







01 HBase简介
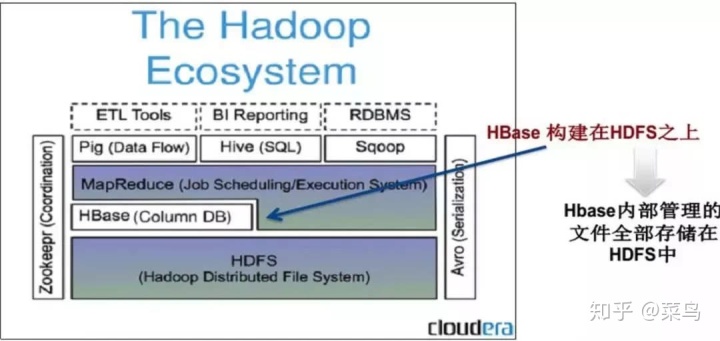
HBase是一个构建在HDFS之上,用于海量数据存储分布式列存储系统。
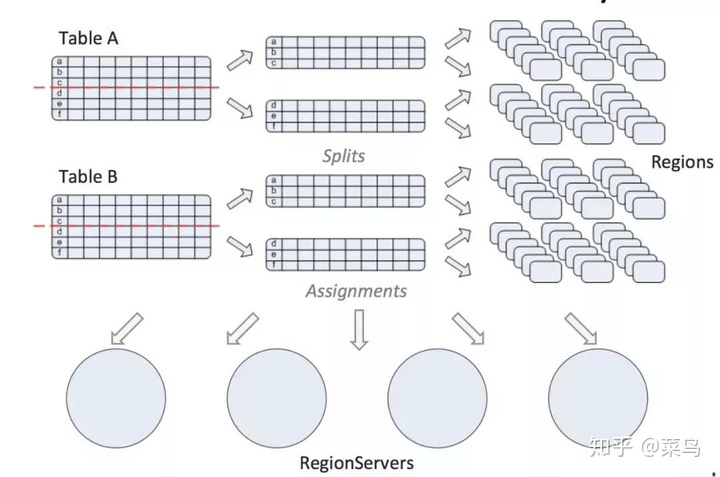
参见下图,由于在HBase中:
表的每行都是按照RowKey的字典序排序存储
表的数据是按照RowKey区间进行分割存储成多个region
所以HBase主要适用下面这两种常见场景:
适用于基于rowkey的单行数据快速随机读写
适合基于rowkey前缀的范围扫描
02 为什么需要HBse二级索引
HBase里面只有rowkey作为一级索引, 如果要对库里的非rowkey字段进行数据检索和查询, 往往要通过MapReduce/Spark等分布式计算框架进行,硬件资源消耗和时间延迟都会比较高。
为了HBase的数据查询更高效、适应更多的场景, 诸如使用非rowkey字段检索也能做到秒级响应,或者支持各个字段进行模糊查询和多字段组合查询等, 因此需要在HBase上面构建二级索引, 以满足现实中更复杂多样的业务需求。
03 HBse二级索引方案
基于Coprocessor方案
1、官方特性
其实从0.94版本开始,HBase官方文档已经提出了hbase上面实现二级索引的一种路径:
基于Coprocessor(0.92版本开始引入,达到支持类似传统RDBMS的触发器的行为)
开发自定义数据处理逻辑,采用数据“双写”(dual-write)策略,在有数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5065
5065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









