






写以下代码的目的是分析一天中各时段理想论坛中用户发帖回帖的活跃程度,获得结尾那张图表是核心。
以下代码两种爬虫协助,论坛爬虫先爬主贴,爬到主贴后启动帖子爬虫爬子贴,然后把每个子贴的发表时间等存入数据库。
再用一个程序对各个时段中发帖次数进行统计,然后用Excel生产图表。
获取数据的爬虫代码如下:
# 论坛爬虫,用于爬取主贴再爬子贴 from bs4 import BeautifulSoup import requests import threading import re import pymysql user_agent='Mozilla/4.0 (compatible;MEIE 5.5;windows NT)' headers={'User-Agent':user_agent} # 论坛爬虫类(多线程) class forumCrawler(threading.Thread): def __init__(self,name,url): threading.Thread.__init__(self,name=name) self.name=name self.url=url self.infos=[] def run(self): print("线程"+self.name+"开始爬取页面"+self.url); try: rsp=requests.get(self.url,headers=headers) soup= BeautifulSoup(rsp.text,'html.parser',from_encoding='utf-8') #print(rsp.text); # rsp.text是全文 # 找出span for spans in soup.find_all('span',class_="forumdisplay"): #找出link for link in spans.find_all('a'): if link and link.get("href"): #print(link.get("href")) #print(link.text+'\n') topicLink="http://www.55188.com/"+link.get("href") tc=topicCrawler(name=self.name+'_tc#'+link.get("href"),url=topicLink) tc.start() except Exception as e: print("线程"+self.name+"发生异常。")# 不管怎么出现的异常,就让它一直爬到底 print(e); # 帖子爬虫类(多线程) class topicCrawler(threading.Thread): def __init__(self,name,url): threading.Thread.__init__(self,name=name) self.name=name self.url=url self.infos=[] def run(self): while(self.url!="none"): print("线程"+self.name+"开始爬取页面"+self.url); try: rsp=requests.get(self.url,headers=headers) self.url="none"#用完之后置空,看下一页能否取到值 soup= BeautifulSoup(rsp.text,'html.parser',from_encoding='utf-8') #print(rsp.text); # rsp.text是全文 # 找出一页里每条发言 for divs in soup.find_all('div',class_="postinfo"): #print(divs.text) # divs.text包含作者和发帖时间的文字 # 用正则表达式将多个空白字符替换成一个空格 RE = re.compile(r'(\s+)') line=RE.sub(" ",divs.text) arr=line.split(' ') #print(len(arr)) arrLength=len(arr) if arrLength==7: info={'楼层':arr[1], '作者':arr[2].replace('只看:',''), '日期':arr[4], '时间':arr[5]} self.infos.append(info); elif arrLength==8: info={'楼层':arr[1], '作者':arr[2].replace('只看:',''), '日期':arr[5], '时间':arr[6]} self.infos.append(info); #找下一页所在地址 for pagesDiv in soup.find_all('div',class_="pages"): for strong in pagesDiv.find_all('strong'): print('当前为第'+strong.text+'页') # 找右边的兄弟节点 nextNode=strong.next_sibling if nextNode and nextNode.get("href"): # 右边的兄弟节点存在,且其有href属性 #print(nextNode.get("href")) self.url='http://www.55188.com/'+nextNode.get("href") if self.url!="none": print("有下一页,线程"+self.name+"前往下一页") continue else: print("无下一页,线程"+self.name+'爬取结束,开始打印...') for info in self.infos: print('\n') for key in info: print(key+":"+info[key]) print("线程"+self.name+'打印结束.') insertDB(self.name,self.infos) except Exception as e: print("线程"+self.name+"发生异常。重新爬行")# 不管怎么出现的异常,就让它一直爬到底 print(e); continue # 数据库插值 def insertDB(crawlName,infos): conn=pymysql.connect(host='127.0.0.1',user='root',passwd='12345678',db='test',charset='utf8') for info in infos: sql="insert into test.topic(floor,author,tdate,ttime,crawlername,addtime) values ('"+info['楼层']+"','"+info['作者']+"','"+info['日期']+"','"+info['时间']+"','"+crawlName+"',now() )" print(sql) conn.query(sql) conn.commit()# 写操作之后commit不可少 conn.close() # 入口函数 def main(): for i in range(1,10): url='http://www.55188.com/forum-8-'+str(i)+'.html' tc=forumCrawler(name='fc#'+str(i),url=url) tc.start() # 开始 main()
控制台输出太多就不贴了,把插入数据后的数据库展示一下,ttime字段就是想要获得的关键数据:
再做一个小程序对发帖时间进行统计,代码如下:
# 对发帖时间进行统计 import pymysql # 入口函数 def main(): dic={'00':0,'01':0,'02':0,'03':0,'04':0,'05':0,'06':0,'07':0,'08':0,'09':0,'10':0,'11':0,'12':0,'13':0,'14':0,'15':0,'16':0,'17':0,'18':0,'19':0,'20':0,'21':0,'22':0,'23':0} conn=pymysql.connect(host='127.0.0.1',user='root',passwd='12345678',db='test',charset='utf8') cs=conn.cursor() cs.execute("select * from topic") results = cs.fetchall() for row in results: ttime=row[4] hour=ttime.split(':')[0] dic[hour]=dic[hour]+1 conn.close() print(dic) # 开始 main()
输出字典如下:
C:\Users\horn1\Desktop\python\17>python sum.py {'00': 99, '01': 65, '02': 23, '03': 14, '04': 11, '05': 19, '06': 126, '07': 290, '08': 669, '09': 810, '10': 697, '11': 596, '12': 585, '13': 653, '14': 588, '15': 815, '16': 565, '17': 597, '18': 603, '19': 516, '20': 561, '21': 638, '22': 425, '23': 388}
用Excel来个图形化看看:
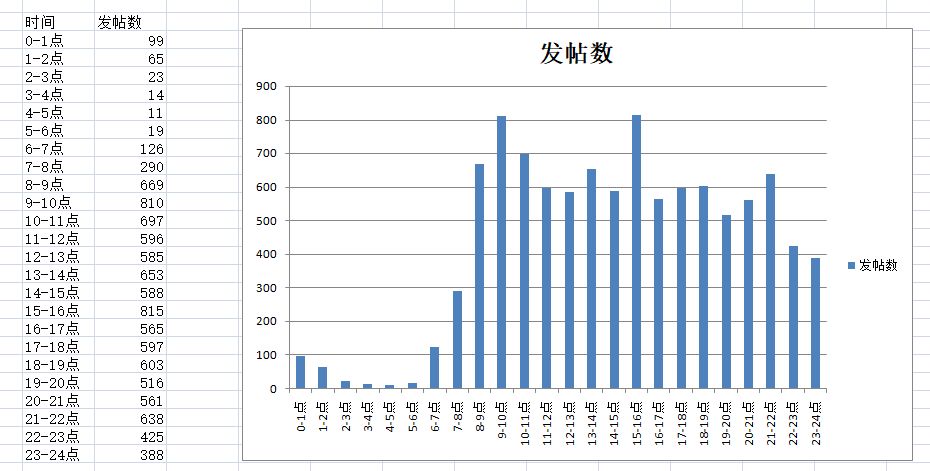
从上图可以得出以下结论:
1.早上0点-6点是交易者最闲的时候,他们大部分都在睡觉,3-5点睡得最熟。
2.发帖峰值一个是在9-10点,一个是15-16点。股市在9:30开盘,低开高开也出来了,行情也走了一段,大家开始热情高涨了发帖,之后就逐步回落,午休落入低谷,下午15点收盘后,大家又争相发表对这天行情的看法,但能一天走势能谈多少,于是一个小时就消停了。另外15-16点也是股评家发表股评的黄金时段。
3.入夜了,虽然早已收盘,大家依旧在浏览论坛,希望从帖子里发现什么或者讨论什么,直到23-24点还有不少人从事这项活动。
呵呵,我也玩票了一把数据分析。
2018年4月4日16点14分














 1287
1287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









