







1、数据来源
xAPI-Edu-Data:https://tianchi.aliyun.com/dataset/dataDetail?dataId=23563
该数据来源于阿里云天池,数据集包含了学生成绩相关的17个变量。数据集的大小为:480条。
2、部分字段含义及数据量
- class:成绩
- gender:性别
- Topic:学科
- SectionID:班级
- NationalITy:国籍
- PlaceofBirth:出生地
3、数据清洗
#调用数据包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings('ignore')#加载数据集
data=pd.read_csv('xAPI-Edu-Data.csv')
data.head() #展示前5列数据
#查看数据集的形状
data.shape
#查看各个字段是否有缺失值
print(data.isnull().sum())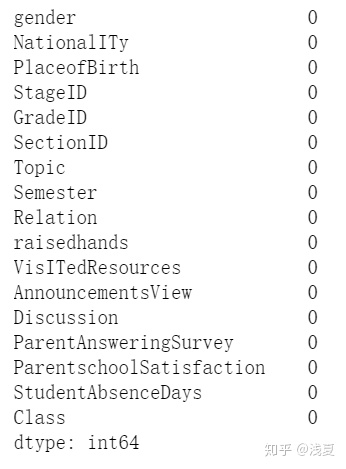
#检查每个属性的特征类型
print(data.dtypes)
4、对数据集进行描述性统计分析
#对数据集进行简单的统计分析
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1512
1512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









