







“Explaining Knowledge Distillation by Quantifying the Knowledge” in CVPR2020
论文链接:https://arxiv.org/abs/2003.03622
本研究旨在从一个新的角度解释知识蒸馏算法,即通过量化神经网络所建模的“知识量”分析神经网络的性能。目前,神经网络可解释性的研究主要分为两个流派:一是从语义层面解释神经网络所建模的特征,譬如可视化中层特征,或是提取对结果影响显著的关键性像素;二是从数学层面分析神经网络的表达能力,例如评测神经网络的泛化能力或鲁棒性。但是学界尚未有理论工具打通神经网络语义解释与表达能力分析的连通壁垒,实现对二者的统一建模。
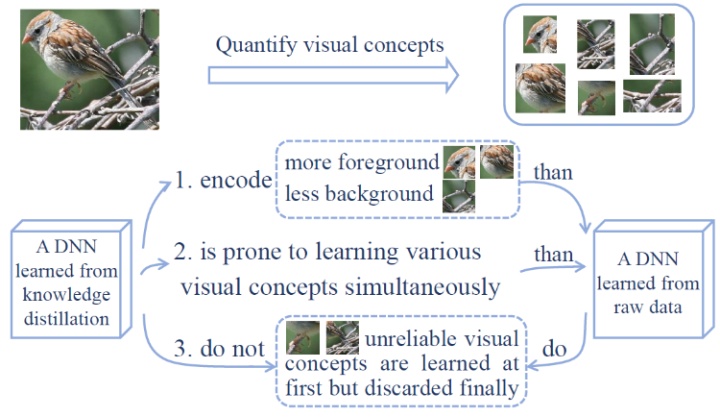
本研究核心在于通过定义并量化神经网络中层特征的“知识量”,从神经网络表达能力的角度来解释知识蒸馏算法的成功机理。我们提出并验证以下三个Hypotheses:
- Hypothesis 1:比起直接从数据学习,蒸馏算法往往使得深度神经网络(DNN)学到更多的知识;
- Hypothesis 2:比起直接从数据学习,蒸馏算法往往使得DNN更倾向于同时学到不同知识;
- Hypothesis 3:比起直接从数据学习,蒸馏算法往往使得DNN的优化方向更为稳定。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









