






一、JML语言的理论基础、应用工具链情况
1.JML语言的理论基础
- 面向对象分析和设计的原则之一就是应当尽可能地推迟过程设想,在实现方法之前确实能够做到,但是确定了架构后就会很容易地将思路转向过程性描述。JML语言的功能正是帮助人们尽可能的避免过程性思考,JML语言将延迟设想的面向对象原则扩展到了方法设计阶段,确定方法执行的内容、目的,而不必考虑方法的实现方式。JML说明性地描述类和方法的行为,能更加精确地描述代码所完成的任务能有效地发现和纠正错误、能减少随着应用程序的进展而引入错误的机会、能较早地发现客户没有正确使用类、能产生始终与应用程序代码保持同步的精确文档。
- JML以javadoc注释的方式来表示规格,每行都以@起头
- JML的表达式是对Java表达式的扩展,新增了一些操作符和原子表达式
1.1原子表达式:
- \result表达式:表示一个非 void 类型的方法执行所获得的结果,即方法执行后的返回值。
- \old( expr )表达式:用来表示一个表达式 expr 在相应方法执行前的取值。
- \not_assigned(x,y,...)表达式:用来表示括号中的变量是否在方法执行过程中被赋值。
1.2量化表达式
- \forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束
- \exists表达式:存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。
- \sum表达式:返回给定范围内的表达式的和。
1.2操作符:
- 推理操作符: b_expr1==>b_expr2 或者 b_expr2<==b_expr1 。对于表达式 b_expr1==>b_expr2 而言,当 b_expr1==false ,或者 b_expr1==true 且 b_expr2==true 时,整个表达式的值为 true
- 等价关系操作符: b_expr1<==>b_expr2 或者 b_expr1<=!=>b_expr2 ,其中b_expr1和b_expr2都是布尔表达 式,这两个表达式的意思是 b_expr1==b_expr2 或者 b_expr1!=b_expr2 。可以看出,这两个操作符和Java中的 == 和 != 具有相同的效果,按照JML语言定义, <==> 比 == 的优先级要低,同样 <=!=> 比 != 的优先级低。
- \nothing指示一个空集;\everything指示一个全集
1.4方法规格:
- 前置条件通过requires子句来表示
- 后置条件通过ensures子句来表示:
- public normal_behavior 表示接下来的部分对 cantBeSatisfied(int z) 方法的正常功能给出规格。
- 与正常功能相对应的是异常功能,即 public exceptional_behavior 下面所定义的规格
2.应用工具链情况
- jmlc可以检查JML形式规范是否正确
- JMLunit可以生成一个Java类文件测试的框架,并且使用Junit来测试具有规格描述的代码
- JMLdoc生成的HTML格式文档中包含JML规范
二、部署SMT Server

三、部署JMLUnitNG
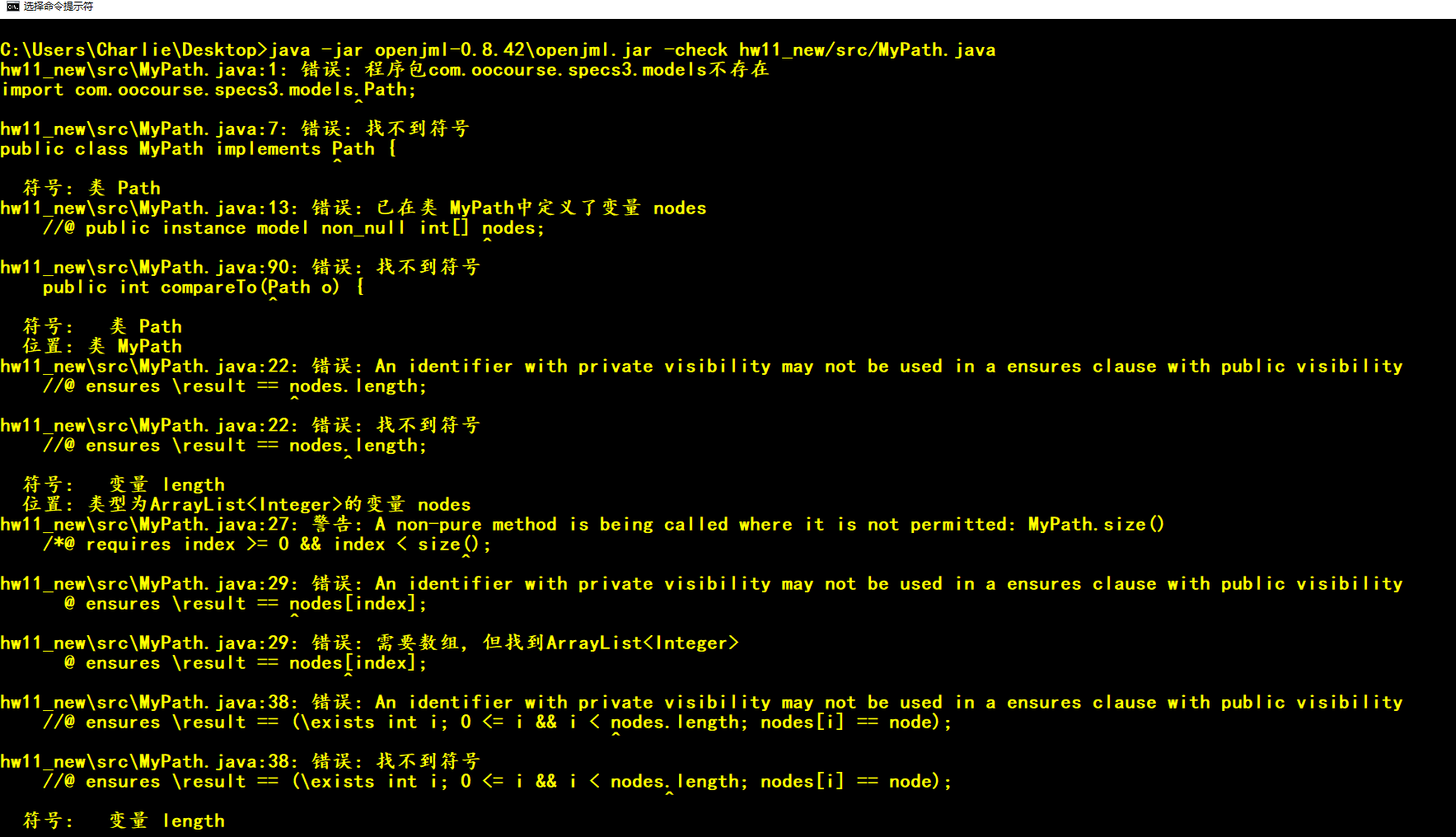
依次执行以下命令,可以得到如图所示的结果:
- java -jar jmlunitng.jar -d "test" -sp src src\Demo.java
- "C:\Program Files\Java\jdk1.8.0_201\bin\javac.exe" -cp "jmlunitng.jar" -sourcepath src -d test\out test\*.java
- java -jar openjml.jar -rac -specspath src src\Demo.java
- cd test\out
- java -cp "../../jmlunitng.jar;./" Demo_JML_Test

可以从图中看到,主要是对极端情况进行了测试,因为是int类型的变量,所以对int最大值+2147483648以及最小值-2147483648进行了相应测试。
四、设计策略及架构
1.第九次作业
- 本次作业的目标是:最终需要实现一个路径管理系统,并且可以通过各类输入指令来进行数据的增删查改等交互。由于本单元主要是练习java中针对规格写代码,因此这一次作业的任务量不大,只要正确理解官方提供的规格,并且正确实现Path、PathCountainer类中相应的方法就可以了。
- 比较需要注意的是应当正确选择恰当的数据结构,使得能够方便迅速地增删路径,因此我在着手写代码前,着重思考了数据结构的选取,尤其是在指导书中提到"程序的最大运行cpu时间为10s,虽然保证强测数据有梯度,但是还是请注意时间复杂度的控制。任务中要求计算所有路径中不同结点的总数,如果在每次查询的时候遍历一遍所有路径来计算不同结点的个数的话将非常不划算,使得性能大大降低。实际上,导致不同结点的总数的变化的原因实质上是增删路径,那么只需要在每次增删路径的时候计算一下不同结点的总数就可以了,或者是用HashMap来将每个结点存储,其中Key值为结点的id,这样每次查询不同结点的总数时就可以通过调用HashMaop.size()来直接得到不同结点的数目了,我选择的方法是后者。
2.第十次作业
- 本次作业的目标是:实现一个无向图系统,可以像第九次作业一样通过各类输入指令来进行基于路径的增删查改管理,并且将内部的Path构建为无向图结构,进行基于无向图的一些查询操作。这一次的任务是建立在第九次作业的基础上面的,由于相关方法很多在上一次已经实现了,所以我是将第九次完成的方法直接复制粘贴在本次作业中,并且在这个基础上进行拓展。
- 这一次作业中新增的方法有"判断两个结点是否连通"、"查询两个结点之间的最短路径",这两个新增的方法像第九次作业一样,如果没有处理好将大大降低程序的性能,所以不能临时现查,同样需要使用一个数据结构将需要查询的结果先存下来。如果每次查询都是现场去查的话,将会大大增加时间复杂度,甚至可能会出现CPU时间超时的情况,因此我的想法是每当改变了一次图的结构,就应当将任意两点之间的距离先计算出来,并且存储下来,这样的话,下次需要查询的时候就可以快速给出答案,而不是现场再查一遍。有了这个想法后我便着手去实现各个方法,并且写了一些测试样例,但是此时我发现代码运算时间特别长,后来发现用Dijkstra算法计算两点间的路径需要用到较复杂的数据结构,如HashSet等类型,这样会导致程序运行时间很长。随后我便尝试用Floyd算法进行试验,发现Floyd算法跑相同测试集的时间非常快,思考了一下其中的原因,发现主要还是数据结构的问题。虽然Dijkstra算法理论上的时间复杂度小于Floyd,但是这是在相同数据结构的基础上,而在实践的过程中,不应当只关注理论值,而应当考虑到数据结构的差异带来的性能的变化!Dijkstra使用了HashSet导致性能大大下降,Floyd使用的是二维数组进行存储,通过数组的坐标能够快速访问到其中的元素,因此在这次任务中,我选择二维数组来存储两点间的最短距离并且使用Floyd算法来计算。
- 为了使用二维数组来计算任意两点之间的距离,考虑到结点的id是任意的,自然而然的就想到了需要建立一个映射来将每个节点与与数组下标进行对应,因此我选择使用HashMap来建立结点到下标的映射,key值为结点id,value为对应的下标。由于删除路径可能导致已有结点被彻底删除,因此还需要一个数据结构来存储未被使用的数组下标,这样才能在不断进行的增删路径中做到对数组下标是循环利用。
3.第十一次作业
- 本次作业的目标是构建一个地铁系统,这次作业的任务量相对于上一次似乎增大了许多,但是仔细分析后发现,要求的方法中算不满意度、票价、最少换乘都是同一类问题,即计算无向有权图中两节点之间的距离,并且需要考虑更换path的代价。
- 经过讨论区大佬的提示,可以抛开变换路径的变化而需要付出代价(票价+2,不满意度+32)这一表层变化,而关注于其本质,那就是每当更换一次路径总代价增加2或32,。那么就可以应用Floyd算法来计算任意两点之间的票价、不满意度了。我也尝试过使用Dijsktra算法,每当需要计算两点之间的路径时我就调用Dijkstra算法来计算,并且记录下来这条最短路径中每个点到重点的距离,这样就会不断加速之后的查询过程。但是经过测试发现,线下Dijkstra算法相对于Floyd算法在相同测试集上的运行速度较慢,所有我最终选择的仍然是Floyd算法。
- 为了计算图中连通块的数目,我的想法是只有改变了图的结构连通块的数目才会发生改变,因此我在每次添加路径、删除路径的时候计算连通块的数目,这样就可以做到提前把看结果计算好,避免了多次查询导致的重复计算。我选择建立一个50*50的数组用来保存每两个路径有没有公共结点,若有公共结点则表示它们属于同一个连通块,而对数组的更新同样是在增删路径的时候完成的。为此必须建立一个数据结构用来保存每个结点所在的path,否则无法判断两个path之间有没有公共结点。因此我建立了一个类Node来保存每个结点的信息,其中保存了这个结点所在的路径的id。在每个Node内保存了其所在path的信息后,还可以利用这个计算两点之间的最少换乘数目,因为对已经利用数组保存下来了任意两个path是否相连,用Floyd算法可以计算出任意两个路径之间的距离,这个距离就是两条路径上两节点的最少换乘数目。所以在每次查询两结点之间的最少换乘数目时,可以通过Node所存结点各自所在的路径来判断两结点之间的最少换乘数目。
4.三次作业的类图
第九次作业类图:

第十次作业类图:
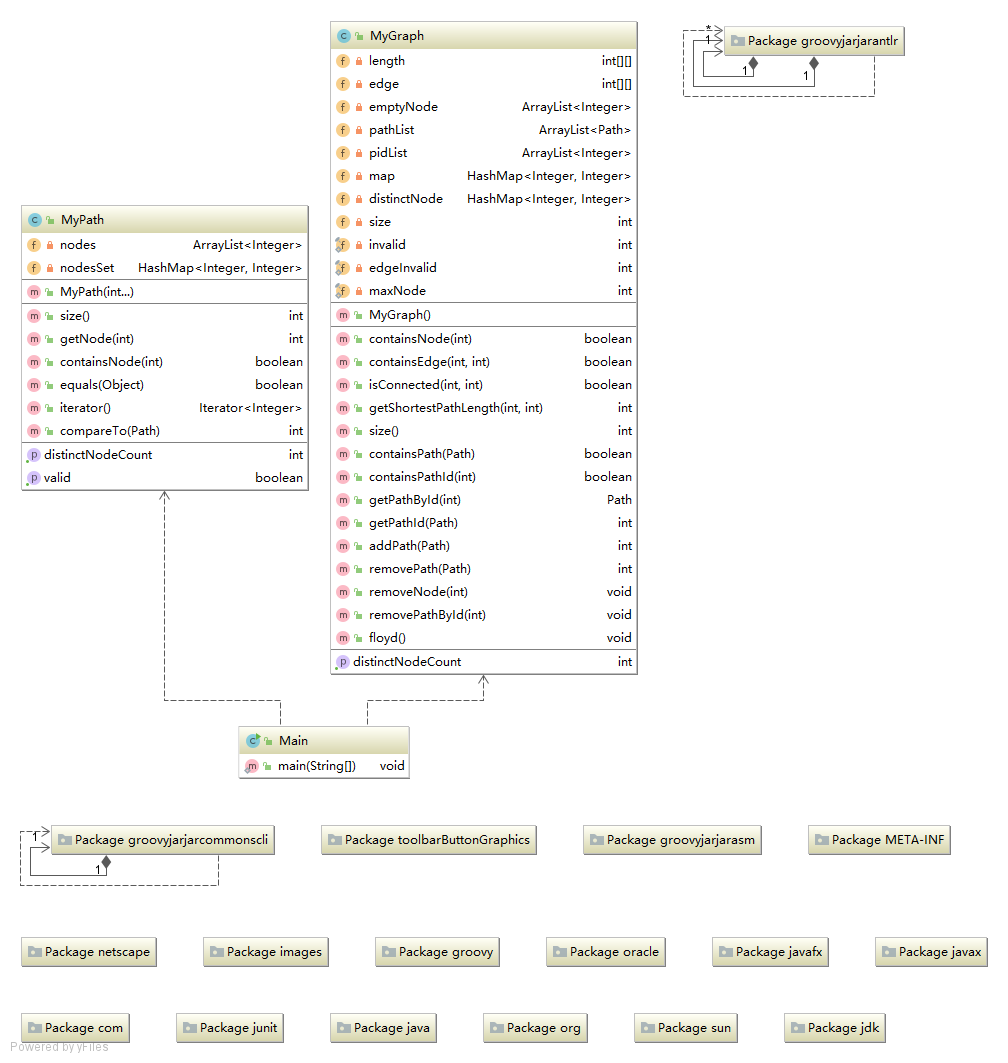
第十一次作业类图:

五、迭代中对架构的重构
- 我的架构是完全沿用上一次作业的架构,并且在此基础上进行拓展,没有进行对架构的重构。在这三次作业中,通过任务中需要完成的指令就可以看出,每一次作业都是在上一次的作业基础上进行拓展的,我也在第一次写作业的时候就以及考虑到了架构重构的问题,因此第一次、第二次作业都是尽量选择合适的数据结构来进行存储相关信息,这样就可以在后面作业中避免大量修改代码。事实上,我在第二次作业中就是完全在第一次作业的基础上进行拓展,利用第一次作业存储的信息并且添加一个新的数据结构来保存结点之间的最短路径,第三次作业也在是第二次作业的基础上进行拓展,增加了二维数据来计算最小不满意度、最少票价等,没有对架构进行重构。
六、分析Bug和修复情况
- 路径id序号错误:在第一次作业中,我没有意识到路径id是不会减少的,我以为删除一条路径并且再次新增一条路径时,新路径的id就是被删除的路径id。这个bug在初测提交一次后就发现并且根据结果反馈信息找到了,于是我添加了一个private 类型变量来记录path的id,修复了bug。
- 删除路径时会把公共结点直接删除:同样是在第一次作业中,由于我没有记录相同结点在所有路径出现的次数,因此我在删除一条路径时会把其和另外一条路径的公共结点直接删除,导致了非常大的bug,经过自己简单编写的测试就发现了这个错误,并且将存储结点id的数据结构由Arraylist改变为HashMap,key值为结点的id,value为结点在所有现存路径出现的次数,只有当次数为1并且删除路径中出现了该结点时才将这个结点删除,否则只是将value-1,从而修复了这个bug。
- 计算图中连通块的数目:在第三次作业中,一开始计算连通块数目采用的策略是当新增路径中有已经存在与图中的结点时就说明不会增加连通块的数目,因为这条新增的路径与其他路径至少有一个公共点。这个思路是对的,但是经过测试发现:两条已存在的路径是不相连的,新加入的路径将它们连在了一起,此时连通块的数目应当减少一,但是这个情况很难判断出来,除非进行对图所有结点的遍历,这将导致性能下降。因此我选择改变思路,通过二维数组保存任意两条路径之间是否相连,并且用Floyd算法计算任意两条路径的最短距离,这个距离也就相当于两条路径上结点的最少换乘数目,并且当两结点的距离为无穷大时就代表它们是不相连的,以此不但可以计算出连通块的数目,还可以计算任意两点之间的最少换乘数目,一举两得。
七、心得体会
- 在这一单元的作业中,实践了利用Junit来编写测试,从而可以对代码进行测试,大大简化测试的步骤;还学习了规格的书写以及针对规格填写相应代码,在刚开始学习规格的时候是非常不适应的,以前一直是针对自然语言来完成代码,现在需要现完全理解规格的含义然后再写代码,由于对一些多要求的功能用规格描述的十分复杂,导致了规格理解不准确甚至无法理解的结果,因此有一些不习惯,但是随着训练以及查阅资料,慢慢的能够较正确的理解规格并且完成代码了。学习规格对我们的写代码的意义重大,通过规格不仅能够准确方法的功能目的,还能让别人快速理解代码的意图从而极大的拓展了代码的可读性。
- 通过完成这一单元的作业,加深了我对面向对象的理解,尤其是对于规格的运用,避免了我在写方法时不自觉地进入过程性语言思考的范畴,而是转变思路,将方法也归入到面向对象的领域。规格是逻辑严格的,避免了使用自然语言带来的漏洞,提高了代码的可维护性,尤其是有利于大型工程中代码的快速理解与阅读。















 166
166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









