






kNN的英文全称是:k nearest neighbor,直译过来的意思就是k个最相近的邻居。所以,kNN的算法思想,简单而言,就是利用与待分类对象最相近的k个已知对象的特征,来决定待分类对象的特征。这种分类方法的思想简单,在实际分类效果中,表现也较为优异,是数据挖掘的分类领域中的一种入门算法。
下面以一个图例来具体说明kNN的具体思想:
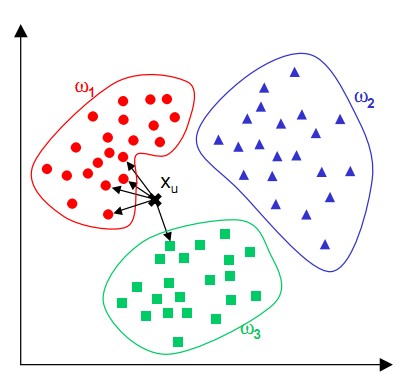
图片中有三种颜色表示的诸多实点,分别代表了三种不同的类别。中间的黑色叉号代表了待分类的对象。在对X进行分类的时候,首先需要计算X与所有已知对象之间的距离,然后选择这些距离中最小的k个对象,最后将这k个对象中所属类别最多的那个类,作为X的最终分类。
从图中可以看到,与X最相邻的5个对象中,有4个对象属于红色分类,有1个对象属于绿色分类,所以,我们将X的最终分类认定为红色类。
通过上述的实例的分析,对kNN算法的思想就有了更进一步的理解。接下来,我们把kNN算法的具体步骤进行一下总结:
1. 获取数据集,对数据进行预处理,以满足算法的格式需要
2. 分别计算待分类对象与所有数据集中的其他对象之间的距离
3. 设定k值得大小,并筛选距离最小的k个对象
4. 对k个对象进行统计,获得在k个对象中,各类别所拥有对象的个数
5. 将对象个数最多的类别,作为待分类对象的最终分类结果
基于上述算法的具体步骤,我们需要考虑以下若干问题:
- 算法的数据格式问题
- 对象之间的距离计算
- k值的选择
- 算法的计算量

















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









