







在CNN网络结构的进化过程中,出现过许多优秀的CNN网络,如:LeNet,AlexNet,VGG-Net,GoogLeNet,ResNet,DesNet.
提出年份
主要方向:网络加深,增强卷积模块

1、LeNet:
LeNet诞生于1998年,网络结构比较完整,包括卷积层、pooling层、全连接层。被认为是CNN的鼻祖。

输入32*32*1
卷积层3个:卷积的主要目的是使原始信号特征增强,并且降低噪音 卷积核 5*5
下采样层2个(池化):池化层的作用是降低网络训练参数及模型的过拟合程度。
全连接1个
输出层1个 10个类别 softmax /
2、AlexNet:
2012年提出AlexNet网络8层网络结构 5conv +5pooling +3fc+1000output class
输入:224x224x3
各层神经元的数量:253,440=>186,624=>64,896=>64,896=>43,264=>4096=>4096=>1000(ImageNet有1000个类
主要优势包括:
- 网络加深(5个卷积层+3个全连接层+1个softmax层);
- 解决过拟合(dropout,data augmentation,LRN(local resonce normalization));
- 多GPU运算。
- 非线性激活函数:ReLu 代替sigmoid,发现收敛SGD的收敛速度比sigmoid/tanh快很多
- 局部响应归一化层 local response normaliztion layer
- Overlapping Pooling 池化操作提取的是一小部分的代表性特征,减少冗余信息,如果stride=2 window=2 传统池化,更改为 stride2 window3 -》overlapping pooling 有重叠部分这种池化只能稍微减轻过拟合。
传统的激活函数一般是sigmoid和tanh两种饱和非线性函数,就训练时间来说,使用这些饱和的非线性函数会比使用非饱和的非线性函数ReLU,模型收敛需要更长的时间。而对于大型的数据集来说,更快的学习过程意味着可以节省更多的时间。除此之外,ReLU也引入了一定的稀疏性,在特征表示的范畴内,数据有一定的稀疏性,也就是说,有一部分的数据其实是冗余的。通过引入ReLU,可以模拟这种稀疏性,以最大近似的方式来保留数据的特征。
减轻过拟合:数据增强,dropout ,learning rate decay
- 数据增强的两种方式: (1)平移翻转,对称 从256x256的图片中随机截取224x224的部分出来
(2) 改变rgb的通道 的强度:给图像增加一些随机的光照,彩色变化,颜色抖动

这里的p和λ是RGB值3x3协方差矩阵的特征向量和特征值。α是均值为1标准差为0.1的高斯随机变量。
这么做的原因是利用了自然图片的一条重要性质:物体的鉴别特征并不会因为图片强度和颜色的变化而变化,也就是说,一定程度上改变图片的对比度、亮度、物体的颜色,并不会影响我们对物体的识别。在ImageNet上使用这个方法,降低了1%的top-1 error
- dropout :Dropout是一种Bagging的近似
Bagging定义k个不同的模型,从training set采样出k个不同的数据集,在第i个模型上用第i个数据集进行训练,最后综合k个模型的结果,获得最终的模型。但是需要的空间、时间都很大,在DNN中并不现实。
Dropout的目的是在指数级子网络的深度神经网络中近似Bagging。也就是说,在训练时,每次Dropout后,训练的网络是整个深度神经网络的其中一个子网络。在测试时,将dropout层取消,这样得到的前向传播结果其实就是若干个子网络前向传播综合结果的一种近似。
dropout,以0.5的概率将每个隐藏神经元的输出设置为0,以这种方式被抑制的神经元既不参与前向也不参与反向传播。每次输入一个样本,相当于该神经网络尝试一个新结构,但是这些结构之间的共享权值,因为神经元不能依赖其他的神经元而存在,所以这种技术降低了神经元复杂的互适应性,因此,网络需要被迫学习更加健壮的特征,这些特征结合其他神经元的一些不同随机子集时很有用,如果没有dropout网络会出现大量的过拟合,dropout使收敛所需的迭代次数增加一倍。
- learning rate decay 随着训练的进行,逐渐减小学习率
2012年,Imagenet比赛冠军的model——Alexnet [2](以第一作者alex命名)。caffe的model文件在这里。说实话,这个model的意义比后面那些model都大很多,首先它证明了CNN在复杂模型下的有效性,然后GPU实现使得训练在可接受的时间范围内得到结果,确实让CNN和GPU都大火了一把,顺便推动了有监督DL的发展。
模型结构见下图,别看只有寥寥八层(不算input层),但是它有60M以上的参数总量,事实上在参数量上比后面的网络都大
224*224*3 (rgb)
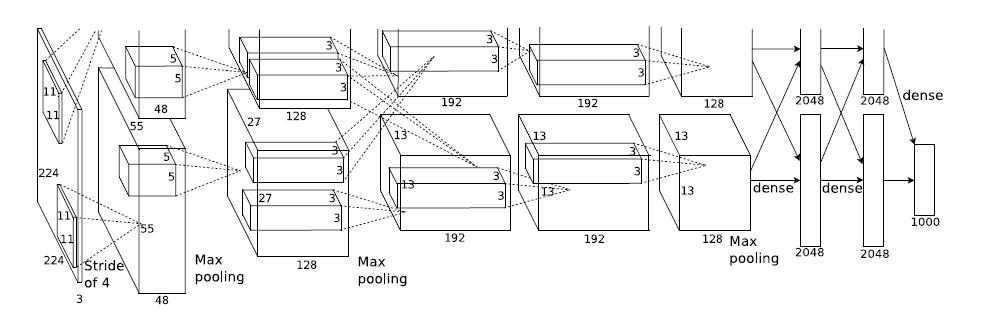

253,440=>186,624=>64,896=>64,896=>43,264=>4096=>4096=>1000(ImageNet有1000个类)
计算186624是怎么来的?27*27*256
一个feature map 计算

这个图有点点特殊的地方是卷积部分都是画成上下两块,意思是说吧这一层计算出来的feature map分开,但是前一层用到的数据要看连接的虚线,如图中input层之后的第一层第二层之间的虚线是分开的,是说二层上面的128map是由一层上面的48map计算的,下面同理;而第三层前面的虚线是完全交叉的,就是说每一个192map都是由前面的128+128=256map同时计算得到的。
Alexnet有一个特殊的计算层,LRN层,做的事是对当前层的输出结果做平滑处理。下面是我画的示意图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2282
2282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









