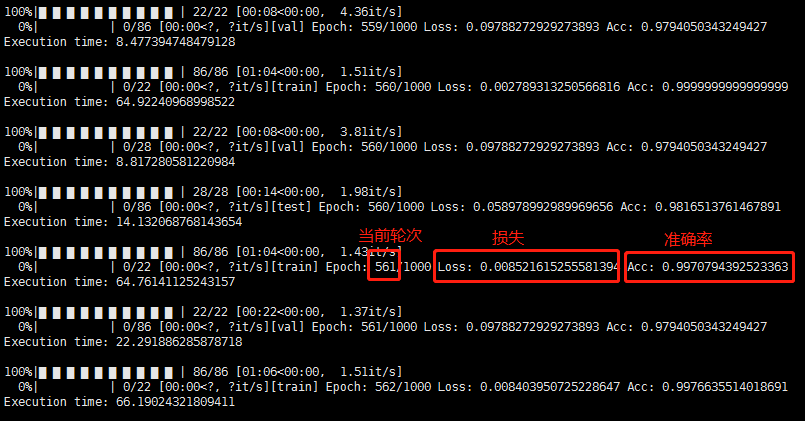
训练过程中的输出:
训练完成后会在run文件夹中生成模型,run目录下最后一个文件夹就是最新模型路径
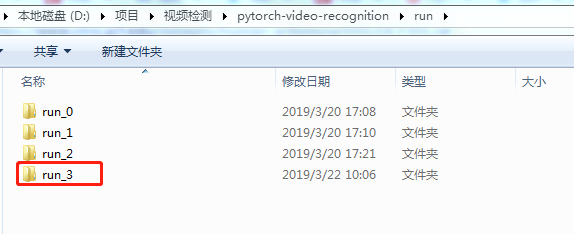
3. 预测,修改inference.py文件
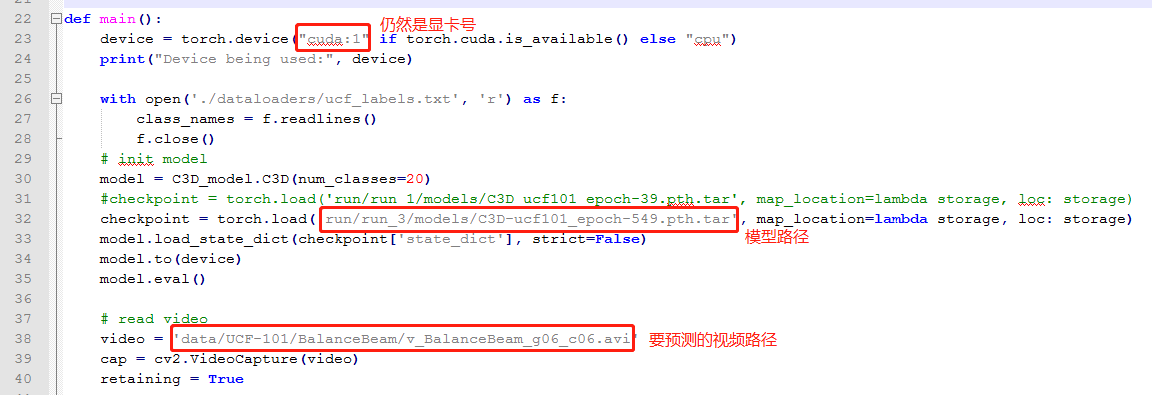
测试结果:
















 149
149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









