







目录
1、概述
已经了解了Word2vec,怎么应用于推荐场景中,形成item2vec呢?【深度学习】word2vec(上)
在Item2Vec中,一个物品集合被视作nlp中的一个段落,物品集合的基本元素-物品等价于段落中的单词。因此在论文中,一个音乐物品集合是用户对某歌手歌曲的播放行为,一个商品集合是一个订单中包含的所有商品。
参考word2vec 学习item的向量表示,这个方法可以在没有user信息的时候,推理item-item的关系。

Item2vec中把用户浏览的商品集合等价于word2vec中的word的序列,即句子(忽略了商品序列空间信息spatial information) 。出现在同一个集合的商品对视为 positive。利用SGD方法学习的目标函数max,得到每个商品的embedding representation,商品之间两两计算cosine相似度即为商品的相似度。
图片中的正样本、负样本是“
CBOW结构首先会取中心词的 2c 个上下文词,然后用这些上下文词的one-hot编码向量乘以 权重再求和”,其中的中心词是正样本,上下文词是负样本。
2、从word2vec到item2vec
在word2vec诞生之后,embedding的思想迅速从NLP领域扩散到几乎所有机器学习的领域,我们既然可以对一个序列中的词进行embedding,那自然可以对用户购买序列中的一个商品,用户观看序列中的一个电影进行embedding。而广告、推荐、搜索等领域用户数据的稀疏性几乎必然要求在构建DNN之前对user和item进行embedding后才能进行有效的训练。
具体来讲,如果item存在于一个序列中,item2vec的方法与word2vec没有任何区别。而如果我们摒弃序列中item的空间关系,在原来的目标函数基础上,自然是不存在时间窗口的概念了,取而代之的是item set中两两之间的条件概率。
但embedding的应用又远不止于此,事实上,由于我们也可以把输出矩阵的列向量当作item embedding,这大大解放了我们可以用复杂网络生成embedding的能力。读过我专栏上一篇文章 YouTube深度学习推荐系统的十大工程问题 的同学肯定知道,YouTube在serve其candidate generation model的时候,只将最后softmax层的输出矩阵的列向量当作item embedding vector,而将softmax之前一层的值当作user embedding vector。在线上serving时不用部署整个模型,而是只存储user vector和item vector,再用最近邻索引进行快速搜索,这无疑是非常实用的embedding工程经验,也证明了我们可以用复杂网络生成user和item的embedding。(youtube DNN需要再review)

图:YouTube的user和video embedding网络
原文的一些思考
- 为什么说深度学习的特点不适合处理特征过于稀疏的样本?
- 我们能把输出矩阵中的权重向量当作词向量吗?
- 为什么在计算word similarity的时候,我们要用cosine distance,我们能够用其他距离吗?
- 在word2vec的目标函数中,两个词
的词向量
其实分别来自输入权重矩阵和输出权重矩阵,那么在实际使用时,我们需要分别存储输入矩阵和输出矩阵吗?还是直接用输入矩阵当作word2vec计算similarity就好了?
- 隐层的激活函数是什么?是sigmoid吗?
3、item2vec损失函数

4、item2vec实现电影相关推荐
知识:
- word2vec:输入(doc, words),得到 word embedding
- item2vec:输入(userid, itemids),得到 item embedding
说明:
- 使用标题/内容的分词embedding作推荐,属于内容相似推荐
- 使用行为列表(例如播放,点击,浏览等)embedding作推荐,属于行为相关推荐,效果比内容相似推荐更好
延伸:
- 把 word embedding 进行加和、平均,就得到了document embedding;
- 把 item embedding 进行加和、平均,就得到了user embedding;
准备数据
import pandas as pd
df = pd.read_csv("./datas/ml-latest-small/ratings.csv")
df["rating"].mean()
# 只取平均分以上的数据,作为喜欢的列表
df = df[df["rating"] > df["rating"].mean()].copy()
df.head()
# 聚合得到userId,movieId列表
df_group = df.groupby(['userId'])['movieId'].apply(lambda x: ' '.join([str(m) for m in x])).reset_index()
df_group.head()
df_group.to_csv("./datas/movielens_uid_movieids.csv", index=False) 

使用pyspark训练item2vec
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("PySpark Item2vec") \
.getOrCreate()
sc = spark.sparkContext
df = spark.read.csv("xxx/datas/movielens_uid_movieids.csv", header=True)
df.show(5)
from pyspark.sql import functions as F
from pyspark.sql import types as T
# 把非常的字符串格式变成LIST形式
df = df.withColumn('movie_ids', F.split(df.movieId, " "))
实现word2vec的训练与转换
# https://spark.apache.org/docs/2.4.6/ml-features.html#word2vec
from pyspark.ml.feature import Word2Vec
word2Vec = Word2Vec(
vectorSize=5,
minCount=0,
inputCol="movie_ids",
outputCol="movie_2vec")
model = word2Vec.fit(df)
# 不计算每个user的embedding,而是计算item的embedding
model.getVectors().show(3, truncate=False)
model.getVectors().select("word", "vector") \
.toPandas() \
.to_csv('./datas/movielens_movie_embedding.csv', index=False)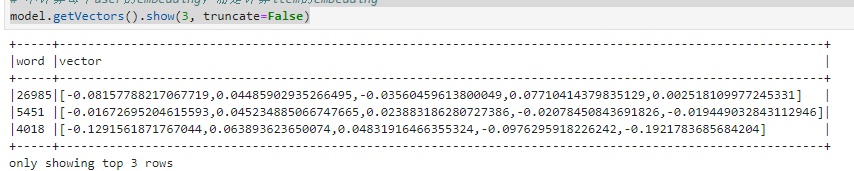
对于给定电影计算最相似的10个
df_embedding = pd.read_csv("./datas/movielens_movie_embedding.csv")
df_embedding.head(3)
df_movie = pd.read_csv("./datas/ml-latest-small/movies.csv")
df_movie.head()
df_merge = pd.merge(left=df_embedding,
right=df_movie,
left_on="word",
right_on="movieId")
df_merge.head()

import numpy as np
import json
df_merge["vector"] = df_merge["vector"].map(lambda x : np.array(json.loads(x)))
# 随便挑选一个电影:4018 What Women Want (2000)
movie_id = 4018
df_merge.loc[df_merge["movieId"]==movie_id]
movie_embedding = df_merge.loc[df_merge["movieId"]==movie_id, "vector"].iloc[0]
movie_embedding
# 余弦相似度
from scipy.spatial import distance
df_merge["sim_value"] = df_merge["vector"].map(lambda x : 1 - distance.cosine(movie_embedding, x))
df_merge[["movieId", "title", "genres", "sim_value"]].head(3)
# 按相似度降序排列,查询前10条
df_merge.sort_values(by="sim_value", ascending=False)[["movieId", "title", "genres", "sim_value"]].head(10)

参考:















 3056
3056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









