







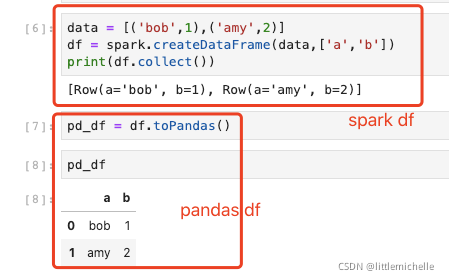
1、spark 转 pandas
pandas dataframe = spark dataframe.toPandas()
注意事项
toPandas()因为是单机处理数据,所以不能处理大量数据。
toPandas 返回的数据归根结底还是缓存在 driver 的内存中的,不建议返回过大的数据。
在spark dataFrame 中使用 pandas dataframe_偷闲小苑-CSDN博客
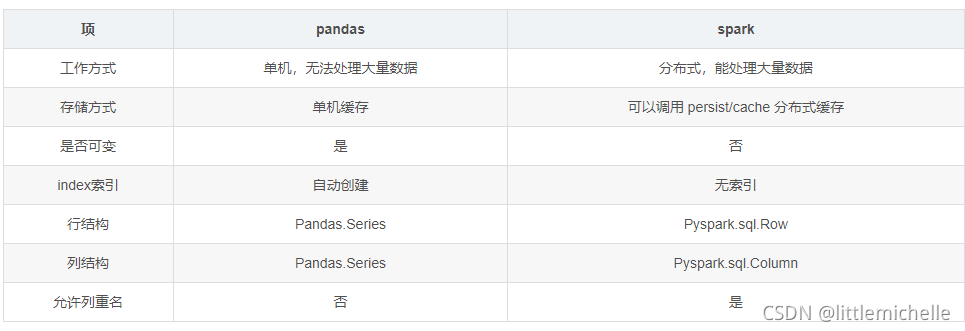
pandas dataFrame 无法支持大量数据的计算,可以尝试 spark df 来解决这个问题。
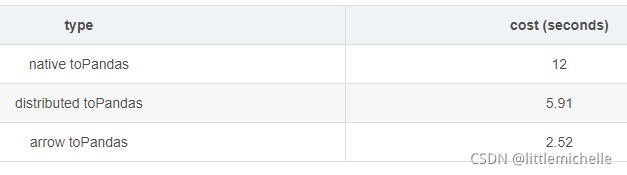
原生toPandas()
df.toPandas()分布式toPandas()
pd_df = toPandas(sp_df)优化代码如下:
import pandas as pd
def _map_to_pandas(rdds):
return [pd.DataFrame(list(rdds))]
def toPandas(df, n_partitions=None):
if n_partitions is not None: df = df.repartition(n_partitions)
df_pand = df.rdd.mapPartitions(_map_to_pandas).collect()
df_pand = pd.concat(df_pand)
df_pand.columns = df.columns
return df_pand
# 98列,22W行,类型 array/string/Long/Int,分区 200
df = spark.sql("...").sample(False,0.002)
df.cache()
df.count()
# 原生的 toPandas 方法
%timeit df.toPandas()
# 分布式的 toPandas
%timeit toPandas(df)
#使用 apache arrow,spark 版本2.3以上
spark.sql("set spark.sql.execution.arrow.enabled=true")
%timeit df.toPandas()
tips: 如果一个分区数据量过大将会导致 executor oom。

















 2455
2455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









