







学生分数预测
标签:线性回归
- 数据准备
#1.创建数据集:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
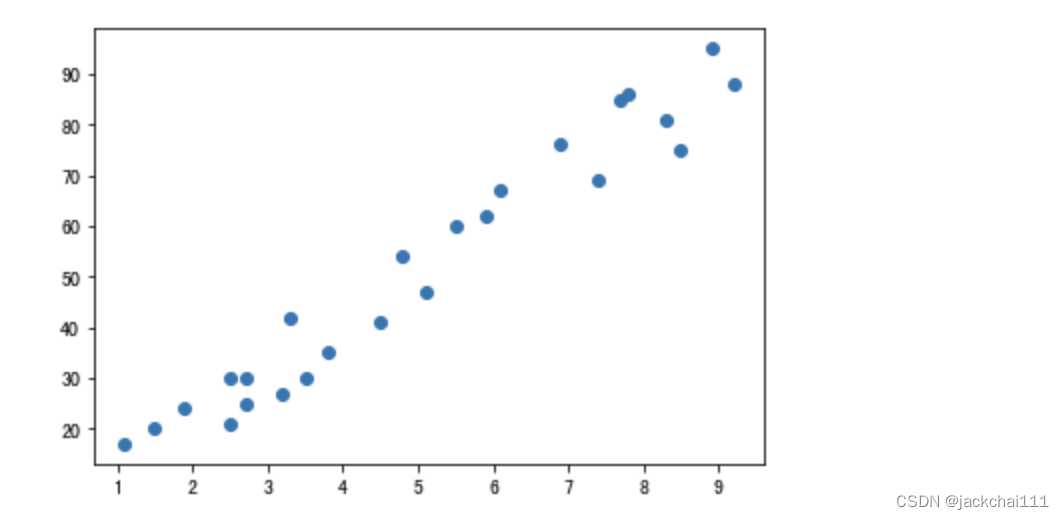
predata={'hour':[2.5,5.1,3.2,8.5,3.5,1.5,9.2,5.5,8.3,2.7,7.7,5.9,4.5,3.3,1.1,8.9,2.5,1.9,6.1,7.4,2.7,4.8,3.8,6.9,7.8],
'score':[21,47,27,75,30,20,88,60,81,25,85,62,41,42,17,95,30,24,67,69,30,54,35,76,86]}
mydata=np.asarray(predata) #字典对象转换为numpy对象
plt.scatter(predata['hour'],predata['score'])
运行结果:数据分布情况
x轴代表时间,y轴代表分数
- 数据清洗
常见的数据清洗操作有:重复观测检查、缺省值处理和异常点处理(这里数据比较少就不进行这些操作了)
corr()函数求时间和分数的相关系数,这里面发现结果为0.976191十分接近1,说明时间和分数正线性相关性很强 - 数据预处理分割特征值和目标值
- 数据预处理分割特征值和目标值
df=pd.DataFrame(data=predata)
X=df.iloc[:,:1] #特征值
Y=df.iloc[:,-1:] #目标值
分割训练集和测试集,这里训练集和测试集是7/3开
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,Y,train_size=0.3,random_state=42)
- 模型训练
这里使用的是线性回归的训练模型
from sklearn.linear_model import LinearRegression
Model=LinearRegression()
Model.fit(X_train,y_train) #开始拟合数据
这两个参数是线性回归模型里面的参数,这里只有两个说明拟合结果为一条直线,coef为直线的斜率,另一个为截距
- 查看结果
查看预测值和真实值之间的误差
import seaborn as sns
y_predict=Model.predict(X_test)
sns.displot(y_predict-y_test,kind="kde")

- 模型评估
from sklearn import metrics
print('MAE:', metrics.mean_absolute_error(y_test, y_predict))
print('MSE:', metrics.mean_squared_error(y_test, y_predict))
print('RMSE:', np.sqrt(metrics.mean_squared_error(y_test, y_predict)))
print("Model Accuracy: ",Model.score(X_train,y_train))

- 使用该模型预测6个小时的学习时间得到的分数
prediction=Model.predict([[6]])
print(prediction)
print("\nBy Using mathematical equation:",Model.coef_*5.9+Model.intercept_)
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









