






SoftMatch则着重解决伪标签 「数量-质量」 间的trade-off。该工作已被ICLR 2023录用(分数8666),在图像、文本、长尾分类上均取得了最好的效果。
半监督学习的主要任务是如何通过模型在未标签的数据上的预测情况,来得到可靠的伪标签,从而将大量无标签数据引入训练。
在以往的半监督学习的工作中,「置信度阈值」(confidence thresholding)是一种比较主流的利用伪标签的方式。比如在FixMatch中,置信度高于阈值(0.9)的数据的伪标签会直接引入到训练中。通过设定较高的阈值, 伪标签的质量(即正确性)可以得到保证。但是,一系列动态阈值的工作如FlexMatch(NeurIPS'21)和FreeMatch(ICLR'23)指出,过高的阈值丢弃了很多不确定的伪标签,导致类别之间学习 「不平衡」 ,并且伪标签 「利用率低」 。动态阈值通过前期降低(不同类别/不同数据)的阈值,来引入更多的伪标签在前期参与训练,但是前期的低阈值会不可避免的引入质量低的伪标签。
本文介绍的SoftMatch则着重解决伪标签 「数量-质量」 间的trade-off。该工作已被ICLR 2023录用(分数8666),在图像、文本、长尾分类上均取得了最好的效果。文章共同第一作者为卡耐基梅隆大学的陈皓和陶然。二人也是半监督算法库USB(NeurIPS'22)的核心成员。合作者来自马克斯-普朗克研究所、微软亚洲研究院,以及MBZUAI。
- 论文标题: SoftMatch: Addressing the Quantity-Quality Trade-off in Semi-supervised Learning
- 论文链接:
https://arxiv.org/abs/2301.10921 - 代码已开源在USB中:
https://github.com/microsoft/Semi-supervised-learning - OpenReview链接:
https://openreview.net/forum?id=ymt1zQXBDiF
理解数量和质量的trade-off
为了更好地理解这一trade-off, 我们通过一个统一的weighting的视角来对之前半监督方法的质量和数量trade-off进行总结和分析。
我们先来回顾一下半监督学习的主要优化损失函数。


对Trade-off的初步实验分析
为了方便理解,我们在双月数据集上做了实际的分析:
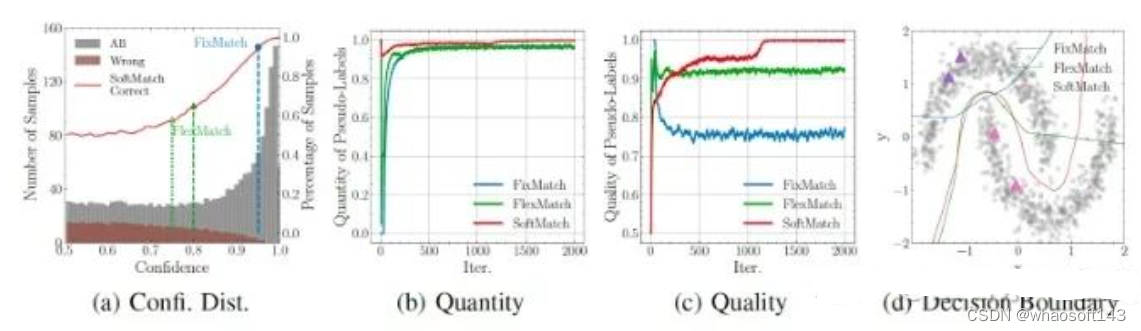
其中(a)可以理解为在训练某个时刻所有无标签数据的置信度分布(灰色直方图)和其中伪标签是错误的数据的置信度分布(褐色直方图)。红色的线为softmatch提出的weighting function对这些数据的利用率,其中我们用蓝色的点及以上的部分表示FixMatch的利用率, 绿色的点及以上的部分来表示FlexMatch的利用率。
可以看出,正如前面的分析,过高的阈值(FixMatch)会导致伪标签整理利用率低(低数量,71%的无标签数据没有利用到),即使所利用的伪标签大部分是正确的(高质量),仍然无法学习到好的分类器。对于FlexMatch来说,即使训练初期使用了较低的阈值以提高利用率(相比于FixMatch为高数量),但是伪标签中引入了过多的错误标签(约16%所使用的标签是错误的).(我们认为这也是FlexMatch在svhn上不work的主要原因). 相比于之前的方法,SoftMatch在保证高利用率的同时,通过对可能错误的标签分配较低的权重,以同时实现高质量。
SoftMatch
如何在数量和质量上实现更优的表现?

在训练中,我们实际使用这两个参数的EMA, 以提高预测稳定性。
至于为什么选择高斯函数而不是别的.....主要是为了简单。其他的函数当然也可以(参考实验部分), 比如拉普拉斯,或者像ConMatch一样使用一个小网络直接预测权重。重要的是weighting function是trade-off的关键,通过使用非常简单的weighting函数,我们就可以得到很好的结果。
如何平衡地使用不同类别的未标签的数据?
在SoftMatch中,由于weighting的分配是由置信度的分布决定的,我们通过提高不用类别的marginal probability来实现尽可能给不同类别的数据分配同等水平的weighting。我们提出了 「Uniform Alignment」:
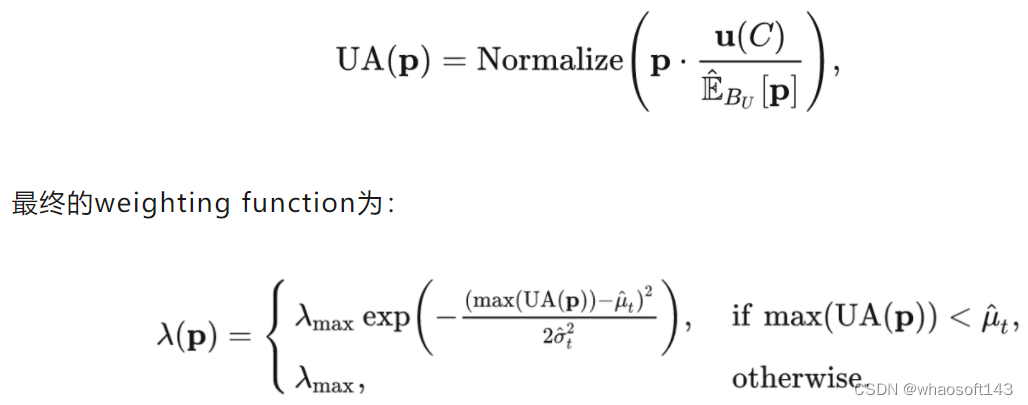
Uniform Alignment其实和Distribution Alignment基本一致,区别为我们只是用align过后的预测计算权重,而不用align过后的预测当作伪标签。这样避免了distribution alignment可能引入的错误伪标签,同时提高了每个类别的平均利用率。
Uniform Alignment另一个层面也可以看作对于不同的class动态的调整高斯函数的均值,与每个类别使用动态阈值的想法类似.
实验
主要结果
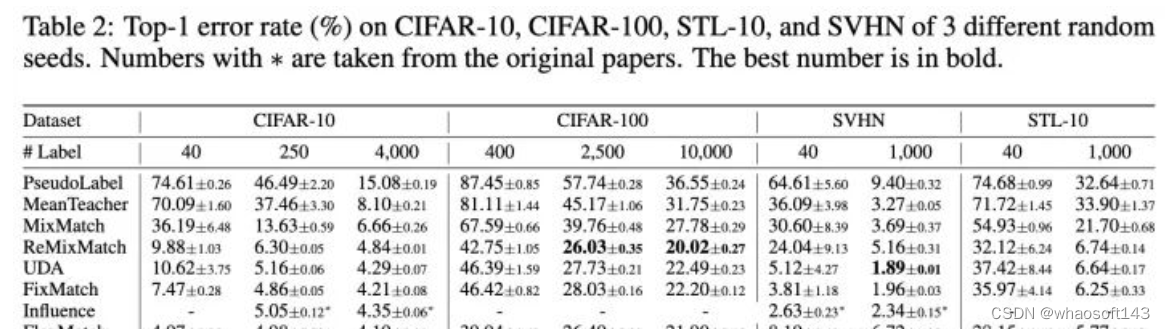
我们在图片、文本和长尾分类上比较了SoftMatch和之前的方法。
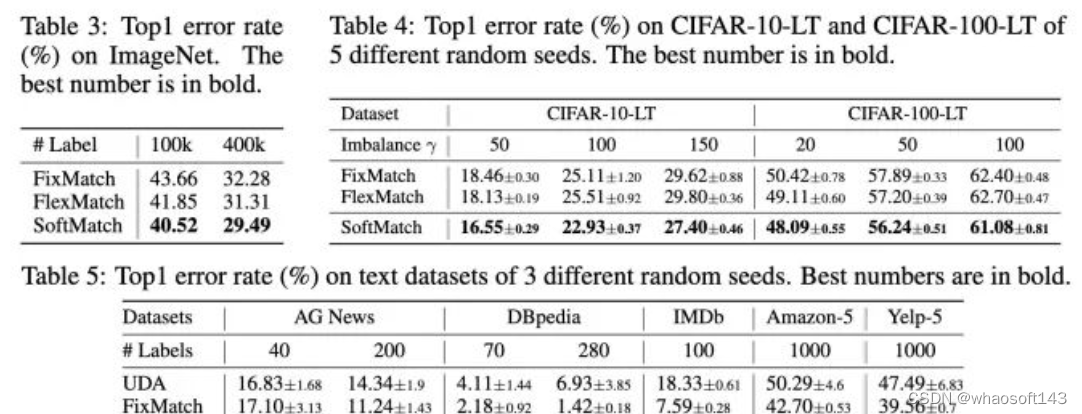
ImageNet和文本、长尾分类结果
可以看出SoftMatch在不同的实验设置上均实现了SOTA-level的结果。相比于FixMatch,FlexMatch,「基本没有计算负担的增加」。
分析实验
这里我们主要分析其他的weighting function是不是也可行的消融实验,更多关于超参数和设计的实验感兴趣的读者可以自行查看.

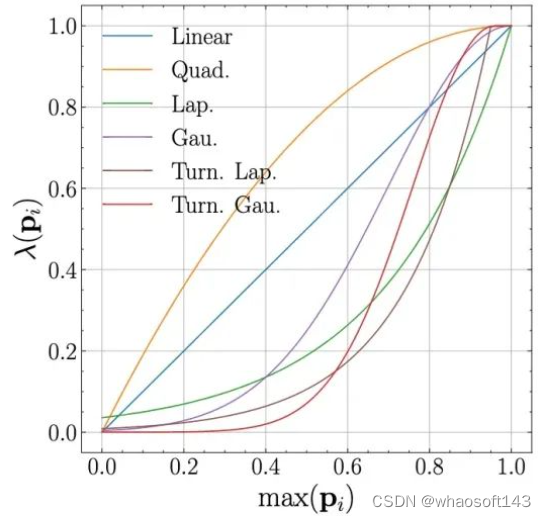
我们选了几种不同weighting function的实现,以及使用他们在cifar10和svhn上的结果。可以看出在strong-weak augmentation的框架下,使用linear weighting或者简单的gaussian, laplacian weighting也可以得到一些较好的结果。使用动态估计的高斯参数和UA可以进一步提升在cifar10 40上的结果.
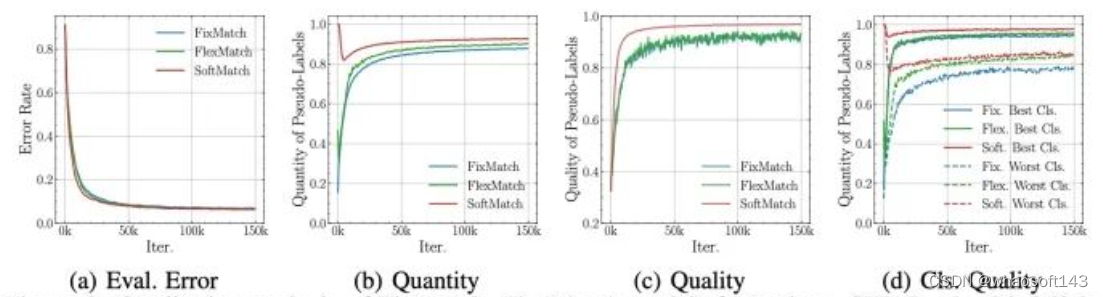
在cifar10上, SoftMatch同样展示出更优的伪标签质量和数量。
总结
我们提出SoftMatch,着重通过weighting function来解决伪标签质量和数量之间的trade-off。我们证明,通过简单的高斯函数,可以在各种测试中达到较好的效果。















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









