






理论知识:Deep learning:四十一(Dropout简单理解)、深度学习(二十二)Dropout浅层理解与实现、“Improving neural networks by preventing co-adaptation of feature detectors”
感觉没什么好说的了,该说的在引用的这两篇博客里已经说得很清楚了,直接做试验吧
注意:
1.在模型的测试阶段,使用”mean network(均值网络)”来得到隐含层的输出,其实就是在网络前向传播到输出层前时隐含层节点的输出值都要减半(如果dropout的比例为p=50%),其理由如下:
At test time, we use the “mean network” that contains all of the hidden units but with their outgoing weights halved to compensate for the fact that twice as many of them are active.
即:因为神经元被激活的概率被增加了两倍(因为被激活神经元数量少了一半),所以为了补偿这一点,它的权值就要减少一半。
当然,这一点补偿可以是在训练的时候,对x进行放大(除以1-p),也可以是在测试的时候,对权重进行缩小(乘以概率p)。
2.Deep learning:四十一(Dropout简单理解)中有一点很容易让人误解:
Deep learning:四十一(Dropout简单理解)实验中nn.dropoutFraction和深度学习(二十二)Dropout浅层理解与实现实验中的level是指该神经元被dropout(即:丢弃)的概率,而论文“Dropout: A simple way to prevent neural networks from overfitting”中的概率p是指神经元被present(即:被选中不被dropout)的概率。即:p=1 - dropoutFraction = retain_prob = 1 - level。不搞清楚这一点,在看代码的时候很容易误解Deep learning:四十一(Dropout简单理解)实验中的代码跟论文“Dropout: A simple way to prevent neural networks from overfitting”中说的不一样,但其实是一样的。
所以,在论文“Dropout: A simple way to prevent neural networks from overfitting”中有指出:
经过上面屏蔽掉某些神经元,使其激活值为0以后,我们还需要对向量x1……x1000进行rescale,也就是乘以1/(1-p)。如果你在训练的时候,经过置0后,没有对x1……x1000进行rescale,那么你在测试的时候,就需要对权重进行rescale:
3.论文中明明说的是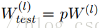
%dropout if(nn.dropoutFraction > 0) if(nn.testing) nn.a{i} = nn.a{i}.*(1 - nn.dropoutFraction); else nn.dropOutMask{i} = (rand(size(nn.a{i}))>nn.dropoutFraction); nn.a{i} = nn.a{i}.*nn.dropOutMask{i}; end end
即:是在激活值上乘以p?
答:因为有
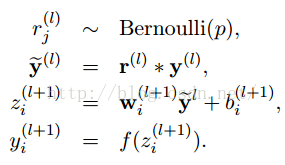
由上面公式可知,在w在乘以p等同于在z上乘以p。
4.Deep learning:四十一(Dropout简单理解)实验中下面代码中的d表示什么:
反向传播函数nnbp.m中的代码:
if(nn.dropoutFraction>0) d{i} = d{i} .* [ones(size(d{i},1),1) nn.dropOutMask{i}]; end
答:其中d表示的是残差或误差delta
5.dropout的优点与缺点:
答:
优点:在训练数据较少时,可用于防止过拟合
缺点:会使训练时间加长,但不影响测试时间
一些matlab函数
1.matlab中用rng替换rand('seed',sd)、randn('seed',sd)和rand('state',sd)的通俗解释
实验
我做的是实验是重复了Deep learning:四十一(Dropout简单理解)中的实验,结果是一样的,具体可看该篇博文
参考文献:
Dropout: A simple way to prevent neural networks from overfitting [paper][bibtex][code]
Imagenet classification with deep convolutional neural networks















 3522
3522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









