










【技术博客】通过量化知识来解释知识蒸馏
知识蒸馏介绍
知识蒸馏(Knowledge Distillation)早期是在2006年由 Bulica 提出的,在2014年 Hinton 对知识蒸馏做了归纳和发展。知识蒸馏主要思想是训练一个小的网络模型来模仿一个预先训练好的大型网络或者集成的网络。Hinton 在2015年发表的论文中提出了‘softmax temperature’的概念,对 softmax 函数做了改进:
P i = e z i T ∑ j e z j T P_i = \frac{e^\frac{z_i}{T}}{\sum_je\frac{z_j}{T}} Pi=∑jeTzjeTzi
当 T 等于1时就是标准的 softmax 参数,前者比后者具有这样一个优势:经过训练后的原模型,其 softmax 分布包含有一定的知识,真实标签只能告诉我们,某个图像样本是一辆宝马,不是一辆垃圾车,也不是一颗萝卜;而带有温度参数T的softmax函数可能会告诉我们,它最可能是一辆宝马,不大可能是一辆垃圾车,但不可能是一颗萝卜。
Hinton 等人做了三组实验,大体上验证了知识蒸馏方法的有效性。 Hinton 等人促进了知识蒸馏的发展并从实验的角度来验证了知识蒸馏的有效性,而本篇介绍的论文则提出了一些量化知识的概念来解释知识蒸馏的成功机理。
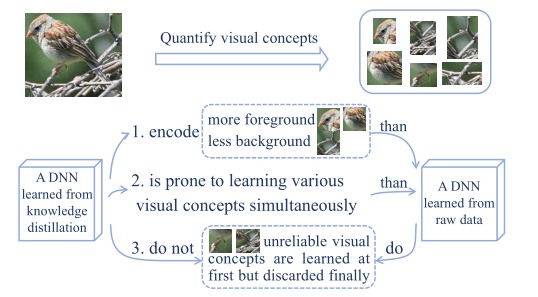
该论文为了解释知识蒸馏的成功机理,提出了三个假设,并根据假设基于可视化的量化标准,提出了三种类型的度量标准来验证了关于知识蒸馏的三个假设,为解释知识蒸馏提供了依据。
假设提出
假设1:知识蒸馏使 DNN 可以学习更多的视觉概念。我们将与任务相关的视觉概念和其他概念区分开来,如下图所示,前景上的视觉概念通常被认为是与任务相关的,而背景上的视觉概念则被认为是与任务无关的。
假设2:知识蒸馏确保了 DNN 易于同时学习各种视觉概念。相比之下基础网络倾向于顺序学习视觉概念,即在不同的 epoch 学习不同的概念。
假设3:知识蒸馏的模型优化方向更加稳定。DNN 在对原始数据进行学习时,通常会在早期尝试对各种视觉概念进行建模,然后在后期抛弃某些视觉概念;而在知识蒸馏的过程中,教师网络直接引导学生网络瞄准特定视觉概念,没有明显的迂回。
在该文章的研究中,视觉概念被定义为一个图像区域,如物体的一个部分:翅膀、头、爪子等。基础网络被定义为从原始数据中学习的网络。
算法
在该节,我们给定一个提前训练好的 DNN 网络(教师网络)和一个经蒸馏形成的另一个 DNN 网络(学生网络),为了解释知识蒸馏,我们将学生网络与从原始数据中学习生成 DNN 网络相比较,另外我们将任务限制为分类任务来简化下面的理论分析。
为了验证假设1,这里定义几个度量的标准:
N
c
o
n
c
e
p
t
b
g
(
x
)
=
∑
i
∈
b
g
(
H
ˉ
−
H
i
>
b
)
N_{concept}^{bg}(x) = \sum_{i\in{bg}}(\bar{H} - H_i>b)
Nconceptbg(x)=∑i∈bg(Hˉ−Hi>b)
N
c
o
n
c
e
p
t
f
g
(
x
)
=
∑
i
∈
f
g
(
H
ˉ
−
H
i
>
b
)
N_{concept}^{fg}(x) = \sum_{i\in{fg}}(\bar{H} - H_i>b)
Nconceptfg(x)=∑i∈fg(Hˉ−Hi>b)
λ
=
E
x
∈
I
[
N
c
o
n
c
e
p
t
f
g
(
x
)
N
c
o
n
c
e
p
t
f
g
(
x
)
+
N
c
o
n
c
e
p
t
b
g
(
x
)
]
\lambda = E_{x\in I}[\frac{N_{concept}^{fg}(x)}{N_{concept}^{fg}(x)+N_{concept}^{bg}(x)}]
λ=Ex∈I[Nconceptfg(x)+Nconceptbg(x)Nconceptfg(x)]
这里 N c o n c e p t b g ( x ) N_{concept}^{bg}(x) Nconceptbg(x)和 N c o n c e p t f g ( x ) N_{concept}^{fg}(x) Nconceptfg(x)分别代表了背景上的视觉概念的数量和前景上视觉概念的数量,这里对于视觉概念的判别方法来源于信息论, H ˉ \bar{H} Hˉ表示背景的平均熵,我们通常将背景上的像素认作与任务无关的视觉概念。因此我们可以将 H ˉ \bar{H} Hˉ作为整张图像熵的基线。熵值显著低于 H ˉ \bar{H} Hˉ的图像区域可以视为有效的视觉概念,b为一个正标量。当括号内条件满足时,返回1,否则返回0.
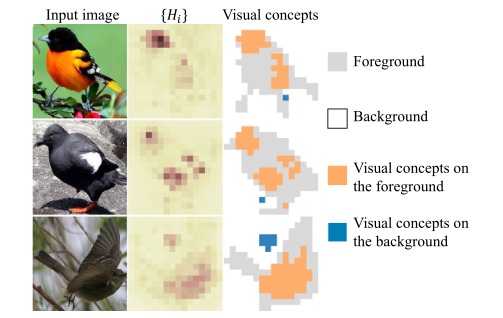
(上图为视觉概念(visual concepts)的可视化表现,第二列表示了不同图像每个像素的熵值,在第三列中,具有低熵值的区域被视为视觉概念)
从统计学来看,前景上的视觉概念通常与任务相关,而背景上的视觉概念主要与任务无关,这样当 DNN 具有更强的鉴别能力时, λ \lambda λ参数会更高。
为了验证假设2,我们提出了两个度量标准。给定一组训练图像
I
I
I,我们将每个epoch后得到的前景中视觉概念的数量写为
N
1
f
g
(
I
)
,
N
2
f
g
(
I
)
,
.
.
.
.
.
.
,
N
M
f
g
(
I
)
。
N_1^{fg}(I),N_2^{fg}(I),......,N_M^{fg}(I)。
N1fg(I),N2fg(I),......,NMfg(I)。我们定义
m
^
=
a
r
g
m
a
x
k
N
k
f
g
(
I
)
\hat{m} = arg max_k N_k^{fg}(I)
m^=argmaxkNkfg(I)表示具有最多视觉概念的epoch,“weight distance”
∑
k
=
1
m
^
∥
ω
k
−
ω
k
−
1
∥
∥
ω
0
∥
\sum_{k=1}^{\hat{m}}\frac{\left \| \omega_k-\omega_{k-1} \right \|}{\left \| \omega_0 \right \|}
∑k=1m^∥ω0∥∥ωk−ωk−1∥来测量在视觉概念最多时的学习过程。没有使用 epoch number 而是使用 weight distance 的原因是后者更好的量化了每个epoch后参数更新的总路径,因此我们使用平均值
D
m
e
a
n
D_{mean}
Dmean和
标准差
D
s
t
d
D_{std}
Dstd来量化一个 DNN 是否同时学习视觉概念:
D m e a n = E i ∈ I [ ∑ k = 1 m ^ ∥ ω k − ω k − 1 ∥ ∥ ω 0 ∥ ] D_{mean} = E_{i \in I}[\sum_{k=1}^{\hat{m}}\frac{\left \| \omega_k-\omega_{k-1} \right \|}{\left \| \omega_0 \right \|}] Dmean=Ei∈I[∑k=1m^∥ω0∥∥ωk−ωk−1∥]
D s t d = V a r i ∈ I [ ∑ k = 1 m ^ ∥ ω k − ω k − 1 ∥ ∥ ω 0 ∥ ] D_{std} = Var_{i \in I}[\sum_{k=1}^{\hat{m}}\frac{\left \| \omega_k-\omega_{k-1} \right \|}{\left \| \omega_0 \right \|}] Dstd=Vari∈I[∑k=1m^∥ω0∥∥ωk−ωk−1∥]
平均值 D m e a n D_{mean} Dmean和标准差 D s t d D_{std} Dstd分别表示 DNN 是否能快速学习视觉概念和是否同时学习各种视觉概念,因此 D m e a n D_{mean} Dmean和 D s t d D_{std} Dstd的数值越小,代表 DNN 能够快速同时地学习各种视觉概念。
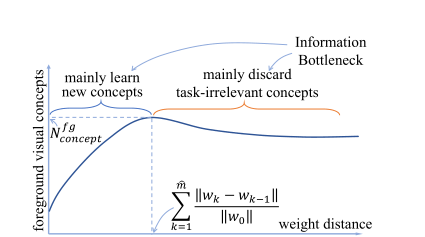
(DNN 倾向于在前期学习各种视觉概念,之后主要丢弃与任务无关的概念)
为了验证假设3,即需要量化 DNN 优化方向的稳定性,这里提出了一种新的度量方法。我们将在每一个epoch中得到的视觉概念的集合定义为 S 1 ( I ) , S 2 ( I ) , . . . . . . , S M ( I ) S_1(I),S_2(I),......,S_M(I) S1(I),S2(I),......,SM(I)。由此我们可以将优化方向的稳定性定义为:
ρ = ∥ S M ( I ) ∥ ∥ ⋃ j = 1 M S M ( I ) ∥ \rho=\frac{\left \| S_M(I) \right \|}{\left \| \bigcup_{j=1}^{M} S_M(I) \right \|} ρ=∥⋃j=1MSM(I)∥∥SM(I)∥
该式中分子代表的是最终选择的视觉概念,如下图黑色方框中所示;而分母代表的是每一个epoch中选择的视觉概念的并集,如下图绿色方框中所示。
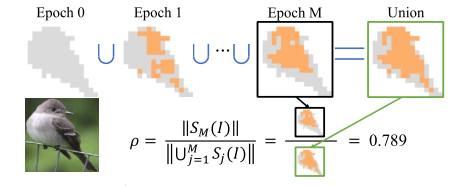
大的 ρ \rho ρ值代表了每一个epoch中选择的视觉概念都在最终结果中,说明优化后的 DNN 走的弯路少,即代表了优化的稳定性好。
实验验证
利用上述提到的 N c o n c e p t b g , N c o n c e p t f g , λ , D m e a n , D s t d , ρ N_{concept}^{bg},N_{concept}^{fg},\lambda,D_{mean},D_{std},\rho Nconceptbg,Nconceptfg,λ,Dmean,Dstd,ρ等参数,作者等人基于ILSVRC-2013 DET数据集、CUB200-2011数据集、Pascal VOC 2012数据集训练了这些 DNN 网络,为了综合比较,使用了 AlexNet、VGG-11、VGG-16、VGG-19、ResNet-50、ResNet-101、ResNet-152 进行实验。将每个 DNN 作为教师网络,我们将知识从教师网络提取到学生网络,学生网络与教师网络具有相同的架构,以便进行公平的比较。同时,要求基础网络具有与教师网络相同的体系结构。

(VGG-11 中 FC1层中视觉概念的可视化,可以看出学生网络相比于基础网络有更大的 N c o n c e p t f g N_{concept}^{fg} Nconceptfg和更小的 N c o n c e p t b g N_{concept}^{bg} Nconceptbg
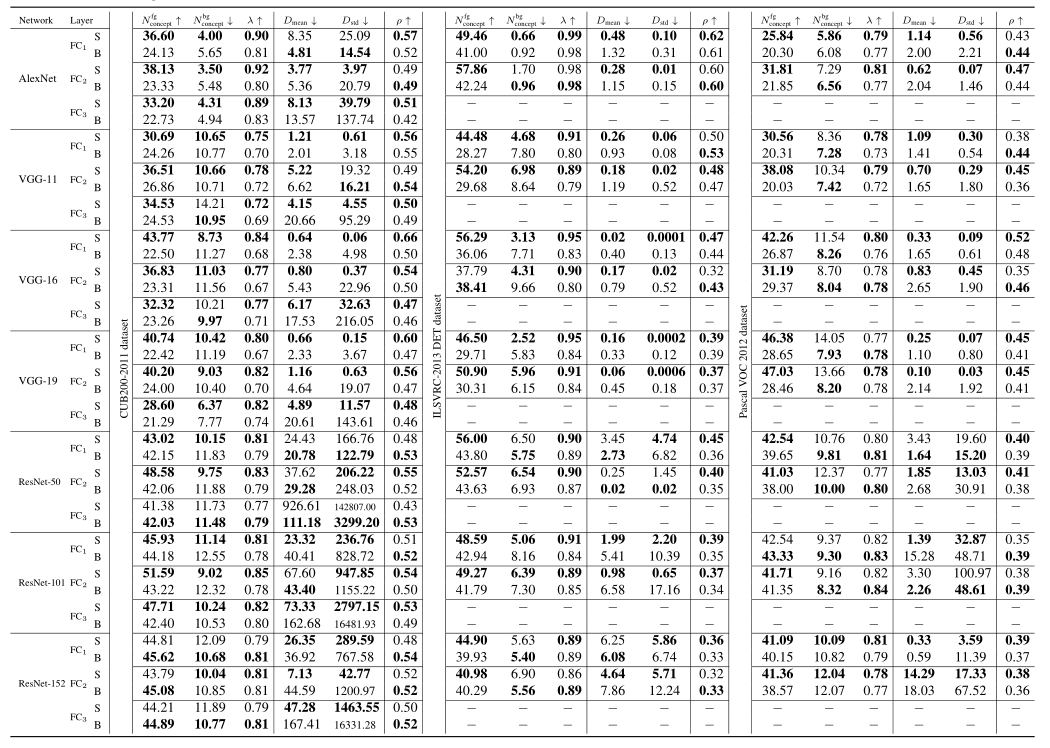
学生网络(S)与基础网络(B)相比, ↑ \uparrow ↑ ↓ \downarrow ↓分别表示值越大、越小越好。根据表中数据,学生网络相比基础网络具有更大的 N c o n c e p t f g , λ , ρ N_{concept}^{fg},\lambda,\rho Nconceptfg,λ,ρ,和更小的 N c o n c e p t b g , D m e a n , D s t d N_{concept}^{bg},D_{mean},D_{std} Nconceptbg,Dmean,Dstd,这直接验证了假设1-3。
结论
该文章从对 DNN 的知识进行量化的角度来解释了知识蒸馏的成功。提出了三种类型的度量标准来验证分类场景中的三种假设,也就是相对于从原始数据进行学习,知识蒸馏可以确保 DNN 学习更多与任务相关的概念,学习更少与任务无关的概念,具有更高的学习速度,并以更少的弯路进行优化。
参考文献
[1]Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network[J]. arXiv preprint arXiv:1503.02531, 2015.
[2]Cheng X , Rao Z , Chen Y , et al. Explaining Knowledge Distillation by Quantifying the Knowledge[J]. 2020.
欢迎关注我们的微信公众号:MomodelAI
同时,欢迎使用 「Mo AI编程」 微信小程序
以及登录官网,了解更多信息:Mo 平台
Mo,发现意外,创造可能


















 991
991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









