








Pre:
例行吐槽知乎上传doc的格式错乱。。。
一、概述
1、概述
Topic:文本摘要
Baseline:Seq2Seq+Attention的文本生成模型
模型优化:抽取式+生成式 PGN网络及Coverage机制优化
数据源:电商平台上的营销文本,文本分为三部分
- 商品标题
- 商品参数
- 商品宣传图片中的宣传文案
- 选用回译、替换等方法进行小规模的数据增强
训练优化:Scheduled Sampling、Weight Tying
数据生成方式:Beam-Search及优化
数据输出:一段营销文案句子
模型评估:Rouge-1、Rouge-2、Rouge-L
参考论文:第一篇是最主要的,基本是复现
(1)ACL2017:《Get To The Point: Summarization with Pointer-Generator Networks》
(2)CiKM2018:《Multi-Source Pointer Network for Product Title Summarization》
(3)ACL2016:《Incorporating Copying Mechanism in Sequence-to-Sequence Learning》
2、原始数据展示:
1、商品标题

2、商品部分参数

3、营销图片中的文案(人为撰写的作为reference)

二、理论部分
这部分对概述中提到的所有相关知识做一个整理
1、Seq2Seq+Attention模型
Seq2Seq模型简单概括就是拼接两个RNN系的模型,分别称为模型的Encoder部分和Decoder部分
Encoder部分负责输入文本语义的编码,生成一个“浓缩输入语义”的语义空间meaning space
Decoder部分负责根据这个语义空间及每个time-step的Decoder输出,进行Attention机制并生成句子
从而实现在语义背景下从句子到句子的直接转换(Sequence to Sequence),而区别于以往单个单词单个单词的对照输出
模型架构如图所示:
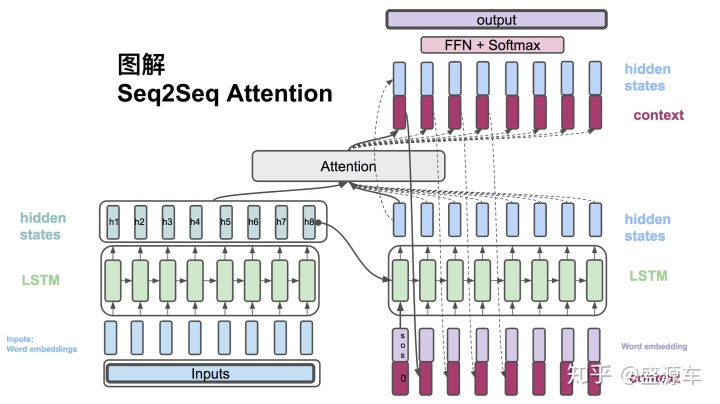
Encoder和Decoder都由RNN系的模型拼接而成,因此能够进行序列化的编码和输出,通常使用LSTM或Bi-LSTM来尽量减少梯度消失和梯度爆炸的问题,保证生成的效果更加的理想
Attention机制是Seq2Seq的核心,思路是根据Encoder的每个hidden state生成一个权重,之后经过归一化,得到一个新的权重,从而根据这个权重更新Meaning-Space的向量,之后与Decoder进行运算,输出结果
具体说来,每一部分的计算过程可以概述如下:
Encoder:接受的是每一个单词的embedding,和上一个时间点的hidden state。输出的是这个时间点的hidden state。
Attention:对Encoder的hidden state进行运算,得到中间的Attention层并以此形成Meaning Space
Decoder:
- 通过Decoder每一个time step 的hidden state与Encoder的hidden state计算一个权重,做归一化处理得到与每一个Encoder的hidden state的权重/得分,根据这个对应权重与hidden state拼接、加权平均得到Context Vector。
- 之后这个Context Vector与Decoder部分的前一个time step的hidden state拼接起来,计算得到当前步Decoder的输出,并作为下一个time step的输入,如此循环往复,直到输出最终结果。
- 需要注意的是,训练阶段Decoder部分每一步的输入用的是Reference文本,也即其实是一个“已知答案的假预测”,为的是使模型能够更快的拟合当前的训练样本,但在后期也应该使用真实的输出作为下一步的输入,这个地方在后续训练的优化部分会讲到
最后,阐述一下Attention的计算方式,也即Decoder中Context vector的计算方式,论文中给出的三种计算方式分别为:
(1)点乘(dot)
输入是:
- Encoder的所有hidden state(H),大小为(hidden dim, sequence length)
- Decoder在前一步的hidden state(S),大小为(hidden dim, 1)
计算:旋转H与S做点乘得到一个大小为(sequence length, 1)的分数score,做归一化得到权重α
输出:将H与α做点乘,也即加权平均得到context vector输出

(2)general方式
输入是:
- Encoder的所有hidden state(H),大小为(hidden dim1, sequence length)
- Decoder在前一步的hidden state(S),大小为(hidden dim2, 1)
- 这里的hidden dim1与hidden dim2并不一样
计算:旋转H(sequence length,hidden dim1)与Wa(hidden dim1,hidden dim2)做点乘,再和S做点乘,得到一个大小为(sequence length, 1)的分数score,做归一化得到权重α
输出:将H与α做点乘,也即加权平均得到context vector输出
(3)Concat方式
为了简便,这里直接贴三种方式的score计算公式,其余部分都一样:
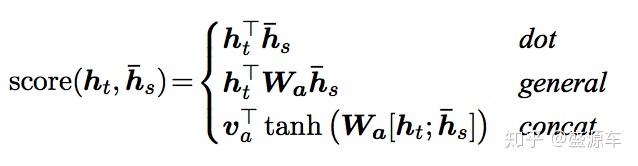
模型的优缺点:
想明白了模型的优缺点,才知道我们需要在这个baseline上如何做改动
最大的好处是部分解决了梯度的问题,传统RNN的信息包含在最后一个信息元中,而随着梯度消失、序列长度增加,很有可能最后一个信息元考虑不到序列前面的信息,而加了attention之后所有的信息都有可能被考虑到,因此更好
还有一个好处是增强了模型的可解释性,以往的RNN计算不太能够知道“错在哪里”,但由于加了attention,可以知道当前哪个权值是最大的,从而分析错误可能由他引起,或者能够发现当前attention权重最大的点不应该在当前的单词,也就能找到错误的根源
而模型的缺点则是在Attention里求score的方法,不难想到这种机制的前提假设最好要求Encoder中的不同的hidden state要相对独立(能够表示不同的信息是最好的),但由LSTM的性质又知道,hidden state是一定不是独立的,且一定考虑到了之前的hidden state,这由我们的实际经验也可以分析出来,因此这也带来了较大的冗余度
2、PGN网络及其要解决的问题
回顾Seq2Seq网络我们可以发现,不管是哪种Attention计算方式,最终的目的都是得到一个概率,选择概率最大的wordid,然后去词表中找单词,实现index2word,最终输出单词
但是这种方式在实际使用的过程中存在着三个缺点:
- 无法生成OOV单词,只能生成词汇表中的词
- 会产生错误的事实,比如姓名之间错误
- 自我重复,即聚焦于某些公共Attention很大的单词,从而重复输出
PGN网络主要解决的是第一个问题,也即使用一种混合的指针生成网络,他能够从源端复制单词,也能够从词表当中去生成词语。前者称为抽取式,后者称为生成式。
这里重点讲这种抽取式网络,其实就是在做attention时,分别对每一个Encoder的hidden_state做attention(这里的计算不变,区别在于对单点计算,不累加),之后选取attention_weight值最大的那个作为当前Decoder节点的输出,从而使得输出集合是输入集合的子集
主要与生成式网络的区别在于:
- Decoder的输出不再是遍历词表
- 用attention_weight作为评判标准
- 输出一定是输入的子集,即这种方式下输出词汇一定在输入序列的集合中,在一定程度上避免了OOV的问题
- 以往的生成式模型:自由、灵活但不是很可控
- 抽取式网络相对可控,确切的说是将信息来源限制在输入的信息范围中
接下来我们结合PGN的几篇论文具体的阐述他的实现机制
1、ACL2017:《Get To The Point: Summarization with Pointer-Generator Networks》
这篇也是本文最主要参考并做了复现的论文
论文使用的是两个模型叠加起来的PGN:
- 第一个还是传统的Seq2Seq模型,基于的是全局的词表
- 第二个是Pointer-Network,基于的是source-word这个小表
令最终的输出概率为二者概率的加权平均,并能够做动态调整,公式如下:
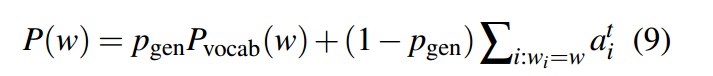
Attention_weight求和表示的是对一个句子中相同单词的attention进行累加
具体这个P_gen的计算公式是:
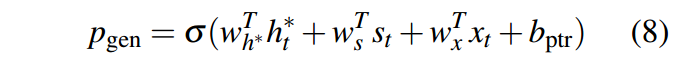
其中的四个变量分别是:h_t:context vector、s_t:decoder的hidden state、x_t:上一步的输出,b:偏置
因此,模型的整体架构为:
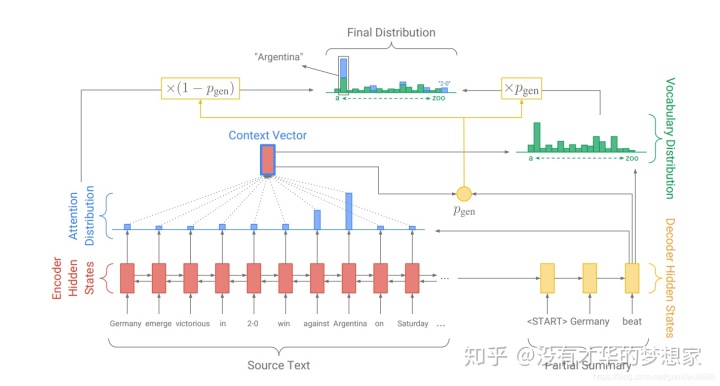
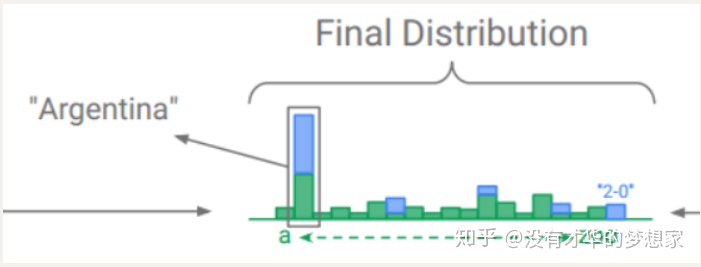
这里还可以看到final distribution中部分点是没有蓝色的,这是因为本来source_text就是整个词表的子集罢了,当然只有部分是有概率的,只需要将有的相加就可以了
对于OOV的问题,就像Souce-Text中的2:0,这个最后就只有来自于Pointer-Network的概率,没有来自于传统Seq2Seq的
这里也允许有多个UNK,因为我们在Pointer-Network中肯定是知道的,在预处理时单独把它记录出来即可
2、CiKM2018:《Multi-Source Pointer Network for Product Title Summarization》
这是一篇阿里的团队写的文本摘要任务的文章,具体场景是生成商品的标题摘要信息
这篇文章的PGN是将两个抽取式网络拼接起来,从而生成摘要,从输出是输入的子集这一性质我们也很容易想到这个应用
网络的结构:
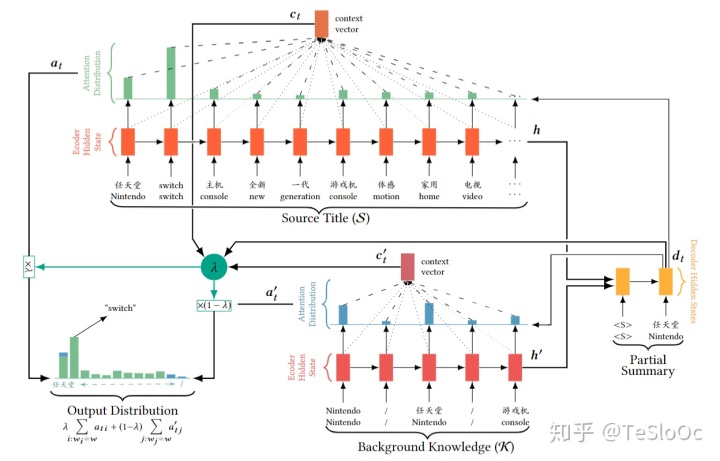
可以看到分别对两个LSTM网络进行抽取,一个的信息S是商品的标题,另一个K是商品的背景信息、
3、ACL2016:《Incorporating Copying Mechanism in Sequence-to-Sequence Learning》
这是一篇港大和华为诺亚方舟实验室生产的论文
本文的模型通过借鉴人类在处理难理解的文字时采用的死记硬背的方法,提出了COPYNET。将拷贝模式融入到了Seq2Seq模型中,将传统的生成模式和拷贝模式混合起来构建了新的模型,非常好地解决了OOV问题。
Decoder部分越来越复杂,从而取得一个比较好的效果
关于这篇文章的一个容易想到的场景是在类似于对话机器人的场景中,直接复制重要信息,如:
---“hello,我是xxx”
---“xxx你好,我是Siri”(这里的xxx就是可以直接复制粘贴的对象)
模型CopyNet的架构如下:
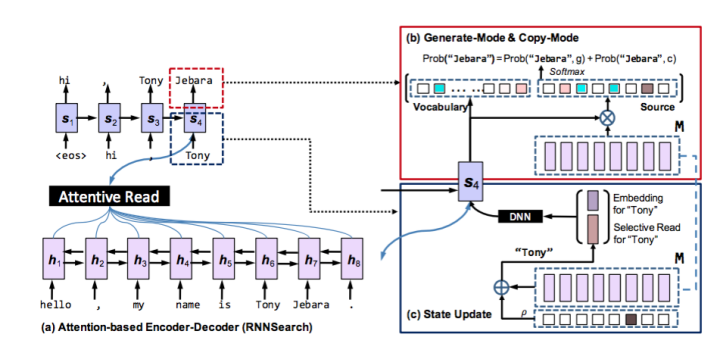
文章中将所有的单词分为以下四种分类:
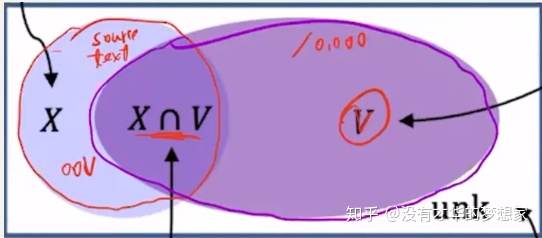
并根据这四种情况来判定最终生成单词的概率,具体的公式如下:
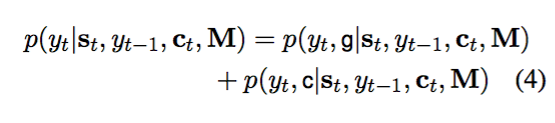
g是generate生成模式,c是copy拷贝模式,两种模式的概率计算公式由单词分布在四种情况之下哪一种不同
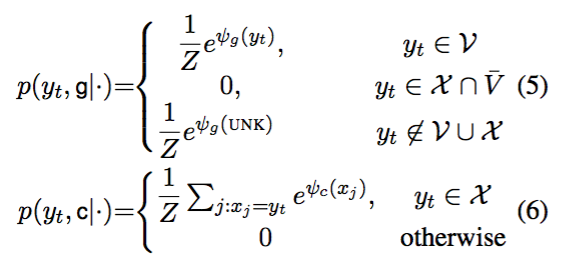
将上图的公式放到第一张图里可能会更加直观:
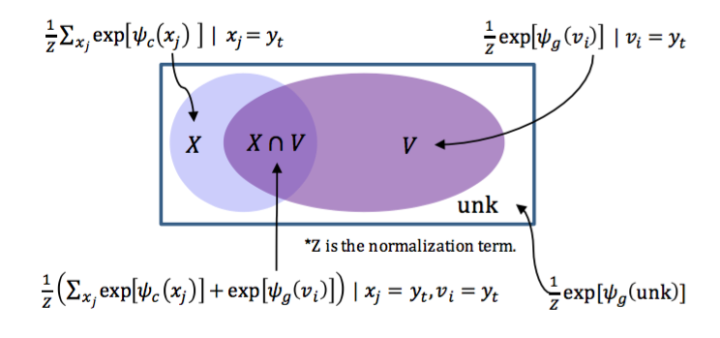
生成模式和拷贝模式的打分机制不同,分别为:
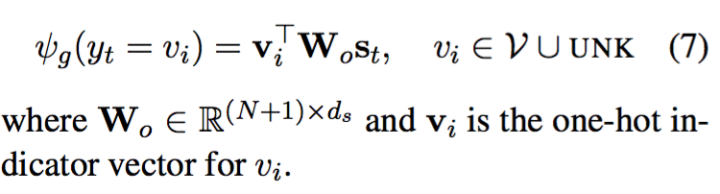
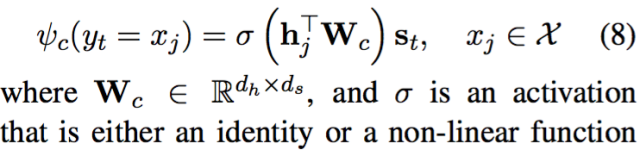
并且对Decoder部分的生成机制加了一个触发条件,这也是这篇论文的核心创新点,也即:
如果上一个Decoder的输出出现在了Source-text中,即源自于当前文本,则计算一个权重:
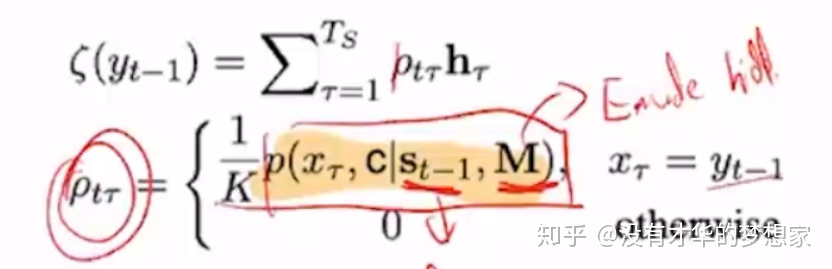
然后,在计算下一个Decoder的输出时,不仅仅要考虑上一个输出,如“Tony”,还需要再拼接一个加权平均,这个加权平均的计算公式如上,需要再考虑source文本的信息
即根据这个词分布的情况人为的规定(与上一篇文章的最大的区别,不是动态调整)应该来自于哪个概率,并且根据触发条件计算一个新的加权向量
3、文本生成任务的评价指标BLEU与Rouge
在机器翻译和文本生成这一块,BLEU(2002)和ROUGE(2003)是两种最为常见的评估指标,下面分别介绍
(1)BLEU
BLEU 的全称是 Bilingual evaluation understudy,BLEU 的分数取值范围是 0~1,分数越接近1,说明翻译的质量越高。BLEU 主要是基于精确率(Precision)的,下面是 BLEU 的整体公式。

BLEU需要计算模型在n-gram下的精确度,公式中的Pn指的就是在n-gram下的精确度
BP是一个惩罚因子,主要针对的是Seq2Seq倾向于生成短句的问题,因此做了这样一个短句惩罚
根据语义的相关特性我们可以得出这样一个结论:BLEU的1-gram表示的是模型翻译终于原文的程度,而其他的n-gram表示的是翻译的流畅程度
关于计算n-gram的方式可以参考这个例子:
机器翻译生成的译文: a cat is on the table
参考译文Reference: there is a cat on the table
若计算2-gram,则需要统计所有机器翻译的2-gram对出现在参考译文中的概率,也即:

但是这样的计算方式在一些场景下显然会有问题,尤其是机器翻译出现大量重复的场景下,如:
机器翻译生成的译文C: there there there there there
参考译文S:there is a cat on the table
这样的1-gram计算出来是1,显然是不对的,因此常常对BLEU的n-gram进行修正,公式如下:

修正后的公式中的Pn:分母就是机器翻译语句的长度,
分子就是统计切分后的n-gram在机器翻译语句中的次数num1和在单一参考翻译语句中的出现最大次数num2的较小值,即min(num1,num2)
(2)Rouge
ROUGE 指标的全称是 (Recall-Oriented Understudy for Gisting Ev
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









